PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation

0
Sign in to get full access
Overview
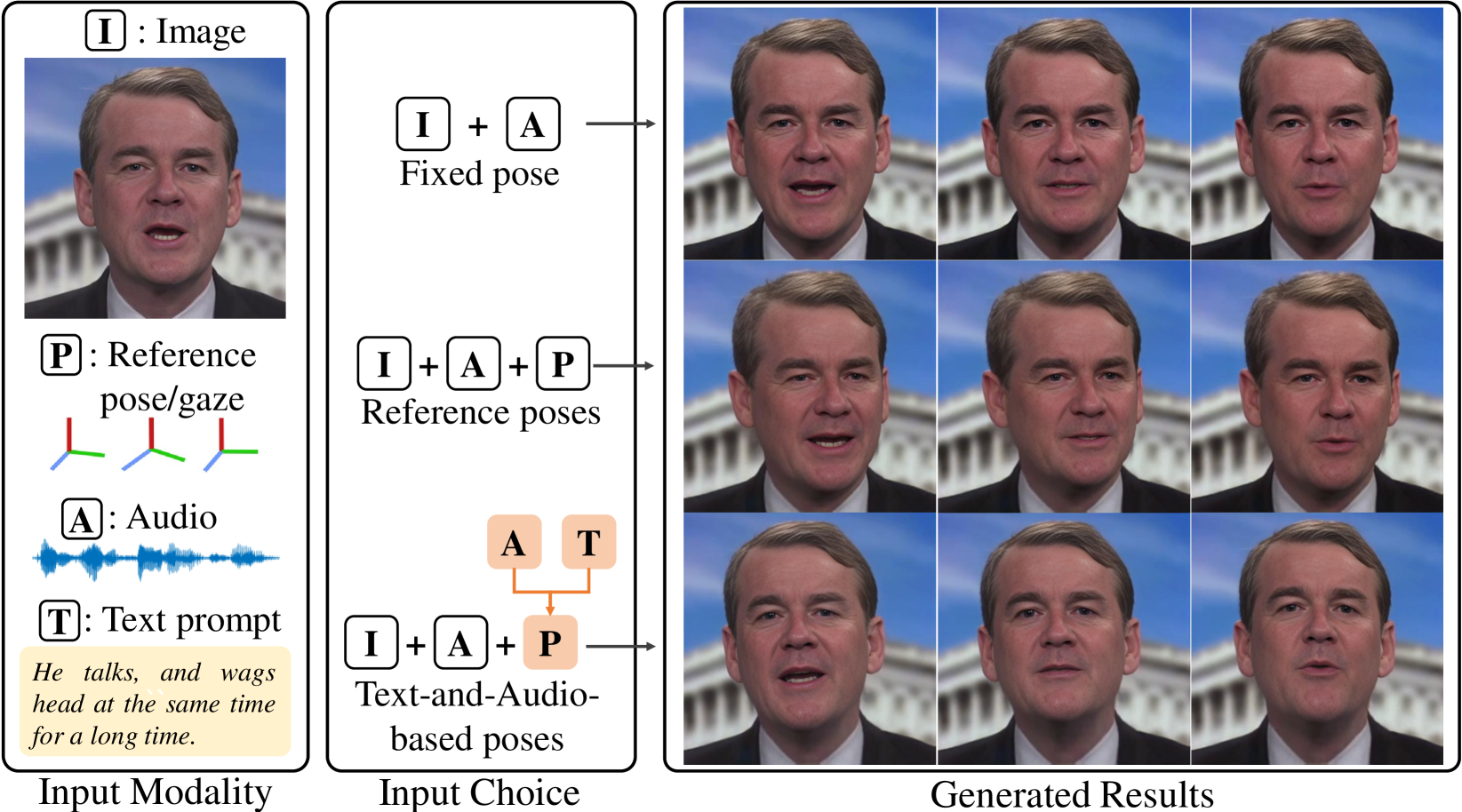
- PoseTalk is a method for generating one-shot talking head videos by controlling the pose and motion of a target face using text and audio input.
- It can synthesize realistic talking head videos of a person speaking from a single reference image, without requiring a large dataset of videos of that person.
- The approach uses a neural network to extract features from the text and audio, and then uses those features to control the pose and motion of the target face.
Plain English Explanation
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation presents a way to create videos of a person's face moving and speaking, starting with just a single photo of that person. The key insight is that the researchers can use the text being spoken and the audio of the voice to control how the face in the video should move and change expression.
The system works by first analyzing the text and audio to understand what is being said and how it should be said. It then takes that information and applies it to the single reference photo, generating a video of the person's face moving and speaking in a realistic way. This is useful for applications like video games, movies, or virtual assistants, where you might want a character to speak without having to film the actual person numerous times.
The main advantage of this approach is that it only requires a single photo of the person, rather than needing a large dataset of videos. This makes it more flexible and practical to use in many scenarios. The researchers show that their method can generate very realistic talking head videos that closely match the original person's appearance and mannerisms.
Technical Explanation
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation introduces a novel approach for generating one-shot talking head videos by controlling the pose and motion of a target face using text and audio input.
The key components of the PoseTalk system are:
-
Pose Predictor: This module takes the text and audio features as input and predicts the 3D head pose and facial landmarks for each frame of the output video.
-
Motion Refiner: This component refines the predicted motion to make it more natural and expressive, using an adversarial training approach.
-
Appearance Renderer: The final step is to render the target face with the predicted pose and refined motion, using a neural rendering network trained on a dataset of talking head videos.
The researchers demonstrate that PoseTalk can generate high-quality one-shot talking head videos that closely match the appearance and mannerisms of the target subject, without requiring a large dataset of videos. Quantitative and qualitative evaluations show the system outperforms previous state-of-the-art methods for this task.
Critical Analysis
The paper presents a compelling solution for one-shot talking head generation that leverages text and audio cues in a novel way. A key strength is the ability to produce realistic videos from a single reference image, which greatly expands the practical applicability compared to approaches requiring large video datasets.
However, the paper does acknowledge some limitations. For example, the system may struggle with challenging head poses or facial expressions that are not well-represented in the training data. There are also potential concerns around the ethical use of this technology, such as the creation of synthetic media that could be used for deception.
Additionally, the paper does not provide a thorough analysis of failure cases or the robustness of the system to noisy or incomplete input data. Further research could explore these areas and investigate ways to improve the generalization and reliability of the approach.
Overall, PoseTalk represents an important advancement in the field of talking head generation, with promising applications in areas like virtual assistants, computer animation, and video conferencing. But as with any powerful technology, careful consideration of the societal impacts will be crucial as the research progresses.
Conclusion
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation presents a novel method for generating high-quality, one-shot talking head videos by leveraging text and audio input to control the pose and motion of a target face.
The key innovation is the ability to produce realistic talking head videos from a single reference image, rather than requiring a large dataset of videos. This makes the technology more flexible and practical for a wide range of applications, such as virtual assistants, computer animation, and video conferencing.
The technical approach combines a pose predictor, motion refiner, and appearance renderer to generate the final video output. Evaluations show the system outperforms previous state-of-the-art methods, while also acknowledging some limitations and potential ethical considerations.
Overall, PoseTalk represents an important step forward in the field of one-shot talking head generation, with the potential to significantly impact how we create and interact with synthetic media in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation
Jun Ling, Yiwen Wang, Han Xue, Rong Xie, Li Song
While previous audio-driven talking head generation (THG) methods generate head poses from driving audio, the generated poses or lips cannot match the audio well or are not editable. In this study, we propose textbf{PoseTalk}, a THG system that can freely generate lip-synchronized talking head videos with free head poses conditioned on text prompts and audio. The core insight of our method is using head pose to connect visual, linguistic, and audio signals. First, we propose to generate poses from both audio and text prompts, where the audio offers short-term variations and rhythm correspondence of the head movements and the text prompts describe the long-term semantics of head motions. To achieve this goal, we devise a Pose Latent Diffusion (PLD) model to generate motion latent from text prompts and audio cues in a pose latent space. Second, we observe a loss-imbalance problem: the loss for the lip region contributes less than 4% of the total reconstruction loss caused by both pose and lip, making optimization lean towards head movements rather than lip shapes. To address this issue, we propose a refinement-based learning strategy to synthesize natural talking videos using two cascaded networks, i.e., CoarseNet, and RefineNet. The CoarseNet estimates coarse motions to produce animated images in novel poses and the RefineNet focuses on learning finer lip motions by progressively estimating lip motions from low-to-high resolutions, yielding improved lip-synchronization performance. Experiments demonstrate our pose prediction strategy achieves better pose diversity and realness compared to text-only or audio-only, and our video generator model outperforms state-of-the-art methods in synthesizing talking videos with natural head motions. Project: https://junleen.github.io/projects/posetalk.
Read more9/5/2024

0
Controllable Talking Face Generation by Implicit Facial Keypoints Editing
Dong Zhao, Jiaying Shi, Wenjun Li, Shudong Wang, Shenghui Xu, Zhaoming Pan
Audio-driven talking face generation has garnered significant interest within the domain of digital human research. Existing methods are encumbered by intricate model architectures that are intricately dependent on each other, complicating the process of re-editing image or video inputs. In this work, we present ControlTalk, a talking face generation method to control face expression deformation based on driven audio, which can construct the head pose and facial expression including lip motion for both single image or sequential video inputs in a unified manner. By utilizing a pre-trained video synthesis renderer and proposing the lightweight adaptation, ControlTalk achieves precise and naturalistic lip synchronization while enabling quantitative control over mouth opening shape. Our experiments show that our method is superior to state-of-the-art performance on widely used benchmarks, including HDTF and MEAD. The parameterized adaptation demonstrates remarkable generalization capabilities, effectively handling expression deformation across same-ID and cross-ID scenarios, and extending its utility to out-of-domain portraits, regardless of languages.
Read more6/6/2024
🛸
0
SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
Zeren Zhang, Haibo Qin, Jiayu Huang, Yixin Li, Hui Lin, Yitao Duan, Jinwen Ma
Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework's generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
Read more5/10/2024
🛸
0
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Lin, Jenny Sheng, Yu-Hui Wen, Minjing Yu, Yong-Jin Liu
The generation of stylistic 3D facial animations driven by speech presents a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. In particular, our style includes the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset are at https://diffposetalk.github.io .
Read more5/15/2024