Porting HPC Applications to AMD Instinct$^text{TM}$ MI300A Using Unified Memory and OpenMP
2405.00436
95
1
✅
Abstract
AMD Instinct$^text{TM}$ MI300A is the world's first data center accelerated processing unit (APU) with memory shared between the AMD Zen 4 EPYC$^text{TM}$ cores and third generation CDNA$^text{TM}$ compute units. A single memory space offers several advantages: i) it eliminates the need for data replication and costly data transfers, ii) it substantially simplifies application development and allows an incremental acceleration of applications, iii) is easy to maintain, and iv) its potential can be well realized via the abstractions in the OpenMP 5.2 standard, where the host and the device data environments can be unified in a more performant way. In this article, we provide a blueprint of the APU programming model leveraging unified memory and highlight key distinctions compared to the conventional approach with discrete GPUs. OpenFOAM, an open-source C++ library for computational fluid dynamics, is presented as a case study to emphasize the flexibility and ease of offloading a full-scale production-ready application on MI300 APUs using directive-based OpenMP programming.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The AMD Instinct$^text{TM}$ MI300A is a new data center accelerator that combines AMD Zen 4 EPYC$^text{TM}$ cores and third-generation CDNA$^text{TM}$ compute units in a single device.
- This "accelerated processing unit" (APU) design allows the CPU and GPU components to share a unified memory space, providing several advantages over the traditional discrete GPU approach.
- The paper explores the programming model for this new APU architecture, highlighting how it can simplify application development and enable more efficient acceleration of existing applications using the OpenMP 5.2 standard.
- A case study on the OpenFOAM computational fluid dynamics library is presented to demonstrate the flexibility and ease of offloading a production-ready application onto the MI300 APU using directive-based OpenMP programming.
Plain English Explanation
The AMD Instinct$^text{TM}$ MI300A is a new type of computer chip designed for data centers. It combines traditional CPU cores (based on AMD's Zen 4 EPYC$^text{TM}$ architecture) with more specialized GPU-like "compute units" (based on AMD's third-generation CDNA$^text{TM}$ technology). This combination of CPU and GPU components in a single chip is called an "accelerated processing unit" or APU.
The key advantage of the MI300A APU is that the CPU and GPU components can share a single pool of memory, rather than having separate memory spaces like in traditional discrete GPU systems. This unified memory approach can provide several benefits, as outlined in a related paper on optimizing offload performance in heterogeneous MPSoCs. This includes eliminating the need to copy data between the CPU and GPU, simplifying application development, and making it easier to incrementally accelerate existing applications.
The paper explains how the MI300A's unified memory can be effectively leveraged using the OpenMP 5.2 programming standard. OpenMP provides abstractions that allow the host CPU and accelerator device to share a common data environment, enabling more performant offloading compared to traditional approaches. The authors demonstrate this by using OpenFOAM, a widely-used computational fluid dynamics library, as a case study. They show how the entire OpenFOAM application can be easily offloaded to the MI300A APU using simple OpenMP directives, without the need for major code changes.
Technical Explanation
The AMD Instinct$^text{TM}$ MI300A is the world's first data center APU that features a unified memory space shared between the AMD Zen 4 EPYC$^text{TM}$ CPU cores and the third-generation CDNA$^text{TM}$ compute units. This unified memory design offers several advantages over the traditional discrete GPU approach:
- It eliminates the need for data replication and costly data transfers between the CPU and GPU memory spaces.
- It substantially simplifies application development and allows for the incremental acceleration of existing applications.
- It is easier to maintain and manage compared to systems with separate CPU and GPU memory.
- The potential of this unified memory architecture can be well realized through the abstractions provided in the OpenMP 5.2 standard, where the host and device data environments can be unified in a more performant way. This is explored in a related paper on automatic BLAS offloading in unified memory architectures.
The paper presents a case study using the OpenFOAM computational fluid dynamics library to demonstrate the flexibility and ease of offloading a full-scale production-ready application onto the MI300 APU using directive-based OpenMP programming. This approach allows for the incremental acceleration of the application, without requiring major code changes or a complete rewrite.
Critical Analysis
The paper provides a strong theoretical and practical demonstration of the advantages of the MI300A's unified memory architecture and its potential for simplifying application development and acceleration. However, the analysis is limited to a single case study with OpenFOAM, and more research may be needed to understand the broader applicability and performance characteristics across a wider range of real-world applications and workloads.
Further research could also explore the scalability and efficiency of the unified memory approach as the size and complexity of the applications grow, as well as any potential limitations or bottlenecks that may arise in certain scenarios.
Conclusion
The AMD Instinct$^text{TM}$ MI300A represents a significant advancement in data center accelerator design, with its unique APU architecture that combines CPU and GPU components in a single chip with a shared memory space. This innovative approach can simplify application development and enable more efficient acceleration of existing workloads, as demonstrated by the OpenFOAM case study.
The paper provides a promising blueprint for leveraging the MI300A's unified memory capabilities through the OpenMP 5.2 programming model, offering a more seamless path for incremental application offloading and acceleration. As the industry continues to explore heterogeneous computing solutions, the insights from this research could have broader implications for the design of future data center hardware and software ecosystems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
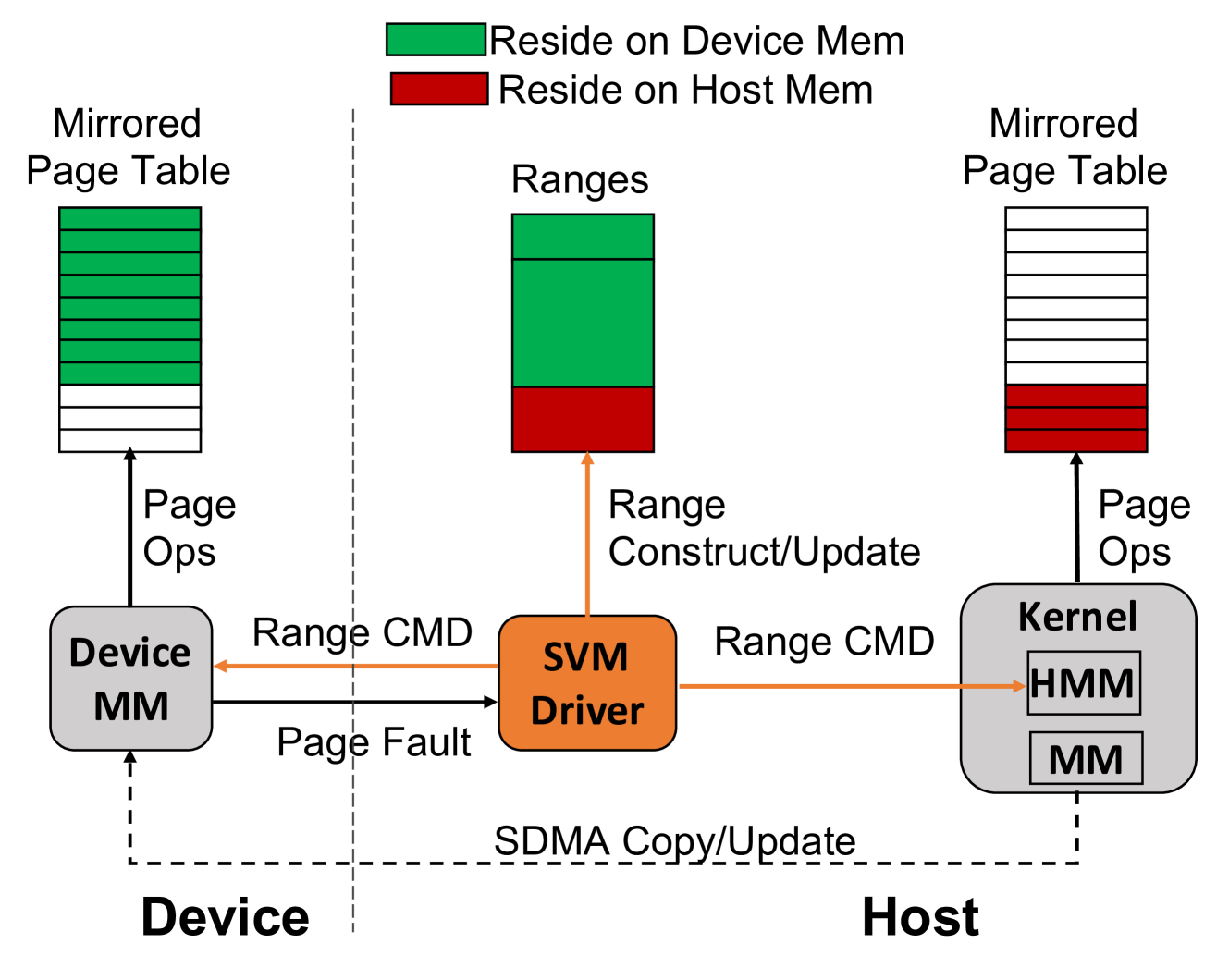
Shared Virtual Memory: Its Design and Performance Implications for Diverse Applications
Bennett Cooper, Thomas R. W. Scogland, Rong Ge
0
0
Discrete GPU accelerators, while providing massive computing power for supercomputers and data centers, have their separate memory domain. Explicit memory management across device and host domains in programming is tedious and error-prone. To improve programming portability and productivity, Unified Memory (UM) integrates GPU memory into the host virtual memory systems, and provides transparent data migration between them and GPU memory oversubscription. Nevertheless, current UM technologies cause significant performance loss for applications. With AMD GPUs increasingly being integrated into the world's leading supercomputers, it is necessary to understand their Shared Virtual Memory (SVM) and mitigate the performance impacts. In this work, we delve into the SVM design, examine its interactions with applications' data accesses at fine granularity, and quantitatively analyze its performance effects on various applications and identify the performance bottlenecks. Our research reveals that SVM employs an aggressive prefetching strategy for demand paging. This prefetching is efficient when GPU memory is not oversubscribed. However, in tandem with the eviction policy, it causes excessive thrashing and performance degradation for certain applications under oversubscription. We discuss SVM-aware algorithms and SVM design changes to mitigate the performance impacts. To the best of our knowledge, this work is the first in-depth and comprehensive study for SVM technologies.
5/14/2024
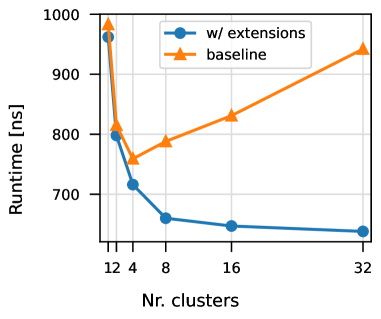
Optimizing Offload Performance in Heterogeneous MPSoCs
Luca Colagrande, Luca Benini
0
0
Heterogeneous multi-core architectures combine a few host cores, optimized for single-thread performance, with many small energy-efficient accelerator cores for data-parallel processing, on a single chip. Offloading a computation to the many-core acceleration fabric introduces a communication and synchronization cost which reduces the speedup attainable on the accelerator, particularly for small and fine-grained parallel tasks. We demonstrate that by co-designing the hardware and offload routines, we can increase the speedup of an offloaded DAXPY kernel by as much as 47.9%. Furthermore, we show that it is possible to accurately model the runtime of an offloaded application, accounting for the offload overheads, with as low as 1% MAPE error, enabling optimal offload decisions under offload execution time constraints.
4/3/2024
🚀
Automatic BLAS Offloading on Unified Memory Architecture: A Study on NVIDIA Grace-Hopper
Junjie Li, Yinzhi Wang, Xiao Liang, Hang Liu
0
0
Porting codes to GPU often requires major efforts. While several tools exist for automatically offload numerical libraries such as BLAS and LAPACK, they often prove impractical due to the high cost of mandatory data transfer. The new unified memory architecture in NVIDIA Grace-Hopper allows high bandwidth cache-coherent memory access of all memory from both CPU and GPU, potentially eliminating bottleneck faced in conventional architecture. This breakthrough opens up new avenues for application development and porting strategies. In this study, we introduce a new tool for automatic BLAS offload, the tool leverages the high speed cache coherent NVLink C2C interconnect in Grace-Hopper, and enables performant GPU offload for BLAS heavy applications with no code changes or recompilation. The tool was tested on two quantum chemistry or physics codes, great performance benefits were observed.
5/2/2024
🚀
GROMACS on AMD GPU-Based HPC Platforms: Using SYCL for Performance and Portability
Andrey Alekseenko, Szil'ard P'all, Erik Lindahl
0
0
GROMACS is a widely-used molecular dynamics software package with a focus on performance, portability, and maintainability across a broad range of platforms. Thanks to its early algorithmic redesign and flexible heterogeneous parallelization, GROMACS has successfully harnessed GPU accelerators for more than a decade. With the diversification of accelerator platforms in HPC and no obvious choice for a multi-vendor programming model, the GROMACS project found itself at a crossroads. The performance and portability requirements, and a strong preference for a standards-based solution, motivated our choice to use SYCL on both new HPC GPU platforms: AMD and Intel. Since the GROMACS 2022 release, the SYCL backend has been the primary means to target AMD GPUs in preparation for exascale HPC architectures like LUMI and Frontier. SYCL is a cross-platform, royalty-free, C++17-based standard for programming hardware accelerators. It allows using the same code to target GPUs from all three major vendors with minimal specialization. While SYCL implementations build on native toolchains, performance of such an approach is not immediately evident. Biomolecular simulations have challenging performance characteristics: latency sensitivity, the need for strong scaling, and typical iteration times as short as hundreds of microseconds. Hence, obtaining good performance across the range of problem sizes and scaling regimes is particularly challenging. Here, we share the results of our work on readying GROMACS for AMD GPU platforms using SYCL, and demonstrate performance on Cray EX235a machines with MI250X accelerators. Our findings illustrate that portability is possible without major performance compromises. We provide a detailed analysis of node-level kernel and runtime performance with the aim of sharing best practices with the HPC community on using SYCL as a performance-portable GPU framework.
5/3/2024