Large Language Models are Contrastive Reasoners
2403.08211
0
0
Abstract
Prompting methods play a crucial role in enhancing the capabilities of pre-trained large language models (LLMs). We explore how contrastive prompting (CP) significantly improves the ability of large language models to perform complex reasoning. We demonstrate that LLMs are decent contrastive reasoners by simply adding Let's give a correct and a wrong answer. before LLMs provide answers. Experiments on various large language models show that zero-shot contrastive prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks without any hand-crafted few-shot examples, such as increasing the accuracy on GSM8K from 35.9% to 88.8% and AQUA-RAT from 41.3% to 62.2% with the state-of-the-art GPT-4 model. Our method not only surpasses zero-shot CoT and few-shot CoT in most arithmetic and commonsense reasoning tasks but also can seamlessly integrate with existing prompting methods, resulting in improved or comparable results when compared to state-of-the-art methods. Our code is available at https://github.com/yao8839836/cp
Create account to get full access
Overview
- This paper explores the contrastive reasoning capabilities of large language models (LLMs), which are AI systems trained on vast amounts of text data to generate human-like language.
- The authors argue that LLMs are fundamentally different from traditional machine learning models, as they can engage in contrastive reasoning - the ability to compare and contrast different possibilities to arrive at the most plausible conclusion.
- The paper investigates how LLMs' contrastive reasoning abilities can be leveraged for improved performance on various tasks, such as question answering, problem-solving, and prompt learning.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can generate human-like text. Unlike traditional machine learning models, which are trained on specific datasets, LLMs are trained on vast amounts of text from the internet, books, and other sources. This allows them to develop a deep understanding of language and the world, and to engage in a process called "contrastive reasoning."
Contrastive reasoning means that LLMs can consider multiple possible answers or solutions to a problem, and then compare and contrast them to determine the most plausible one. For example, if you asked an LLM a question like "What is the capital of France?", the LLM would not just give a single answer, but would consider several possible options (Paris, London, Berlin, etc.) and then choose the one that best fits the context and information it has learned.
This ability to engage in contrastive reasoning is what sets LLMs apart from other AI systems, and the authors of this paper argue that it can be leveraged to improve the models' performance on a wide range of tasks. For example, LLMs have been shown to be particularly good at learning new tasks from just a few examples, a process called "prompt learning".
Technical Explanation
The paper presents a comprehensive analysis of the contrastive reasoning capabilities of large language models (LLMs). The authors argue that LLMs are fundamentally different from traditional machine learning models, as they engage in a process of "contrastive reasoning" - the ability to consider multiple possible answers or solutions to a problem, and then compare and contrast them to determine the most plausible one.
To investigate this, the researchers conducted a series of experiments that tested LLMs' performance on various tasks, including question answering, problem-solving, and prompt learning. The results showed that LLMs consistently outperformed traditional machine learning models on these tasks, suggesting that their contrastive reasoning abilities are a key driver of their success.
The authors also explored the potential applications of LLMs' contrastive reasoning capabilities, such as enhancing the capabilities of general-purpose AI agents and evaluating their ability to reason about interventions and causal relationships. These insights have important implications for the development of more capable and versatile AI systems.
Critical Analysis
The paper presents a compelling argument for the importance of contrastive reasoning in the development of large language models, and the authors have done a commendable job of designing and executing a rigorous set of experiments to support their claims.
One potential limitation of the study is that it focuses primarily on language-based tasks, such as question answering and problem-solving. While these are certainly important areas of application for LLMs, it would be interesting to see how the models' contrastive reasoning capabilities might translate to other domains, such as visual or multimodal reasoning.
Additionally, the paper does not delve deeply into the underlying mechanisms that enable LLMs to engage in contrastive reasoning. A more thorough investigation of the architectural and training-related factors that contribute to this capability could provide valuable insights for the field of AI.
Despite these minor caveats, the paper makes a strong case for the significance of contrastive reasoning in the continued advancement of large language models. The findings presented here have important implications for the development of more capable and versatile AI systems that can better understand and reason about the world around them.
Conclusion
This paper provides a compelling exploration of the contrastive reasoning capabilities of large language models (LLMs), which are a rapidly evolving and increasingly influential branch of artificial intelligence. The authors make a convincing argument that LLMs' ability to engage in contrastive reasoning - the process of considering multiple possible answers or solutions and then comparing and contrasting them to arrive at the most plausible conclusion - is a key driver of their success on a wide range of tasks.
The insights presented in this paper have significant implications for the future development of AI systems, as they suggest that incorporating contrastive reasoning capabilities could lead to more capable, versatile, and human-like AI agents. By leveraging the power of LLMs' contrastive reasoning, researchers and engineers may be able to create AI systems that can better understand and reason about the world, and thus make more informed and impactful decisions.
As the field of AI continues to evolve, the findings and ideas explored in this paper will likely play an important role in shaping the direction of future research and development. By delving deeper into the mechanisms that enable contrastive reasoning in LLMs, and exploring its applications across a wider range of domains, the scientific community can work towards the creation of AI systems that can truly rival and even surpass human-level intelligence and reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
CELL your Model: Contrastive Explanation Methods for Large Language Models
Ronny Luss, Erik Miehling, Amit Dhurandhar
0
0
The advent of black-box deep neural network classification models has sparked the need to explain their decisions. However, in the case of generative AI such as large language models (LLMs), there is no class prediction to explain. Rather, one can ask why an LLM output a particular response to a given prompt. In this paper, we answer this question by proposing, to the best of our knowledge, the first contrastive explanation methods requiring simply black-box/query access. Our explanations suggest that an LLM outputs a reply to a given prompt because if the prompt was slightly modified, the LLM would have given a different response that is either less preferable or contradicts the original response. The key insight is that contrastive explanations simply require a distance function that has meaning to the user and not necessarily a real valued representation of a specific response (viz. class label). We offer two algorithms for finding contrastive explanations: i) A myopic algorithm, which although effective in creating contrasts, requires many model calls and ii) A budgeted algorithm, our main algorithmic contribution, which intelligently creates contrasts adhering to a query budget, necessary for longer contexts. We show the efficacy of these methods on diverse natural language tasks such as open-text generation, automated red teaming, and explaining conversational degradation.
6/18/2024
💬
Active Prompting with Chain-of-Thought for Large Language Models
Shizhe Diao, Pengcheng Wang, Yong Lin, Tong Zhang
0
0
The increasing scale of large language models (LLMs) brings emergent abilities to various complex tasks requiring reasoning, such as arithmetic and commonsense reasoning. It is known that the effective design of task-specific prompts is critical for LLMs' ability to produce high-quality answers. In particular, an effective approach for complex question-and-answer tasks is example-based prompting with chain-of-thought (CoT) reasoning, which significantly improves the performance of LLMs. However, current CoT methods rely on a fixed set of human-annotated exemplars, which are not necessarily the most effective examples for different tasks. This paper proposes a new method, Active-Prompt, to adapt LLMs to different tasks with task-specific example prompts (annotated with human-designed CoT reasoning). For this purpose, we propose a solution to the key problem of determining which questions are the most important and helpful ones to annotate from a pool of task-specific queries. By borrowing ideas from the related problem of uncertainty-based active learning, we introduce several metrics to characterize the uncertainty so as to select the most uncertain questions for annotation. Experimental results demonstrate the superiority of our proposed method, achieving state-of-the-art on eight complex reasoning tasks. Further analyses of different uncertainty metrics, pool sizes, zero-shot learning, and accuracy-uncertainty relationship demonstrate the effectiveness of our method. Our code will be available at https://github.com/shizhediao/active-prompt.
6/10/2024
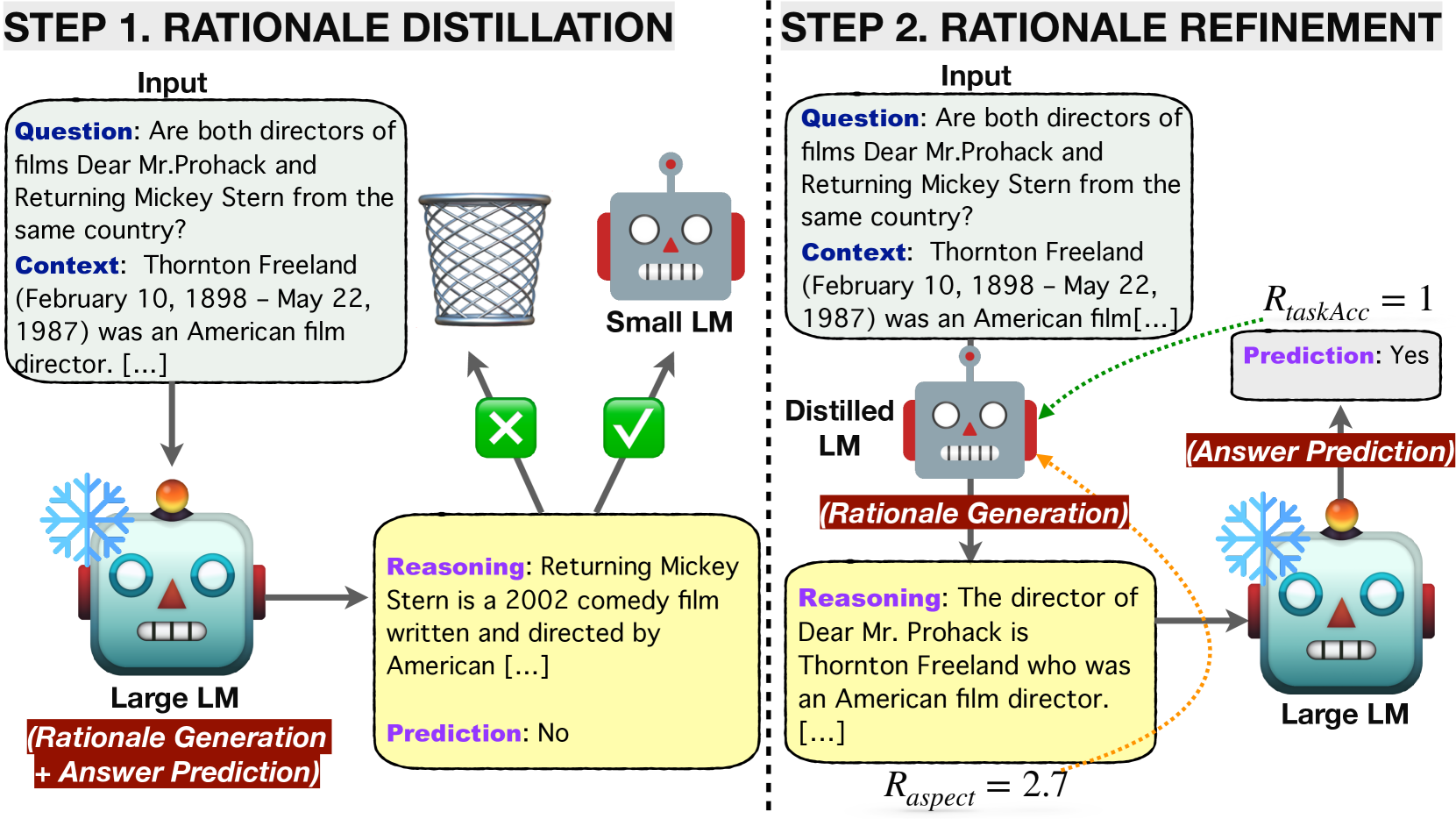
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024
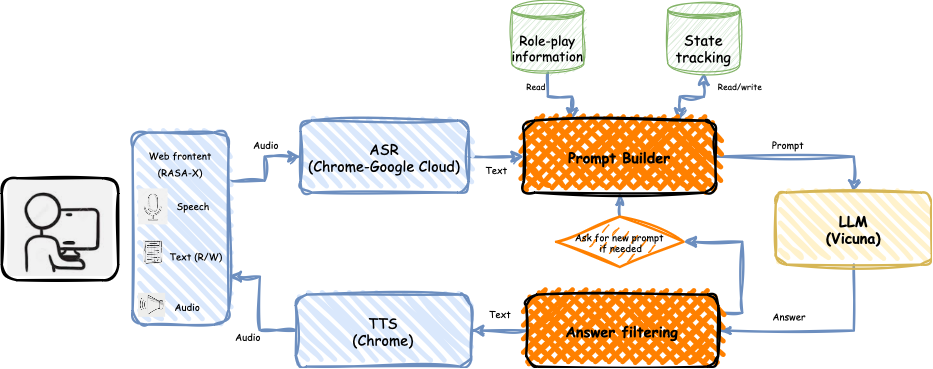
Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
Ahmed Njifenjou, Virgile Sucal, Bassam Jabaian, Fabrice Lef`evre
0
0
Recently, various methods have been proposed to create open-domain conversational agents with Large Language Models (LLMs). These models are able to answer user queries, but in a one-way Q&A format rather than a true conversation. Fine-tuning on particular datasets is the usual way to modify their style to increase conversational ability, but this is expensive and usually only available in a few languages. In this study, we explore role-play zero-shot prompting as an efficient and cost-effective solution for open-domain conversation, using capable multilingual LLMs (Beeching et al., 2023) trained to obey instructions. We design a prompting system that, when combined with an instruction-following model - here Vicuna (Chiang et al., 2023) - produces conversational agents that match and even surpass fine-tuned models in human evaluation in French in two different tasks.
6/27/2024