Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior
2404.10394
0
0

Abstract
Existing neural rendering-based text-to-3D-portrait generation methods typically make use of human geometry prior and diffusion models to obtain guidance. However, relying solely on geometry information introduces issues such as the Janus problem, over-saturation, and over-smoothing. We present Portrait3D, a novel neural rendering-based framework with a novel joint geometry-appearance prior to achieve text-to-3D-portrait generation that overcomes the aforementioned issues. To accomplish this, we train a 3D portrait generator, 3DPortraitGAN-Pyramid, as a robust prior. This generator is capable of producing 360{deg} canonical 3D portraits, serving as a starting point for the subsequent diffusion-based generation process. To mitigate the grid-like artifact caused by the high-frequency information in the feature-map-based 3D representation commonly used by most 3D-aware GANs, we integrate a novel pyramid tri-grid 3D representation into 3DPortraitGAN-Pyramid. To generate 3D portraits from text, we first project a randomly generated image aligned with the given prompt into the pre-trained 3DPortraitGAN-Pyramid's latent space. The resulting latent code is then used to synthesize a pyramid tri-grid. Beginning with the obtained pyramid tri-grid, we use score distillation sampling to distill the diffusion model's knowledge into the pyramid tri-grid. Following that, we utilize the diffusion model to refine the rendered images of the 3D portrait and then use these refined images as training data to further optimize the pyramid tri-grid, effectively eliminating issues with unrealistic color and unnatural artifacts. Our experimental results show that Portrait3D can produce realistic, high-quality, and canonical 3D portraits that align with the prompt.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a text-guided 3D portrait generation model called Portrait3D that can create high-quality 3D portraits from text descriptions.
- The model uses a pyramid representation to capture multi-scale features and leverages a GAN-based prior to generate realistic 3D facial geometry and textures.
- The authors demonstrate that Portrait3D outperforms existing text-to-3D generation methods in terms of visual quality, diversity, and semantic alignment.
Plain English Explanation
The researchers have developed a new way to create 3D portraits, or digital 3D models of people's faces, based on text descriptions. Their model, called Portrait3D, takes a text description as input and generates a realistic 3D portrait as output.
The key innovations in Portrait3D are:
-
Pyramid Representation: The model uses a multi-scale, or "pyramid", approach to capture features at different levels of detail. This allows it to generate high-resolution 3D portraits that look natural and lifelike.
-
GAN-based Prior: The model uses a generative adversarial network (GAN) to learn the characteristics of real 3D faces. This "prior" knowledge helps the model generate more realistic 3D portraits that match the input text description.
By combining these techniques, Portrait3D is able to create 3D portraits that are higher quality, more diverse, and better aligned with the text description compared to previous methods. This could be useful for applications like virtual avatars, 3D character design, and photorealistic 3D modeling.
Technical Explanation
The authors of the paper propose a text-to-3D portrait generation model called Portrait3D that leverages a pyramid representation and a GAN-based prior to generate high-quality 3D portraits from text descriptions.
The key technical components of Portrait3D include:
-
Pyramid Representation: The model uses a multi-scale pyramid architecture to capture features at different levels of detail. This allows it to generate high-resolution 3D facial geometry and textures that preserve important details.
-
GAN-based Prior: The model includes a generative adversarial network (GAN) component that learns the distribution of real 3D faces. This GAN-based prior helps the model generate more realistic 3D portraits that better match the input text description.
-
Text-to-3D Pipeline: The model takes a text description as input and outputs a 3D portrait. It uses a text encoder, a 3D generator network, and a discriminator network to convert the text into a realistic 3D face.
The authors evaluate Portrait3D on several benchmark datasets and show that it outperforms existing text-to-3D generation methods in terms of visual quality, diversity, and semantic alignment. They also provide ablation studies to understand the contribution of each key component to the overall performance.
Critical Analysis
The authors present a compelling approach to text-guided 3D portrait generation with Portrait3D. The use of a pyramid representation and a GAN-based prior are well-motivated and appear to offer significant improvements over prior work.
However, the paper does not address several potential limitations and areas for further research:
-
Generalization to Diverse Facial Features: While the results demonstrate strong performance on the evaluation datasets, it's unclear how well Portrait3D would generalize to a wider range of facial features, ethnicities, and age groups.
-
Controllability and Editability: The paper does not explore the ability to fine-tune or edit the generated 3D portraits beyond the initial text description. This could be an important consideration for real-world applications.
-
Computational Efficiency: The computational requirements of the multi-scale pyramid architecture and GAN-based components are not discussed. This could be a limiting factor for practical deployment, especially in interactive or real-time scenarios.
-
Ethical Considerations: The paper does not address potential ethical concerns around the use of such technology, such as the risk of misuse for creating synthetic identities or deepfakes.
Despite these limitations, Portrait3D represents a significant advance in text-guided 3D portrait generation and could have important applications in fields like virtual avatars, 3D character design, and photorealistic modeling. Further research to address the identified issues could help unlock the full potential of this technology.
Conclusion
The Portrait3D model presented in this paper demonstrates a novel approach to text-guided 3D portrait generation that leverages a pyramid representation and a GAN-based prior to create high-quality, diverse, and semantically aligned 3D faces. This work represents an important step forward in the field of 3D content creation and could have a range of applications in virtual reality, gaming, and digital media.
While the authors have shown promising results, there are still opportunities to improve the model's generalization, controllability, and computational efficiency, as well as to address potential ethical concerns. Continued research in this area could lead to even more advanced and versatile text-to-3D generation systems that could transform the way we create and interact with 3D content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
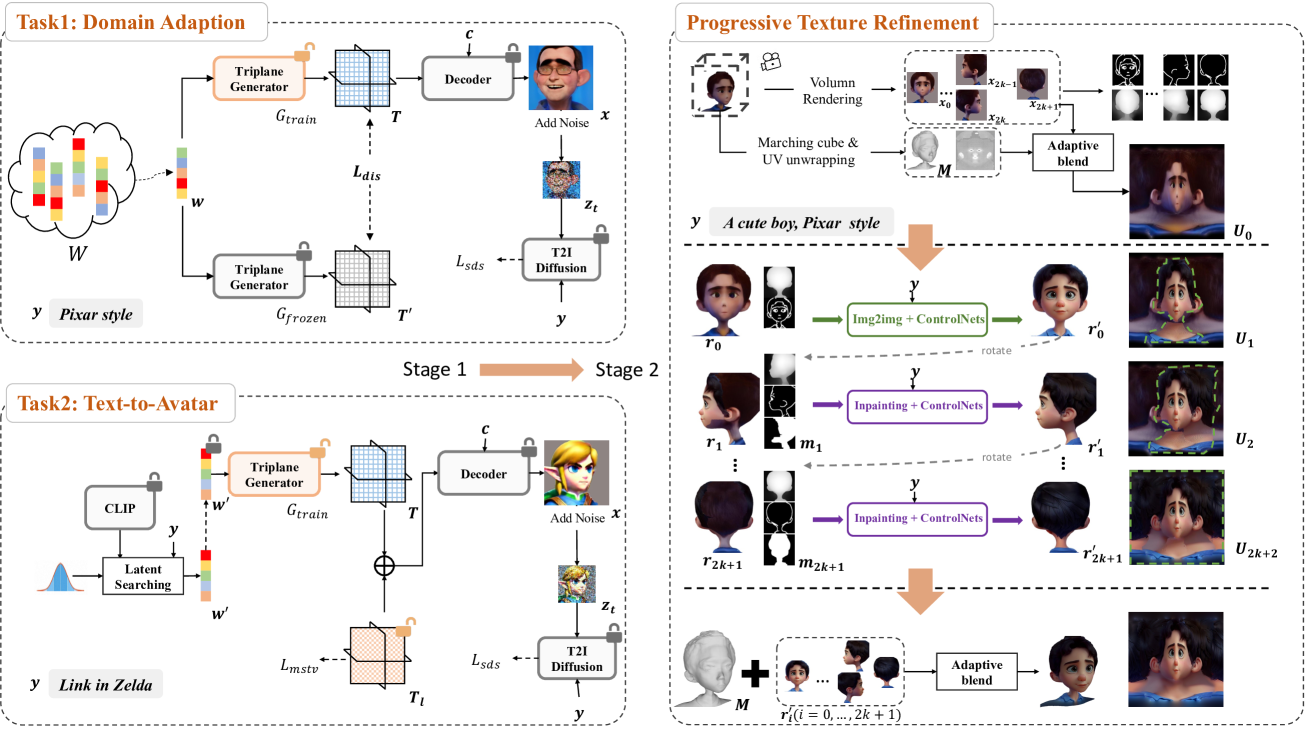
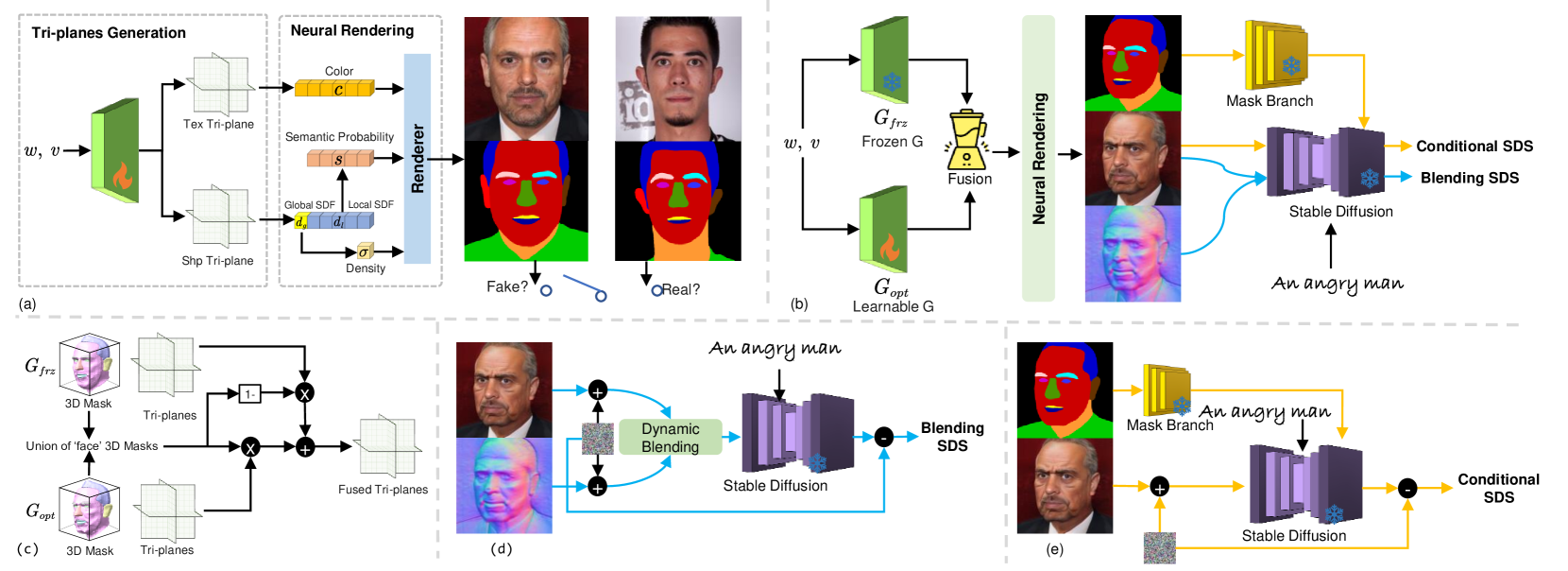
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaptation by Combining 3D GANs and Diffusion Priors
Biwen Lei, Kai Yu, Mengyang Feng, Miaomiao Cui, Xuansong Xie
0
0
Text-guided domain adaptation and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaptation and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaptation. To enhance the diversity in domain adaptation and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaptation and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
4/15/2024

PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion
Ying-Tian Liu, Yuan-Chen Guo, Guan Luo, Heyi Sun, Wei Yin, Song-Hai Zhang
0
0
Diffusion models trained on large-scale text-image datasets have demonstrated a strong capability of controllable high-quality image generation from arbitrary text prompts. However, the generation quality and generalization ability of 3D diffusion models is hindered by the scarcity of high-quality and large-scale 3D datasets. In this paper, we present PI3D, a framework that fully leverages the pre-trained text-to-image diffusion models' ability to generate high-quality 3D shapes from text prompts in minutes. The core idea is to connect the 2D and 3D domains by representing a 3D shape as a set of Pseudo RGB Images. We fine-tune an existing text-to-image diffusion model to produce such pseudo-images using a small number of text-3D pairs. Surprisingly, we find that it can already generate meaningful and consistent 3D shapes given complex text descriptions. We further take the generated shapes as the starting point for a lightweight iterative refinement using score distillation sampling to achieve high-quality generation under a low budget. PI3D generates a single 3D shape from text in only 3 minutes and the quality is validated to outperform existing 3D generative models by a large margin.
4/23/2024

Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Jaehoon Ko, Kyusun Cho, Joungbin Lee, Heeji Yoon, Sangmin Lee, Sangjun Ahn, Seungryong Kim
0
0
Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
4/1/2024
MaTe3D: Mask-guided Text-based 3D-aware Portrait Editing
Kangneng Zhou, Daiheng Gao, Xuan Wang, Jie Zhang, Peng Zhang, Xusen Sun, Longhao Zhang, Shiqi Yang, Bang Zhang, Liefeng Bo, Yaxing Wang, Ming-Ming Cheng
0
0
3D-aware portrait editing has a wide range of applications in multiple fields. However, current approaches are limited due that they can only perform mask-guided or text-based editing. Even by fusing the two procedures into a model, the editing quality and stability cannot be ensured. To address this limitation, we propose textbf{MaTe3D}: mask-guided text-based 3D-aware portrait editing. In this framework, first, we introduce a new SDF-based 3D generator which learns local and global representations with proposed SDF and density consistency losses. This enhances masked-based editing in local areas; second, we present a novel distillation strategy: Conditional Distillation on Geometry and Texture (CDGT). Compared to exiting distillation strategies, it mitigates visual ambiguity and avoids mismatch between texture and geometry, thereby producing stable texture and convincing geometry while editing. Additionally, we create the CatMask-HQ dataset, a large-scale high-resolution cat face annotation for exploration of model generalization and expansion. We perform expensive experiments on both the FFHQ and CatMask-HQ datasets to demonstrate the editing quality and stability of the proposed method. Our method faithfully generates a 3D-aware edited face image based on a modified mask and a text prompt. Our code and models will be publicly released.
5/6/2024