A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?

1
Sign in to get full access
Overview
- This paper presents a preliminary study on the potential use of the AI model o1 in the medical field.
- The study explores whether o1 can be developed into an "AI doctor" capable of assisting or even replacing human physicians.
- Key areas examined include diagnosis, treatment recommendations, and interactions with patients.
Plain English Explanation
The research paper explores the possibility of using a powerful AI model called o1 to assist or even replace human doctors in the medical field. The researchers want to see if o1 can be developed into an "AI doctor" that can accurately diagnose patients, recommend appropriate treatments, and interact with patients in a natural way.
The study looks at several key areas where o1 could be applied in medicine, such as making diagnoses and suggesting treatments. The researchers also examine how well o1 can communicate with patients and understand their needs.
Overall, the goal is to determine if o1 has the potential to revolutionize the medical field by taking on tasks traditionally performed by human doctors. If successful, this could lead to more efficient and accessible healthcare, but also raises important ethical questions about the role of AI in sensitive areas like medicine.
Technical Explanation
The paper presents a preliminary study on the use of the large language model o1 in the medical domain. The researchers investigate whether o1 can be developed into an "AI doctor" capable of diagnosing patients, recommending treatments, and interacting with patients in a natural way.
The study design includes several experiments to evaluate o1's performance on medical tasks. This includes assessing its ability to make accurate diagnoses based on patient symptoms and recommend appropriate treatments. The researchers also test o1's conversational capabilities to gauge how well it can interact with patients.
The findings suggest that o1 shows promise in certain medical tasks, but also has limitations that would need to be addressed before it could be deployed as a full-fledged "AI doctor". The paper discusses the implications of this research and potential future directions.
Critical Analysis
The paper provides a thoughtful and nuanced assessment of the strengths and limitations of using o1 in the medical domain. While the results are promising in some areas, the researchers acknowledge the challenges that would need to be overcome before o1 could be considered a viable replacement for human doctors.
One key limitation highlighted is o1's inability to fully understand the context and nuance of medical scenarios, which could lead to inaccurate diagnoses or inappropriate treatment recommendations. The ethical concerns around AI-powered medical decision-making are also an important consideration.
Overall, the researchers take a measured approach, acknowledging both the potential and the limitations of using o1 in the medical field. They encourage further research and development to address the identified challenges and explore the full capabilities of this technology.
Conclusion
This preliminary study on the use of the AI model o1 in medicine suggests that while the technology has promising applications, significant work is still needed before it could be considered a viable replacement for human doctors. The researchers found that o1 showed capabilities in diagnosis and treatment recommendations, but also limitations in understanding medical context and engaging with patients.
The implications of this research could be far-reaching, potentially leading to more efficient and accessible healthcare, but also raising important ethical concerns about the role of AI in sensitive domains. The researchers encourage further exploration of this technology, with a focus on addressing the identified challenges and developing a deeper understanding of its capabilities and limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?
Yunfei Xie, Juncheng Wu, Haoqin Tu, Siwei Yang, Bingchen Zhao, Yongshuo Zong, Qiao Jin, Cihang Xie, Yuyin Zhou
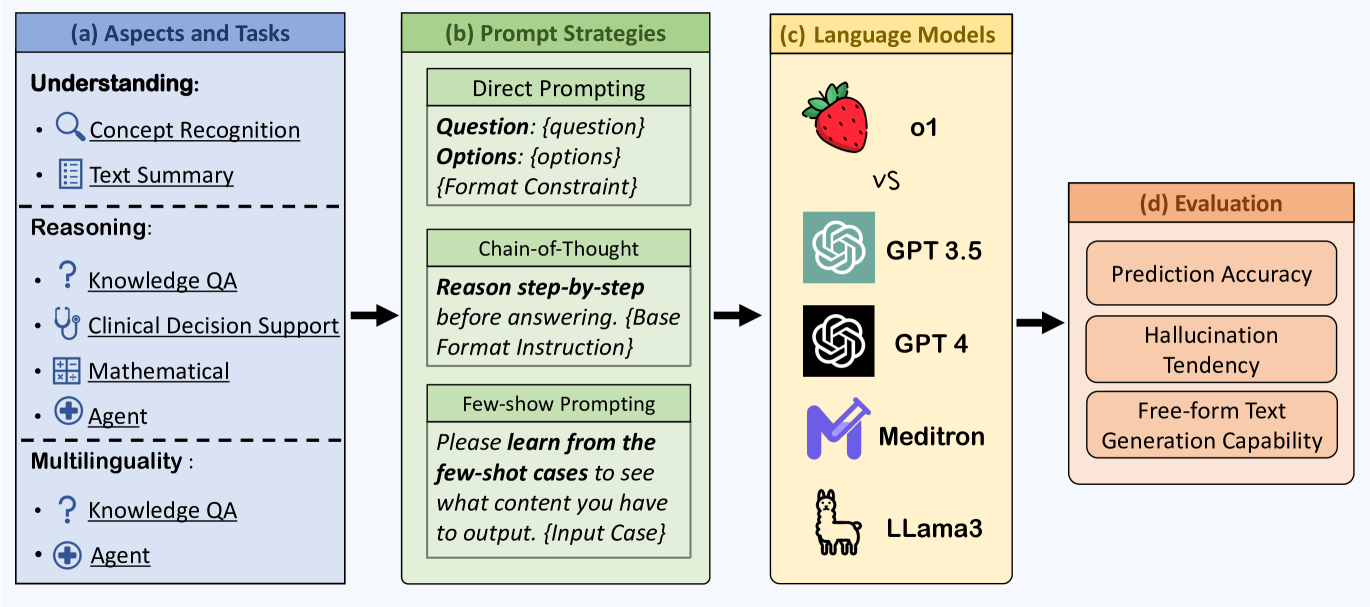
Large language models (LLMs) have exhibited remarkable capabilities across various domains and tasks, pushing the boundaries of our knowledge in learning and cognition. The latest model, OpenAI's o1, stands out as the first LLM with an internalized chain-of-thought technique using reinforcement learning strategies. While it has demonstrated surprisingly strong capabilities on various general language tasks, its performance in specialized fields such as medicine remains unknown. To this end, this report provides a comprehensive exploration of o1 on different medical scenarios, examining 3 key aspects: understanding, reasoning, and multilinguality. Specifically, our evaluation encompasses 6 tasks using data from 37 medical datasets, including two newly constructed and more challenging question-answering (QA) tasks based on professional medical quizzes from the New England Journal of Medicine (NEJM) and The Lancet. These datasets offer greater clinical relevance compared to standard medical QA benchmarks such as MedQA, translating more effectively into real-world clinical utility. Our analysis of o1 suggests that the enhanced reasoning ability of LLMs may (significantly) benefit their capability to understand various medical instructions and reason through complex clinical scenarios. Notably, o1 surpasses the previous GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios. But meanwhile, we identify several weaknesses in both the model capability and the existing evaluation protocols, including hallucination, inconsistent multilingual ability, and discrepant metrics for evaluation. We release our raw data and model outputs at https://ucsc-vlaa.github.io/o1_medicine/ for future research.
Read more9/24/2024
💬
0
MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, Mark Gerstein
Large language models (LLMs), despite their remarkable progress across various general domains, encounter significant barriers in medicine and healthcare. This field faces unique challenges such as domain-specific terminologies and reasoning over specialized knowledge. To address these issues, we propose MedAgents, a novel multi-disciplinary collaboration framework for the medical domain. MedAgents leverages LLM-based agents in a role-playing setting that participate in a collaborative multi-round discussion, thereby enhancing LLM proficiency and reasoning capabilities. This training-free framework encompasses five critical steps: gathering domain experts, proposing individual analyses, summarising these analyses into a report, iterating over discussions until a consensus is reached, and ultimately making a decision. Our work focuses on the zero-shot setting, which is applicable in real-world scenarios. Experimental results on nine datasets (MedQA, MedMCQA, PubMedQA, and six subtasks from MMLU) establish that our proposed MedAgents framework excels at mining and harnessing the medical expertise within LLMs, as well as extending its reasoning abilities. Our code can be found at https://github.com/gersteinlab/MedAgents.
Read more6/6/2024
🤖
0
AI Hospital: Benchmarking Large Language Models in a Multi-agent Medical Interaction Simulator
Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xi, Fei Huang, Jingren Zhou
Artificial intelligence has significantly advanced healthcare, particularly through large language models (LLMs) that excel in medical question answering benchmarks. However, their real-world clinical application remains limited due to the complexities of doctor-patient interactions. To address this, we introduce textbf{AI Hospital}, a multi-agent framework simulating dynamic medical interactions between emph{Doctor} as player and NPCs including emph{Patient}, emph{Examiner}, emph{Chief Physician}. This setup allows for realistic assessments of LLMs in clinical scenarios. We develop the Multi-View Medical Evaluation (MVME) benchmark, utilizing high-quality Chinese medical records and NPCs to evaluate LLMs' performance in symptom collection, examination recommendations, and diagnoses. Additionally, a dispute resolution collaborative mechanism is proposed to enhance diagnostic accuracy through iterative discussions. Despite improvements, current LLMs exhibit significant performance gaps in multi-turn interactions compared to one-step approaches. Our findings highlight the need for further research to bridge these gaps and improve LLMs' clinical diagnostic capabilities. Our data, code, and experimental results are all open-sourced at url{https://github.com/LibertFan/AI_Hospital}.
Read more7/1/2024

0
A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better patient privacy protection than API-based solutions. Given the above advantages, this survey systematically summarizes how to train medical LLMs based on open-source general LLMs from a more fine-grained perspective. It covers (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose an appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants. Related resources and supplemental information can be found on the GitHub repository.
Read more9/24/2024