Predicting Text Preference Via Structured Comparative Reasoning
2311.08390
0
0
🎯
Abstract
Comparative reasoning plays a crucial role in text preference prediction; however, large language models (LLMs) often demonstrate inconsistencies in their reasoning. While approaches like Chain-of-Thought improve accuracy in many other settings, they struggle to consistently distinguish the similarities and differences of complex texts. We introduce SC, a prompting approach that predicts text preferences by generating structured intermediate comparisons. SC begins by proposing aspects of comparison, followed by generating textual comparisons under each aspect. We select consistent comparisons with a pairwise consistency comparator that ensures each aspect's comparisons clearly distinguish differences between texts, significantly reducing hallucination and improving consistency. Our comprehensive evaluations across various NLP tasks, including summarization, retrieval, and automatic rating, demonstrate that SC equips LLMs to achieve state-of-the-art performance in text preference prediction.
Create account to get full access
Overview
- This paper introduces a new prompting approach called SC (Structured Comparison) that helps large language models (LLMs) make more consistent and accurate text preference predictions.
- Current LLM approaches, like Chain-of-Thought, struggle to consistently distinguish similarities and differences between complex texts.
- SC generates structured intermediate comparisons to predict text preferences, which significantly reduces hallucination and improves consistency.
- Evaluations across various NLP tasks, including summarization, retrieval, and automatic rating, show SC achieves state-of-the-art performance in text preference prediction.
Plain English Explanation
Comparing and contrasting different texts is a crucial skill, but large language models often have trouble doing this consistently. The paper introduces a new approach called SC that aims to improve on this.
SC works by first identifying key aspects to compare between texts, and then generating detailed textual comparisons for each aspect. A special component ensures the comparisons are consistent and clearly highlight the differences between the texts. This helps the language model make more reliable and accurate predictions about which text a person might prefer.
The researchers tested SC on various language tasks like summarization, search, and rating texts. They found that SC allows language models to achieve the best results so far on predicting text preferences. This could be useful in all kinds of applications where understanding the differences between texts is important, like search engines, recommendation systems, or assistants helping humans make complex comparisons.
Technical Explanation
The paper presents SC (Structured Comparison), a novel prompting approach that enables large language models (LLMs) to make more consistent and accurate text preference predictions.
The core idea of SC is to generate structured intermediate comparisons between texts, rather than relying on the LLM to directly infer preferences. SC first proposes a set of aspects to compare between the texts, such as tone, structure, or key points. It then generates textual comparisons for each aspect, ensuring the comparisons are consistent and clearly distinguish the differences between the texts.
This process is facilitated by a pairwise consistency comparator, which selects the most coherent and distinguishing comparisons. This component helps reduce hallucination and improve the overall consistency of the model's reasoning, which is a common challenge for LLMs as noted in prior work.
The researchers evaluate SC across a range of NLP tasks, including summarization, retrieval, and automatic text rating. The results show that SC enables LLMs to achieve state-of-the-art performance in text preference prediction, significantly outperforming previous approaches.
Critical Analysis
The paper presents a compelling solution to the challenge of getting LLMs to reason more consistently about text preferences. The structured comparison approach is a clever way to scaffold the model's decision-making process and reduce hallucination.
That said, the evaluations focus on relatively constrained tasks like summarization and rating. It would be interesting to see how SC performs on more open-ended, real-world text comparison scenarios that humans face, where the differences between texts may be more subtle or subjective.
Additionally, the paper does not provide much insight into the specific types of comparisons the model is generating or how it determines the "aspects" to compare. More transparency around these internal mechanisms could help researchers understand the model's reasoning in greater depth.
Overall, the SC approach is a valuable contribution to the challenge of modeling comparative logical reasoning in language models. Further research exploring its limitations and potential extensions could yield important advances in this important area.
Conclusion
This paper introduces SC, a novel prompting approach that enables large language models to make more consistent and accurate text preference predictions. By generating structured intermediate comparisons between texts, SC helps reduce hallucination and improve the overall coherence of the model's reasoning.
The researchers' comprehensive evaluations demonstrate that SC achieves state-of-the-art performance across a range of NLP tasks, suggesting it could be a valuable tool for applications that require reliable text comparison capabilities. As language models continue to grow in power and influence, approaches like SC will be crucial for ensuring they can reason about complex textual information in a trustworthy and transparent manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
New!Calibrating LLMs with Preference Optimization on Thought Trees for Generating Rationale in Science Question Scoring
Jiazheng Li, Hainiu Xu, Zhaoyue Sun, Yuxiang Zhou, David West, Cesare Aloisi, Yulan He
0
0
Generating rationales that justify scoring decisions has been a promising way to facilitate explainability in automated scoring systems. However, existing methods do not match the accuracy of classifier-based methods. Plus, the generated rationales often contain hallucinated information. To address these issues, we propose a novel framework capable of generating more faithful rationales and, more importantly, matching performance with classifier-based black-box scoring systems. We first mimic the human assessment process by querying Large Language Models (LLMs) to generate a thought tree. We then summarise intermediate assessment decisions from each thought tree path for creating synthetic rationale data and rationale preference data. Finally, we utilise the generated synthetic data to calibrate LLMs through a two-step training process: supervised fine-tuning and preference optimization. Extensive experimental results demonstrate that our framework achieves a 38% assessment performance improvement in the QWK score compared to prior work while producing higher-quality rationales, as recognised by human evaluators and LLMs. Our work sheds light on the effectiveness of performing preference optimization using synthetic preference data obtained from thought tree paths.
7/1/2024

PORT: Preference Optimization on Reasoning Traces
Salem Lahlou, Abdalgader Abubaker, Hakim Hacid
0
0
Preference optimization methods have been successfully applied to improve not only the alignment of large language models (LLMs) with human values, but also specific natural language tasks such as summarization and stylistic continuations. This paper proposes using preference optimization methods on Chain-of-Thought steps in order to improve the reasoning performances of language models. While the chosen answers are obtained from datasets that include reasoning traces, we propose two complementary schemes for generating rejected answers: digit corruption, and weak LLM prompting. Our approach leads to increased accuracy on the GSM8K, AQuA-RAT, and ARC benchmarks for Falcon2-11B and Mistral-7B. For example, the approach can lead to up to a relative 8.47% increase in accuracy on the GSM8K benchmark without any extra annotations. This work suggests that spending resources on creating more datasets of reasoning traces would further boost LLM performances on informal reasoning tasks.
6/26/2024

Modeling Comparative Logical Relation with Contrastive Learning for Text Generation
Yuhao Dan, Junfeng Tian, Jie Zhou, Ming Yan, Ji Zhang, Qin Chen, Liang He
0
0
Data-to-Text Generation (D2T), a classic natural language generation problem, aims at producing fluent descriptions for structured input data, such as a table. Existing D2T works mainly focus on describing the superficial associative relations among entities, while ignoring the deep comparative logical relations, such as A is better than B in a certain aspect with a corresponding opinion, which is quite common in our daily life. In this paper, we introduce a new D2T task named comparative logical relation generation (CLRG). Additionally, we propose a Comparative Logic (CoLo) based text generation method, which generates texts following specific comparative logical relations with contrastive learning. Specifically, we first construct various positive and negative samples by fine-grained perturbations in entities, aspects and opinions. Then, we perform contrastive learning in the encoder layer to have a better understanding of the comparative logical relations, and integrate it in the decoder layer to guide the model to correctly generate the relations. Noting the data scarcity problem, we construct a Chinese Comparative Logical Relation Dataset (CLRD), which is a high-quality human-annotated dataset and challenging for text generation with descriptions of multiple entities and annotations on their comparative logical relations. Extensive experiments show that our method achieves impressive performance in both automatic and human evaluations.
6/14/2024
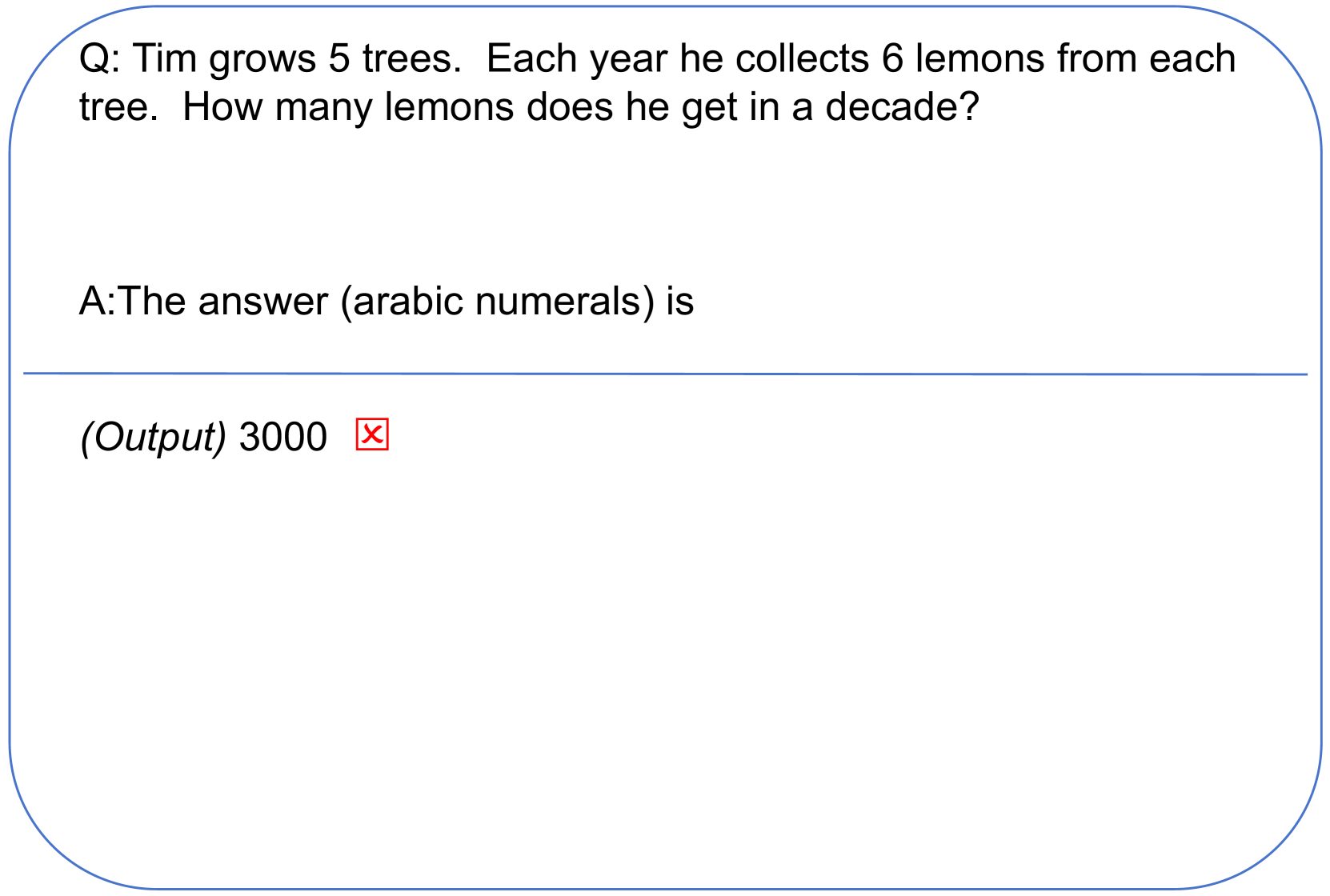
Large Language Models are Contrastive Reasoners
Liang Yao
0
0
Prompting methods play a crucial role in enhancing the capabilities of pre-trained large language models (LLMs). We explore how contrastive prompting (CP) significantly improves the ability of large language models to perform complex reasoning. We demonstrate that LLMs are decent contrastive reasoners by simply adding Let's give a correct and a wrong answer. before LLMs provide answers. Experiments on various large language models show that zero-shot contrastive prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks without any hand-crafted few-shot examples, such as increasing the accuracy on GSM8K from 35.9% to 88.8% and AQUA-RAT from 41.3% to 62.2% with the state-of-the-art GPT-4 model. Our method not only surpasses zero-shot CoT and few-shot CoT in most arithmetic and commonsense reasoning tasks but also can seamlessly integrate with existing prompting methods, resulting in improved or comparable results when compared to state-of-the-art methods. Our code is available at https://github.com/yao8839836/cp
5/24/2024