PID: Prompt-Independent Data Protection Against Latent Diffusion Models

0
Sign in to get full access
Overview
- This paper proposes a method called "PID" (Prompt-Independent Data Protection) to protect data from being reconstructed by latent diffusion models.
- Latent diffusion models are a type of machine learning model that can generate new images or manipulate existing ones based on text prompts.
- The key idea behind PID is to add a special layer to the latent diffusion model that prevents the model from fully reconstructing the original training data, even if the model is given the right text prompt.
Plain English Explanation
The paper introduces a new technique called "PID" (Prompt-Independent Data Protection) that aims to protect the privacy of the training data used to create latent diffusion models. Latent diffusion models are a type of AI system that can generate or manipulate images based on text prompts. The problem is that these models can potentially reconstruct the original training data, which may contain private or sensitive information.
PID works by adding an extra layer to the latent diffusion model that prevents it from fully reconstructing the original training data, even if the right text prompt is provided. This helps to preserve the privacy of the training data while still allowing the model to generate and manipulate images in a useful way. The key insight is that the model can still perform its core functions, but with an added safeguard to protect the underlying data.
The authors demonstrate that PID is effective at preventing data reconstruction without significantly impacting the model's performance on image generation and manipulation tasks. This is an important step forward in balancing the powerful capabilities of latent diffusion models with the need to protect sensitive information.
Technical Explanation
The paper proposes a method called "PID" (Prompt-Independent Data Protection) to protect the training data used to create latent diffusion models from being reconstructed. Latent diffusion models are a type of machine learning model that can generate new images or manipulate existing ones based on text prompts. However, these models can potentially reconstruct the original training data, which may contain private or sensitive information.
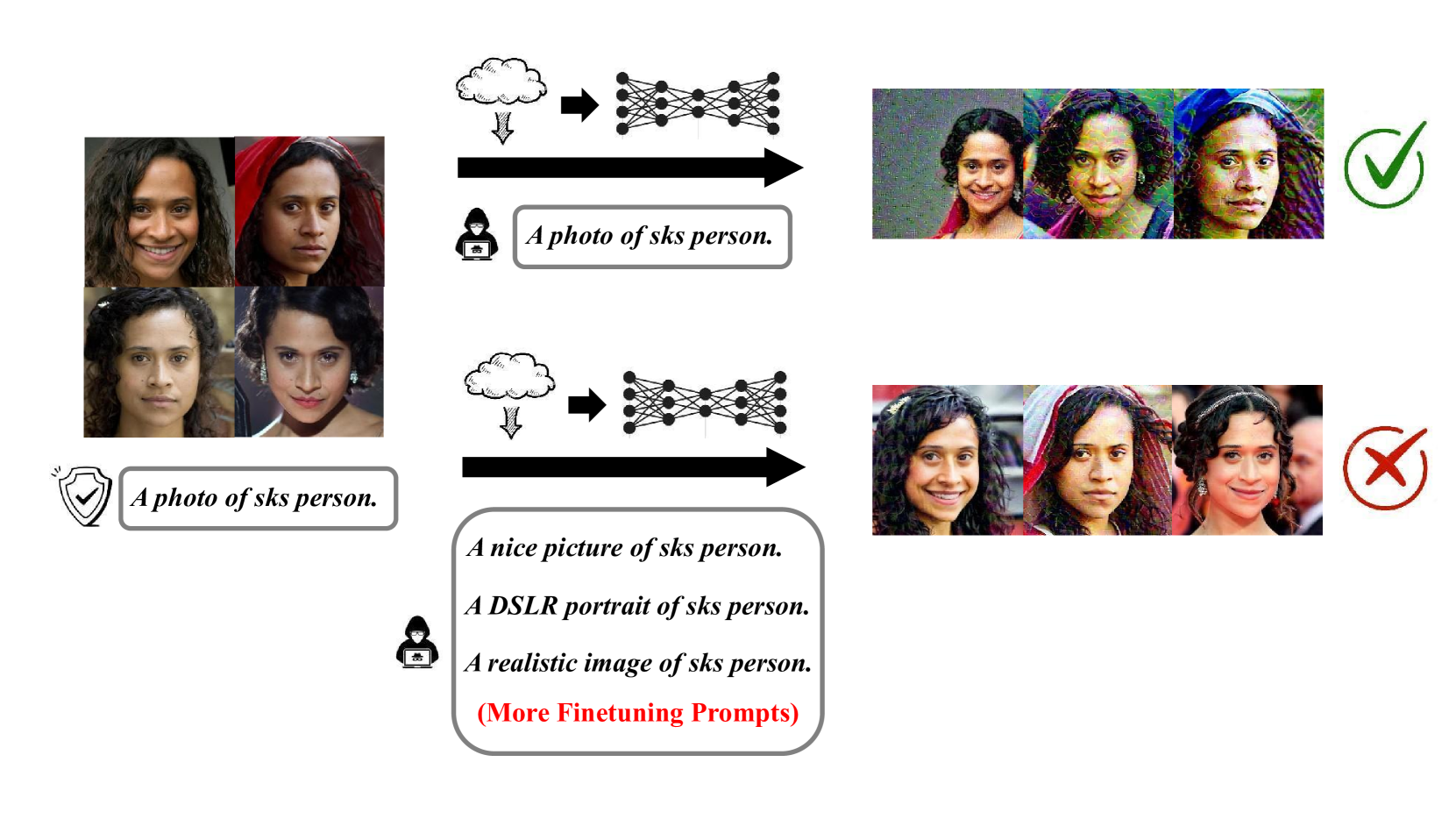
PID works by adding an extra layer to the latent diffusion model that prevents it from fully reconstructing the original training data, even if the right text prompt is provided. This is achieved by introducing a "prompt-independent data protection" (PID) module that is trained to learn a prompt-independent representation of the data. The PID module is trained jointly with the rest of the latent diffusion model, but its objective is to minimize the mutual information between the input data and the model's latent representations.
The authors demonstrate the effectiveness of PID using experiments on various datasets and tasks, including image generation, manipulation, and reconstruction. They show that PID can significantly reduce the ability of the latent diffusion model to reconstruct the original training data while maintaining its performance on the core tasks.
Critical Analysis
The paper presents a promising approach for protecting the privacy of training data used in latent diffusion models. The PID method is a novel and well-designed solution that effectively balances the powerful capabilities of these models with the need to safeguard sensitive information.
One potential limitation of the PID approach is that it may slightly reduce the model's performance on certain tasks, such as image manipulation, compared to a standard latent diffusion model. The authors acknowledge this trade-off and suggest that the degree of performance impact can be adjusted based on the specific requirements of the application.
Additionally, the paper does not address the potential for adversarial attacks or other techniques that could be used to circumvent the PID protection. Further research may be needed to understand the robustness of the PID method against more sophisticated attacks.
Overall, the PID method represents an important contribution to the field of machine learning, particularly in the context of protecting the privacy of training data. The authors have provided a well-designed and empirically validated solution that could have significant implications for the responsible development and deployment of latent diffusion models.
Conclusion
The PID (Prompt-Independent Data Protection) method proposed in this paper is a significant step forward in protecting the privacy of training data used to create latent diffusion models. By introducing an additional module that learns a prompt-independent representation of the data, PID effectively prevents the model from fully reconstructing the original training data while maintaining its core functionality for tasks like image generation and manipulation.
This work highlights the importance of addressing privacy and data protection concerns as these powerful AI models become more widely adopted. The PID method represents a promising approach that could help unlock the benefits of latent diffusion models while ensuring the responsible handling of sensitive information. As the field of machine learning continues to advance, continued research and innovation in this area will be crucial for building trustworthy and ethical AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PID: Prompt-Independent Data Protection Against Latent Diffusion Models
Ang Li, Yichuan Mo, Mingjie Li, Yisen Wang
The few-shot fine-tuning of Latent Diffusion Models (LDMs) has enabled them to grasp new concepts from a limited number of images. However, given the vast amount of personal images accessible online, this capability raises critical concerns about civil privacy. While several previous defense methods have been developed to prevent such misuse of LDMs, they typically assume that the textual prompts used by data protectors exactly match those employed by data exploiters. In this paper, we first empirically demonstrate that breaking this assumption, i.e., in cases where discrepancies exist between the textual conditions used by protectors and exploiters, could substantially reduce the effectiveness of these defenses. Furthermore, considering the visual encoder's independence from textual prompts, we delve into the visual encoder and thoroughly investigate how manipulating the visual encoder affects the few-shot fine-tuning process of LDMs. Drawing on these insights, we propose a simple yet effective method called textbf{Prompt-Independent Defense (PID)} to safeguard privacy against LDMs. We show that PID can act as a strong privacy shield on its own while requiring significantly less computational power. We believe our studies, along with the comprehensive understanding and new defense method, provide a notable advance toward reliable data protection against LDMs.
Read more6/24/2024
🔮
0
Differentially Private Latent Diffusion Models
Michael F. Liu, Saiyue Lyu, Margarita Vinaroz, Mijung Park
Diffusion models (DMs) are one of the most widely used generative models for producing high quality images. However, a flurry of recent papers points out that DMs are least private forms of image generators, by extracting a significant number of near-identical replicas of training images from DMs. Existing privacy-enhancing techniques for DMs, unfortunately, do not provide a good privacy-utility tradeoff. In this paper, we aim to improve the current state of DMs with differential privacy (DP) by adopting the textit{Latent} Diffusion Models (LDMs). LDMs are equipped with powerful pre-trained autoencoders that map the high-dimensional pixels into lower-dimensional latent representations, in which DMs are trained, yielding a more efficient and fast training of DMs. Rather than fine-tuning the entire LDMs, we fine-tune only the $textit{attention}$ modules of LDMs with DP-SGD, reducing the number of trainable parameters by roughly $90%$ and achieving a better privacy-accuracy trade-off. Our approach allows us to generate realistic, high-dimensional images (256x256) conditioned on text prompts with DP guarantees, which, to the best of our knowledge, has not been attempted before. Our approach provides a promising direction for training more powerful, yet training-efficient differentially private DMs, producing high-quality DP images. Our code is available at https://anonymous.4open.science/r/DP-LDM-4525.
Read more7/22/2024

0
Exploring the Role of Large Language Models in Prompt Encoding for Diffusion Models
Bingqi Ma, Zhuofan Zong, Guanglu Song, Hongsheng Li, Yu Liu
Large language models (LLMs) based on decoder-only transformers have demonstrated superior text understanding capabilities compared to CLIP and T5-series models. However, the paradigm for utilizing current advanced LLMs in text-to-image diffusion models remains to be explored. We observed an unusual phenomenon: directly using a large language model as the prompt encoder significantly degrades the prompt-following ability in image generation. We identified two main obstacles behind this issue. One is the misalignment between the next token prediction training in LLM and the requirement for discriminative prompt features in diffusion models. The other is the intrinsic positional bias introduced by the decoder-only architecture. To deal with this issue, we propose a novel framework to fully harness the capabilities of LLMs. Through the carefully designed usage guidance, we effectively enhance the text representation capability for prompt encoding and eliminate its inherent positional bias. This allows us to integrate state-of-the-art LLMs into the text-to-image generation model flexibly. Furthermore, we also provide an effective manner to fuse multiple LLMs into our framework. Considering the excellent performance and scaling capabilities demonstrated by the transformer architecture, we further design an LLM-Infused Diffusion Transformer (LI-DiT) based on the framework. We conduct extensive experiments to validate LI-DiT across model size and data size. Benefiting from the inherent ability of the LLMs and our innovative designs, the prompt understanding performance of LI-DiT easily surpasses state-of-the-art open-source models as well as mainstream closed-source commercial models including Stable Diffusion 3, DALL-E 3, and Midjourney V6. The powerful LI-DiT-10B will be available through the online platform and API after further optimization and security checks.
Read more6/24/2024

0
DiffusionPID: Interpreting Diffusion via Partial Information Decomposition
Shaurya Dewan, Rushikesh Zawar, Prakanshul Saxena, Yingshan Chang, Andrew Luo, Yonatan Bisk
Text-to-image diffusion models have made significant progress in generating naturalistic images from textual inputs, and demonstrate the capacity to learn and represent complex visual-semantic relationships. While these diffusion models have achieved remarkable success, the underlying mechanisms driving their performance are not yet fully accounted for, with many unanswered questions surrounding what they learn, how they represent visual-semantic relationships, and why they sometimes fail to generalize. Our work presents Diffusion Partial Information Decomposition (DiffusionPID), a novel technique that applies information-theoretic principles to decompose the input text prompt into its elementary components, enabling a detailed examination of how individual tokens and their interactions shape the generated image. We introduce a formal approach to analyze the uniqueness, redundancy, and synergy terms by applying PID to the denoising model at both the image and pixel level. This approach enables us to characterize how individual tokens and their interactions affect the model output. We first present a fine-grained analysis of characteristics utilized by the model to uniquely localize specific concepts, we then apply our approach in bias analysis and show it can recover gender and ethnicity biases. Finally, we use our method to visually characterize word ambiguity and similarity from the model's perspective and illustrate the efficacy of our method for prompt intervention. Our results show that PID is a potent tool for evaluating and diagnosing text-to-image diffusion models.
Read more6/14/2024