Shared Virtual Memory: Its Design and Performance Implications for Diverse Applications

0
Sign in to get full access
Overview
- The research paper examines the design and performance implications of Shared Virtual Memory (SVM) for diverse applications.
- SVM is a memory management system that allows different hardware components, such as CPUs and GPUs, to access a shared pool of memory.
- The paper explores the benefits and challenges of using SVM in various application domains, including High-Performance Computing (HPC), machine learning training, and distributed optimization algorithms.
Plain English Explanation
Shared Virtual Memory (SVM) is a way for different computer components, like CPUs and GPUs, to access the same pool of memory. This allows the components to work together more efficiently on a wide range of applications, from complex simulations to machine learning models.
The research paper explores how SVM works and how it can impact the performance of these diverse applications. For example, in High-Performance Computing (HPC), SVM can make it easier to move data between CPUs and GPUs, improving the overall speed of the computations.
Similarly, in machine learning training, SVM can help manage the large amounts of data and models that need to be processed, potentially leading to faster training times.
The paper also looks at how SVM can be used in distributed optimization algorithms, where multiple computers work together to solve a complex problem. SVM can help coordinate the sharing of data and resources between these distributed systems.
Overall, the research suggests that SVM has the potential to improve the performance and efficiency of a wide range of applications, from scientific computing to artificial intelligence.
Technical Explanation
The paper presents a comprehensive analysis of Shared Virtual Memory (SVM), a memory management system that allows different hardware components, such as CPUs and GPUs, to access a shared pool of memory. The authors explore the design and architecture of SVM, as well as its performance implications for diverse applications.
One of the key aspects of SVM is its ability to seamlessly integrate heterogeneous memory resources, enabling efficient data sharing and communication between different processing units. This is particularly relevant in High-Performance Computing (HPC) scenarios, where SVM can facilitate the transfer of data between CPUs and GPUs, improving the overall performance of HPC applications.
The paper also investigates the role of SVM in machine learning training workflows. By providing a unified memory management system, SVM can help address the challenges associated with managing large amounts of data and models, potentially leading to faster training times and more efficient resource utilization.
Furthermore, the authors explore the application of SVM in the context of distributed optimization algorithms, where multiple processing units collaborate to solve complex problems. SVM's ability to coordinate the sharing of data and resources across distributed systems can enhance the efficiency and scalability of these algorithms.
Critical Analysis
The research paper presents a thorough examination of Shared Virtual Memory (SVM) and its potential impact on diverse applications. The authors have provided a comprehensive overview of the SVM design and architecture, highlighting its key features and capabilities.
One potential area for further research mentioned in the paper is the need to explore the performance implications of SVM in more specific application domains, such as sparse matrix-vector multiplication or large language model serving. By delving deeper into these specialized use cases, researchers could gain a more nuanced understanding of the trade-offs and optimization strategies required for SVM in different contexts.
Additionally, the paper could have addressed the potential challenges and limitations of SVM more explicitly. For instance, the authors could have discussed the impact of hardware heterogeneity, the overhead associated with memory virtualization, or the challenges of cache coherence in SVM-based systems. Exploring these aspects in more detail could help identify areas for further improvement and refinement of the SVM design.
Overall, the research paper provides a solid foundation for understanding the design and performance implications of Shared Virtual Memory. By addressing the areas for further research and potential limitations, future studies could build upon this work and contribute to the ongoing development and optimization of SVM-based systems.
Conclusion
The research paper presents a comprehensive analysis of Shared Virtual Memory (SVM) and its design and performance implications for diverse applications. SVM's ability to seamlessly integrate heterogeneous memory resources and enable efficient data sharing between different processing units, such as CPUs and GPUs, holds significant promise for improving the performance and efficiency of a wide range of applications, from High-Performance Computing (HPC) to machine learning training and distributed optimization algorithms.
The findings suggest that SVM has the potential to unlock new possibilities in the field of computing, enabling more seamless collaboration between different hardware components and potentially leading to faster, more efficient, and more scalable solutions. As the technological landscape continues to evolve, the insights provided in this research paper could pave the way for further advancements in memory management and the optimization of diverse computational workloads.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Shared Virtual Memory: Its Design and Performance Implications for Diverse Applications
Bennett Cooper, Thomas R. W. Scogland, Rong Ge
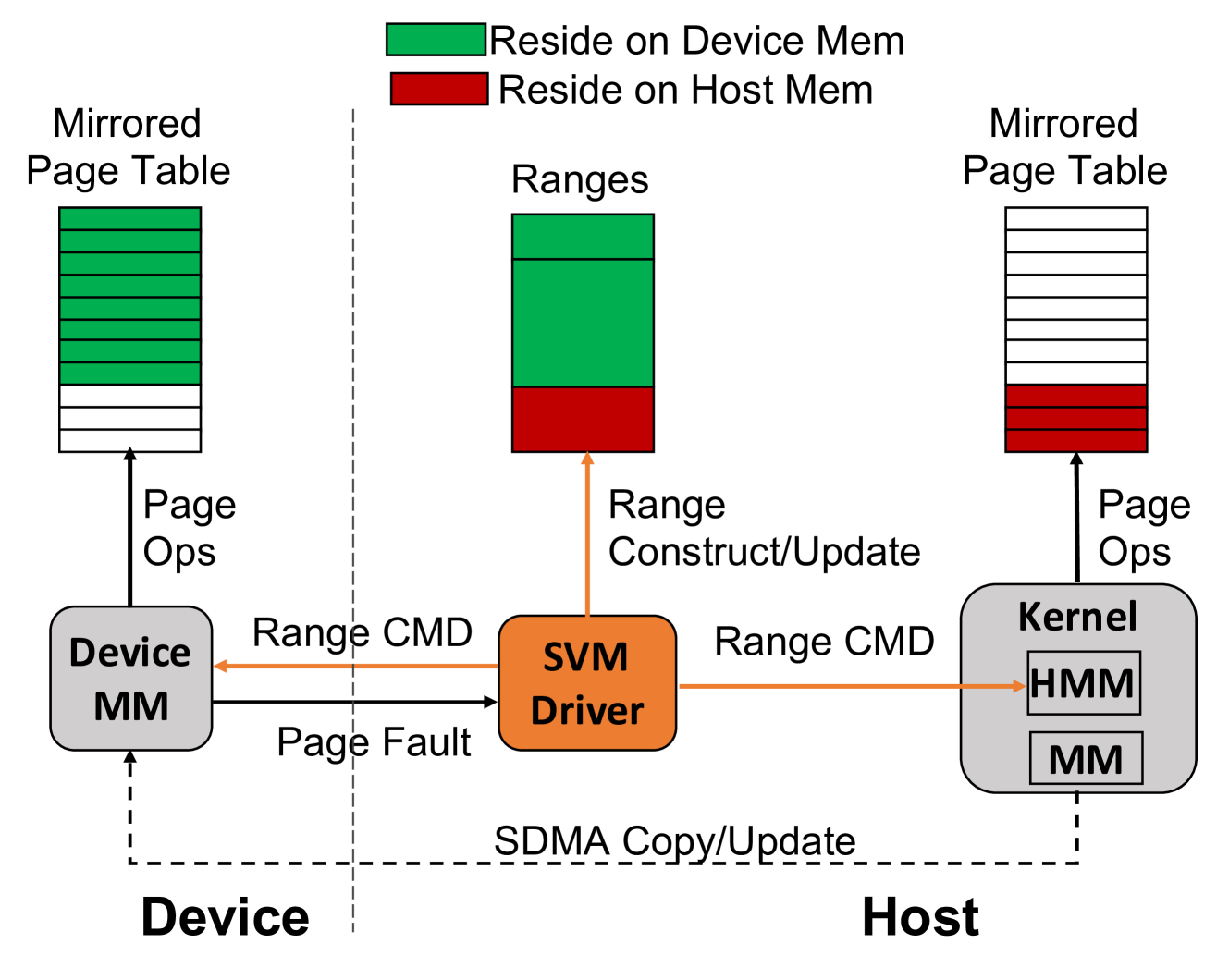
Discrete GPU accelerators, while providing massive computing power for supercomputers and data centers, have their separate memory domain. Explicit memory management across device and host domains in programming is tedious and error-prone. To improve programming portability and productivity, Unified Memory (UM) integrates GPU memory into the host virtual memory systems, and provides transparent data migration between them and GPU memory oversubscription. Nevertheless, current UM technologies cause significant performance loss for applications. With AMD GPUs increasingly being integrated into the world's leading supercomputers, it is necessary to understand their Shared Virtual Memory (SVM) and mitigate the performance impacts. In this work, we delve into the SVM design, examine its interactions with applications' data accesses at fine granularity, and quantitatively analyze its performance effects on various applications and identify the performance bottlenecks. Our research reveals that SVM employs an aggressive prefetching strategy for demand paging. This prefetching is efficient when GPU memory is not oversubscribed. However, in tandem with the eviction policy, it causes excessive thrashing and performance degradation for certain applications under oversubscription. We discuss SVM-aware algorithms and SVM design changes to mitigate the performance impacts. To the best of our knowledge, this work is the first in-depth and comprehensive study for SVM technologies.
Read more5/14/2024

0
Harnessing Integrated CPU-GPU System Memory for HPC: a first look into Grace Hopper
Gabin Schieffer, Jacob Wahlgren, Jie Ren, Jennifer Faj, Ivy Peng
Memory management across discrete CPU and GPU physical memory is traditionally achieved through explicit GPU allocations and data copy or unified virtual memory. The Grace Hopper Superchip, for the first time, supports an integrated CPU-GPU system page table, hardware-level addressing of system allocated memory, and cache-coherent NVLink-C2C interconnect, bringing an alternative solution for enabling a Unified Memory system. In this work, we provide the first in-depth study of the system memory management on the Grace Hopper Superchip, in both in-memory and memory oversubscription scenarios. We provide a suite of six representative applications, including the Qiskit quantum computing simulator, using system memory and managed memory. Using our memory utilization profiler and hardware counters, we quantify and characterize the impact of the integrated CPU-GPU system page table on GPU applications. Our study focuses on first-touch policy, page table entry initialization, page sizes, and page migration. We identify practical optimization strategies for different access patterns. Our results show that as a new solution for unified memory, the system-allocated memory can benefit most use cases with minimal porting efforts.
Read more7/11/2024
✅
66
Porting HPC Applications to AMD Instinct$^text{TM}$ MI300A Using Unified Memory and OpenMP
Suyash Tandon, Leopold Grinberg, Gheorghe-Teodor Bercea, Carlo Bertolli, Mark Olesen, Simone Bn`a, Nicholas Malaya
AMD Instinct$^text{TM}$ MI300A is the world's first data center accelerated processing unit (APU) with memory shared between the AMD Zen 4 EPYC$^text{TM}$ cores and third generation CDNA$^text{TM}$ compute units. A single memory space offers several advantages: i) it eliminates the need for data replication and costly data transfers, ii) it substantially simplifies application development and allows an incremental acceleration of applications, iii) is easy to maintain, and iv) its potential can be well realized via the abstractions in the OpenMP 5.2 standard, where the host and the device data environments can be unified in a more performant way. In this article, we provide a blueprint of the APU programming model leveraging unified memory and highlight key distinctions compared to the conventional approach with discrete GPUs. OpenFOAM, an open-source C++ library for computational fluid dynamics, is presented as a case study to emphasize the flexibility and ease of offloading a full-scale production-ready application on MI300 APUs using directive-based OpenMP programming.
Read more5/2/2024
0
Breaking the Memory Wall: A Study of I/O Patterns and GPU Memory Utilization for Hybrid CPU-GPU Offloaded Optimizers
Avinash Maurya, Jie Ye, M. Mustafa Rafique, Franck Cappello, Bogdan Nicolae
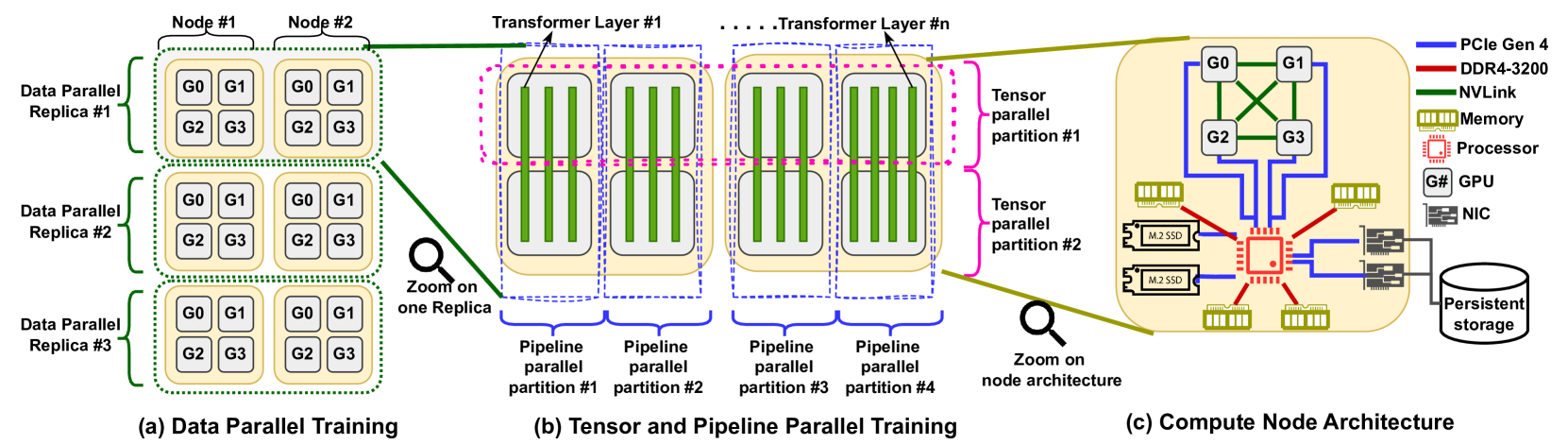
Transformers and LLMs have seen rapid adoption in all domains. Their sizes have exploded to hundreds of billions of parameters and keep increasing. Under these circumstances, the training of transformers is slow and often takes in the order of weeks or months. Thanks to 3D model parallelism (data, pipeline, and tensor-level parallelism), the training can scale to a large number of GPUs, which reduces the duration of the training but dramatically increases the cost. Even when a large number of GPUs are available, the aggregated GPU memory is often not enough to hold the full training state (optimizer state, model parameters, and gradients). To compensate, state-of-the-art approaches offload the optimizer state at least partially to the host memory and perform hybrid CPU-GPU computations. Such flexible solutions dramatically reduce the GPU memory utilization, which makes it feasible to run the training on a smaller number of GPUs at the cost of performance penalty. Unfortunately, the challenges and bottlenecks of adopting this strategy are not sufficiently studied by state-of-the-art, which results in poor management of the combined host-GPU memory and poor overlapping between data movements and computations. In this paper, we aim to fill this gap by characterizing the behavior of offloaded training using the DeepSpeed runtime. Specifically, we study the GPU memory utilization over time during each iteration, the activity on the PCIe related to transfers between the host memory and the GPU memory, and the relationship between resource utilization and the steps involved in each iteration. Thanks to this study, we reveal opportunities for future improvements of offloading solutions, which enable greater flexibility to optimize the cost-performance trade-off in the context of transformer and LLM training.
Read more6/18/2024