Pointsoup: High-Performance and Extremely Low-Decoding-Latency Learned Geometry Codec for Large-Scale Point Cloud Scenes

0

Sign in to get full access
Overview
• This paper introduces Pointsoup, a high-performance and extremely low-decoding-latency learned geometry codec for large-scale point cloud scenes.
• Pointsoup achieves state-of-the-art compression ratios while maintaining high-quality reconstruction and enabling real-time decoding, making it suitable for applications like virtual/augmented reality and autonomous driving.
Plain English Explanation
Pointsoup is a new technology that can efficiently compress and decompress large 3D point cloud data. Point clouds are used to represent 3D shapes and environments in many applications, like virtual reality, self-driving cars, and 3D mapping. However, transmitting and storing large point cloud datasets can be challenging due to their massive size.
Pointsoup solves this problem by using a machine learning-based approach to compress the 3D geometry of the point cloud while preserving its quality. This allows the compressed data to be transmitted and decompressed much faster than previous methods, enabling real-time applications like immersive virtual experiences and autonomous vehicle navigation.
The key innovations in Pointsoup include [link to relevant research papers] efficient data encoding, adaptive bit allocation, and a neural network architecture designed for low-latency decoding. These techniques allow Pointsoup to achieve state-of-the-art compression ratios while maintaining high-fidelity reconstruction of the original point cloud.
Technical Explanation
Pointsoup uses a learned codec approach to compress the geometry of large-scale point cloud scenes. It builds on recent advancements in [link to "Efficient Generic Point Model for Lossless Point Cloud Compression"] and [link to "AVS-Net: Point Sampling with Adaptive Voxel Size"] to develop a highly efficient and low-latency encoding and decoding pipeline.
The core of Pointsoup is a neural network architecture that learns to represent the 3D geometry of the point cloud in a compact way. This involves encoding the point positions, normals, and other attributes into a compressed bitstream that can be transmitted or stored. On the decoding side, another neural network is used to quickly reconstruct the original point cloud from the compressed data.
Pointsoup also incorporates techniques like [link to "Geometrically Driven Aggregation for Zero-Shot 3D Point Cloud Segmentation"] adaptive bit allocation and [link to "SparseOCC: Rethinking Sparse Latent Representation for Vision-Based 3D Point Cloud Reconstruction"] sparse latent representations to further improve compression efficiency and decoding speed. These innovations enable Pointsoup to outperform previous state-of-the-art point cloud codecs in both compression ratio and reconstruction quality.
Critical Analysis
The authors thoroughly evaluate Pointsoup's performance on a variety of large-scale point cloud datasets and compare it to other leading codecs. The results demonstrate Pointsoup's ability to achieve high compression ratios while maintaining low decoding latency, making it suitable for real-time applications.
However, the paper does not address potential limitations of the approach, such as its sensitivity to noise or ability to handle point clouds with varying densities. Additionally, the authors do not discuss the computational complexity of the neural network models or the training process, which could be relevant for deployment in resource-constrained environments.
Further research could explore extensions to Pointsoup, such as incorporating semantic information or supporting progressive decoding, to expand its applicability to a broader range of point cloud-based applications.
Conclusion
Pointsoup represents a significant advancement in point cloud compression technology, enabling high-performance and low-latency transmission and decoding of large-scale 3D scenes. Its innovative neural network-based approach and supporting techniques make it a promising solution for a wide range of applications, from virtual/augmented reality to autonomous driving and beyond. As point cloud data continues to grow in importance, Pointsoup's ability to efficiently manage this data could have far-reaching implications for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pointsoup: High-Performance and Extremely Low-Decoding-Latency Learned Geometry Codec for Large-Scale Point Cloud Scenes
Kang You, Kai Liu, Li Yu, Pan Gao, Dandan Ding
Despite considerable progress being achieved in point cloud geometry compression, there still remains a challenge in effectively compressing large-scale scenes with sparse surfaces. Another key challenge lies in reducing decoding latency, a crucial requirement in real-world application. In this paper, we propose Pointsoup, an efficient learning-based geometry codec that attains high-performance and extremely low-decoding-latency simultaneously. Inspired by conventional Trisoup codec, a point model-based strategy is devised to characterize local surfaces. Specifically, skin features are embedded from local windows via an attention-based encoder, and dilated windows are introduced as cross-scale priors to infer the distribution of quantized features in parallel. During decoding, features undergo fast refinement, followed by a folding-based point generator that reconstructs point coordinates with fairly fast speed. Experiments show that Pointsoup achieves state-of-the-art performance on multiple benchmarks with significantly lower decoding complexity, i.e., up to 90$sim$160$times$ faster than the G-PCCv23 Trisoup decoder on a comparatively low-end platform (e.g., one RTX 2080Ti). Furthermore, it offers variable-rate control with a single neural model (2.9MB), which is attractive for industrial practitioners.
Read more4/23/2024
✅
0
Inter-Frame Compression for Dynamic Point Cloud Geometry Coding
Anique Akhtar, Zhu Li, Geert Van der Auwera
Efficient point cloud compression is essential for applications like virtual and mixed reality, autonomous driving, and cultural heritage. This paper proposes a deep learning-based inter-frame encoding scheme for dynamic point cloud geometry compression. We propose a lossy geometry compression scheme that predicts the latent representation of the current frame using the previous frame by employing a novel feature space inter-prediction network. The proposed network utilizes sparse convolutions with hierarchical multiscale 3D feature learning to encode the current frame using the previous frame. The proposed method introduces a novel predictor network for motion compensation in the feature domain to map the latent representation of the previous frame to the coordinates of the current frame to predict the current frame's feature embedding. The framework transmits the residual of the predicted features and the actual features by compressing them using a learned probabilistic factorized entropy model. At the receiver, the decoder hierarchically reconstructs the current frame by progressively rescaling the feature embedding. The proposed framework is compared to the state-of-the-art Video-based Point Cloud Compression (V-PCC) and Geometry-based Point Cloud Compression (G-PCC) schemes standardized by the Moving Picture Experts Group (MPEG). The proposed method achieves more than 88% BD-Rate (Bjontegaard Delta Rate) reduction against G-PCCv20 Octree, more than 56% BD-Rate savings against G-PCCv20 Trisoup, more than 62% BD-Rate reduction against V-PCC intra-frame encoding mode, and more than 52% BD-Rate savings against V-PCC P-frame-based inter-frame encoding mode using HEVC. These significant performance gains are cross-checked and verified in the MPEG working group.
Read more9/4/2024
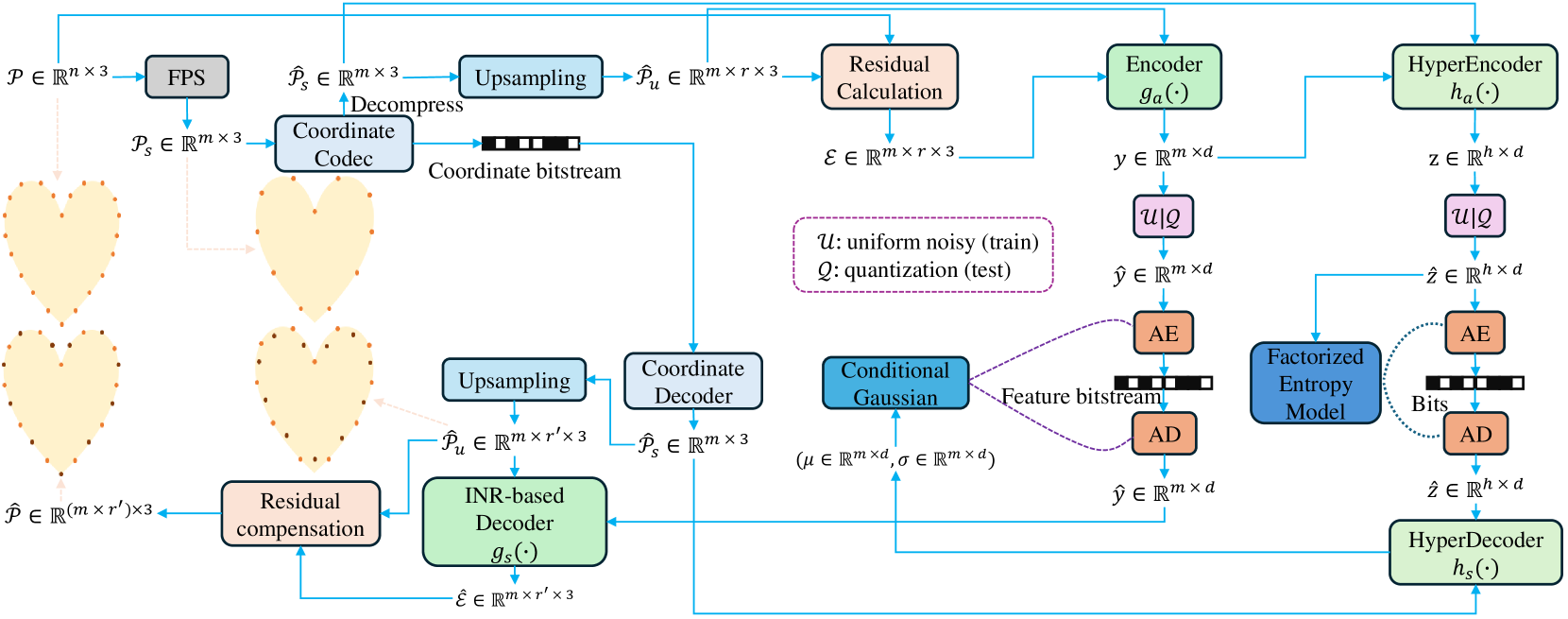
0
Fast Point Cloud Geometry Compression with Context-based Residual Coding and INR-based Refinement
Hao Xu, Xi Zhang, Xiaolin Wu
Compressing a set of unordered points is far more challenging than compressing images/videos of regular sample grids, because of the difficulties in characterizing neighboring relations in an irregular layout of points. Many researchers resort to voxelization to introduce regularity, but this approach suffers from quantization loss. In this research, we use the KNN method to determine the neighborhoods of raw surface points. This gives us a means to determine the spatial context in which the latent features of 3D points are compressed by arithmetic coding. As such, the conditional probability model is adaptive to local geometry, leading to significant rate reduction. Additionally, we propose a dual-layer architecture where a non-learning base layer reconstructs the main structures of the point cloud at low complexity, while a learned refinement layer focuses on preserving fine details. This design leads to reductions in model complexity and coding latency by two orders of magnitude compared to SOTA methods. Moreover, we incorporate an implicit neural representation (INR) into the refinement layer, allowing the decoder to sample points on the underlying surface at arbitrary densities. This work is the first to effectively exploit content-aware local contexts for compressing irregular raw point clouds, achieving high rate-distortion performance, low complexity, and the ability to function as an arbitrary-scale upsampling network simultaneously.
Read more8/7/2024

0
New!SPAC: Sampling-based Progressive Attribute Compression for Dense Point Clouds
Xiaolong Mao, Hui Yuan, Tian Guo, Shiqi Jiang, Raouf Hamzaoui, Sam Kwong
We propose an end-to-end attribute compression method for dense point clouds. The proposed method combines a frequency sampling module, an adaptive scale feature extraction module with geometry assistance, and a global hyperprior entropy model. The frequency sampling module uses a Hamming window and the Fast Fourier Transform to extract high-frequency components of the point cloud. The difference between the original point cloud and the sampled point cloud is divided into multiple sub-point clouds. These sub-point clouds are then partitioned using an octree, providing a structured input for feature extraction. The feature extraction module integrates adaptive convolutional layers and uses offset-attention to capture both local and global features. Then, a geometry-assisted attribute feature refinement module is used to refine the extracted attribute features. Finally, a global hyperprior model is introduced for entropy encoding. This model propagates hyperprior parameters from the deepest (base) layer to the other layers, further enhancing the encoding efficiency. At the decoder, a mirrored network is used to progressively restore features and reconstruct the color attribute through transposed convolutional layers. The proposed method encodes base layer information at a low bitrate and progressively adds enhancement layer information to improve reconstruction accuracy. Compared to the latest G-PCC test model (TMC13v23) under the MPEG common test conditions (CTCs), the proposed method achieved an average Bjontegaard delta bitrate reduction of 24.58% for the Y component (21.23% for YUV combined) on the MPEG Category Solid dataset and 22.48% for the Y component (17.19% for YUV combined) on the MPEG Category Dense dataset. This is the first instance of a learning-based codec outperforming the G-PCC standard on these datasets under the MPEG CTCs.
Read more9/17/2024