Preference-Optimized Pareto Set Learning for Blackbox Optimization

0

Sign in to get full access
Overview
- This research paper introduces a new approach called Preference-Optimized Pareto Set Learning (POPSL) for solving blackbox optimization problems with multiple objectives.
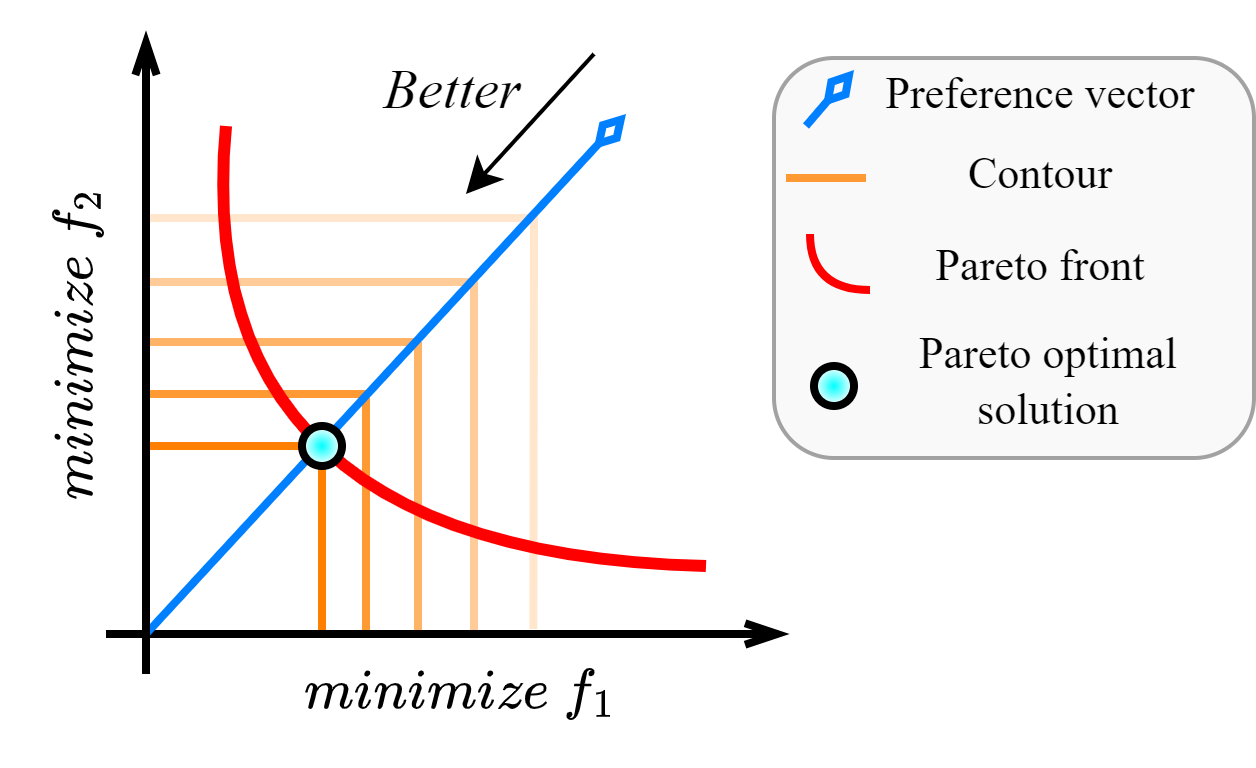
- The key idea is to learn a Pareto set that best matches a user's preferences, rather than aiming for a diverse Pareto front.
- The proposed method uses a Gaussian process surrogate model and a preference-based acquisition function to efficiently explore the search space and identify the optimal Pareto set.
Plain English Explanation
In many real-world optimization problems, there are often multiple goals or objectives that need to be balanced, such as cost, performance, and environmental impact. Pareto optimization is a well-known approach for handling these types of multi-objective problems, where the goal is to find a set of solutions (the Pareto set) that represent the best tradeoffs between the different objectives.
However, in practice, users often have specific preferences or priorities among the objectives, and may not be interested in the full Pareto front. The Preference-Optimized Pareto Set Learning (POPSL) method addresses this by learning a Pareto set that best matches the user's preferences, rather than trying to capture the entire Pareto front.
The key idea is to use a Gaussian process surrogate model to efficiently explore the search space and identify the optimal Pareto set, guided by a preference-based acquisition function. This allows the algorithm to focus its exploration on the regions of the Pareto set that are most relevant to the user's preferences, rather than wasting time and resources on parts of the Pareto front that the user does not care about.
By tailoring the Pareto set to the user's preferences, POPSL can provide more actionable and meaningful solutions for real-world optimization problems, where the decision-maker's priorities may not align with the entire Pareto front.
Technical Explanation
The Preference-Optimized Pareto Set Learning (POPSL) method builds upon the Gaussian process-based framework for multi-objective optimization, where a surrogate model is used to approximate the blackbox objective functions.
The key innovation of POPSL is the introduction of a preference-based acquisition function, which guides the exploration of the search space towards the regions of the Pareto set that best match the user's preferences. This is in contrast to traditional Pareto optimization approaches, which aim to capture the entire Pareto front without considering the decision-maker's priorities.
The preference-based acquisition function is designed to balance exploration (to discover new promising solutions) and exploitation (to refine the Pareto set based on the user's preferences). This is achieved by combining a traditional multi-objective acquisition function, such as the Hypervolume Improvement, with a preference function that encodes the user's priorities among the different objectives.
The POPSL algorithm iteratively updates the Gaussian process surrogate model and the Pareto set based on the preference-based acquisition function. This allows the method to efficiently explore the search space and identify the Pareto set that best aligns with the user's preferences, without the need to explore the entire Pareto front.
The authors demonstrate the effectiveness of POPSL on a range of synthetic and real-world multi-objective optimization problems, where it outperforms traditional Pareto optimization approaches in terms of both solution quality and computational efficiency.
Critical Analysis
The Preference-Optimized Pareto Set Learning (POPSL) method represents a promising approach for solving multi-objective optimization problems, particularly in scenarios where the decision-maker has clear preferences among the different objectives.
One key strength of POPSL is its ability to focus the optimization process on the most relevant regions of the Pareto set, which can lead to significant improvements in computational efficiency and solution quality compared to traditional Pareto optimization methods.
However, the success of POPSL relies on the accuracy of the user's preferences, which may be difficult to elicit or may change over time. The paper does not address how to handle cases where the user's preferences are uncertain or evolve during the optimization process.
Additionally, the paper does not provide a comprehensive analysis of the limitations of POPSL, such as its performance on high-dimensional problems or its ability to handle non-continuous or highly multimodal Pareto fronts.
Further research could explore ways to make POPSL more robust to uncertainties in the user's preferences, as well as investigate its scalability and generalization to a wider range of multi-objective optimization problems.
Conclusion
The Preference-Optimized Pareto Set Learning (POPSL) method represents a significant advancement in the field of multi-objective optimization by focusing the search process on the regions of the Pareto set that are most relevant to the user's preferences.
By leveraging a Gaussian process surrogate model and a preference-based acquisition function, POPSL is able to efficiently explore the search space and identify the optimal Pareto set, without the need to capture the entire Pareto front.
This approach has the potential to improve the practical applicability of multi-objective optimization in a wide range of domains, where decision-makers need to balance multiple, often conflicting objectives. The ability to tailor the Pareto set to the user's preferences can lead to more actionable and meaningful solutions, which can have a significant impact on real-world optimization problems.
However, further research is needed to address the limitations of POPSL, such as its sensitivity to uncertainty in the user's preferences and its scalability to high-dimensional problems. Nonetheless, this paper represents an important step forward in the field of multi-objective optimization and demonstrates the value of incorporating user preferences into the optimization process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Preference-Optimized Pareto Set Learning for Blackbox Optimization
Zhang Haishan, Diptesh Das, Koji Tsuda
Multi-Objective Optimization (MOO) is an important problem in real-world applications. However, for a non-trivial problem, no single solution exists that can optimize all the objectives simultaneously. In a typical MOO problem, the goal is to find a set of optimum solutions (Pareto set) that trades off the preferences among objectives. Scalarization in MOO is a well-established method for finding a finite set approximation of the whole Pareto set (PS). However, in real-world experimental design scenarios, it's beneficial to obtain the whole PS for flexible exploration of the design space. Recently Pareto set learning (PSL) has been introduced to approximate the whole PS. PSL involves creating a manifold representing the Pareto front of a multi-objective optimization problem. A naive approach includes finding discrete points on the Pareto front through randomly generated preference vectors and connecting them by regression. However, this approach is computationally expensive and leads to a poor PS approximation. We propose to optimize the preference points to be distributed evenly on the Pareto front. Our formulation leads to a bilevel optimization problem that can be solved by e.g. differentiable cross-entropy methods. We demonstrated the efficacy of our method for complex and difficult black-box MOO problems using both synthetic and real-world benchmark data.
Read more8/20/2024

0
Collaborative Pareto Set Learning in Multiple Multi-Objective Optimization Problems
Chikai Shang, Rongguang Ye, Jiaqi Jiang, Fangqing Gu
Pareto Set Learning (PSL) is an emerging research area in multi-objective optimization, focusing on training neural networks to learn the mapping from preference vectors to Pareto optimal solutions. However, existing PSL methods are limited to addressing a single Multi-objective Optimization Problem (MOP) at a time. When faced with multiple MOPs, this limitation results in significant inefficiencies and hinders the ability to exploit potential synergies across varying MOPs. In this paper, we propose a Collaborative Pareto Set Learning (CoPSL) framework, which learns the Pareto sets of multiple MOPs simultaneously in a collaborative manner. CoPSL particularly employs an architecture consisting of shared and MOP-specific layers. The shared layers are designed to capture commonalities among MOPs collaboratively, while the MOP-specific layers tailor these general insights to generate solution sets for individual MOPs. This collaborative approach enables CoPSL to efficiently learn the Pareto sets of multiple MOPs in a single execution while leveraging the potential relationships among various MOPs. To further understand these relationships, we experimentally demonstrate that shareable representations exist among MOPs. Leveraging these shared representations effectively improves the capability to approximate Pareto sets. Extensive experiments underscore the superior efficiency and robustness of CoPSL in approximating Pareto sets compared to state-of-the-art approaches on a variety of synthetic and real-world MOPs. Code is available at https://github.com/ckshang/CoPSL.
Read more4/30/2024
0
Pareto Front Shape-Agnostic Pareto Set Learning in Multi-Objective Optimization
Rongguang Ye, Longcan Chen, Wei-Bin Kou, Jinyuan Zhang, Hisao Ishibuchi
Pareto set learning (PSL) is an emerging approach for acquiring the complete Pareto set of a multi-objective optimization problem. Existing methods primarily rely on the mapping of preference vectors in the objective space to Pareto optimal solutions in the decision space. However, the sampling of preference vectors theoretically requires prior knowledge of the Pareto front shape to ensure high performance of the PSL methods. Designing a sampling strategy of preference vectors is difficult since the Pareto front shape cannot be known in advance. To make Pareto set learning work effectively in any Pareto front shape, we propose a Pareto front shape-agnostic Pareto Set Learning (GPSL) that does not require the prior information about the Pareto front. The fundamental concept behind GPSL is to treat the learning of the Pareto set as a distribution transformation problem. Specifically, GPSL can transform an arbitrary distribution into the Pareto set distribution. We demonstrate that training a neural network by maximizing hypervolume enables the process of distribution transformation. Our proposed method can handle any shape of the Pareto front and learn the Pareto set without requiring prior knowledge. Experimental results show the high performance of our proposed method on diverse test problems compared with recent Pareto set learning algorithms.
Read more8/13/2024

0
Expensive Multi-Objective Bayesian Optimization Based on Diffusion Models
Bingdong Li, Zixiang Di, Yongfan Lu, Hong Qian, Feng Wang, Peng Yang, Ke Tang, Aimin Zhou
Multi-objective Bayesian optimization (MOBO) has shown promising performance on various expensive multi-objective optimization problems (EMOPs). However, effectively modeling complex distributions of the Pareto optimal solutions is difficult with limited function evaluations. Existing Pareto set learning algorithms may exhibit considerable instability in such expensive scenarios, leading to significant deviations between the obtained solution set and the Pareto set (PS). In this paper, we propose a novel Composite Diffusion Model based Pareto Set Learning algorithm, namely CDM-PSL, for expensive MOBO. CDM-PSL includes both unconditional and conditional diffusion model for generating high-quality samples. Besides, we introduce an information entropy based weighting method to balance different objectives of EMOPs. This method is integrated with the guiding strategy, ensuring that all the objectives are appropriately balanced and given due consideration during the optimization process; Extensive experimental results on both synthetic benchmarks and real-world problems demonstrates that our proposed algorithm attains superior performance compared with various state-of-the-art MOBO algorithms.
Read more5/15/2024