Pretraining with Random Noise for Fast and Robust Learning without Weight Transport

0
Sign in to get full access
Overview
- Pretraining with random noise can lead to fast and robust learning without weight transport.
- This paper investigates the benefits of pretraining neural networks with random noise before fine-tuning on the target task.
- The key findings suggest that this approach can improve generalization and performance compared to standard pretraining methods.
Plain English Explanation
When training a machine learning model, researchers often use a technique called "pretraining" to give the model a head start. This involves training the model on a large, general dataset before fine-tuning it on the specific task they care about.
This paper explores a new twist on pretraining - instead of using real data, the researchers pretrain the model using random noise. The intuition is that by exposing the model to this noisy, chaotic input during pretraining, it can learn to be more robust and adaptable when faced with the real task.
The key advantage of this approach is that it doesn't require any labeled data for pretraining - the random noise is free and easy to generate. This could be especially helpful in domains where high-quality labeled data is scarce or expensive to obtain.
The researchers find that models pretrained on random noise can actually outperform those pretrained on real data, particularly when it comes to generalization - the ability to perform well on new, unseen examples. This suggests that the noise pretraining helps the model develop more flexible and powerful representations.
Another benefit is that this noise pretraining approach doesn't rely on "weight transport" - the process of carefully transferring learned weights from one part of the model to another. This makes the training process simpler and more efficient.
Technical Explanation
The paper begins by outlining the standard pretraining approach, where a neural network is first trained on a large, general dataset (like ImageNet) before being fine-tuned on the target task. The authors then introduce their proposed alternative: pretraining the model using random noise instead of real data.
To test this idea, the researchers conduct experiments across multiple datasets and model architectures. They find that models pretrained on random noise consistently outperform those pretrained on real data, both in terms of final performance and the speed of convergence during fine-tuning.
The authors hypothesize that the noise pretraining helps the model develop more robust and adaptable representations. By forcing the model to extract useful features from pure randomness, it becomes better equipped to handle the real-world complexities of the target task.
Importantly, the noise pretraining approach does not rely on weight transport - the process of carefully transferring learned weights from one part of the model to another. This makes the training pipeline simpler and more efficient, as the model can be fine-tuned directly without the need for complex weight initialization schemes.
Critical Analysis
The paper presents a compelling and well-designed study, with experiments spanning multiple datasets and architectures to demonstrate the generality of the findings. The authors are careful to acknowledge potential limitations, such as the need to further investigate the underlying mechanisms behind the performance improvements.
One area that could be explored further is the impact of the noise distribution - the paper uses i.i.d. Gaussian noise, but other types of structured noise may have different effects. Additionally, the authors do not delve deeply into the computational efficiency of the noise pretraining approach compared to standard pretraining methods.
Overall, this research offers a novel and promising direction for improving the speed and robustness of neural network training, with potential applications in domains where high-quality labeled data is scarce or difficult to obtain.
Conclusion
This paper introduces a novel pretraining approach that uses random noise instead of real data, and finds that it can lead to faster and more robust learning without the need for weight transport. The key insights suggest that exposing a neural network to this chaotic, noisy input during pretraining helps it develop more flexible and adaptable representations, which in turn boosts performance on the target task.
This work opens up new avenues for improving the efficiency and generalization capabilities of deep learning models, with potential applications in data-scarce domains or settings where rapid adaptation is crucial. As the field continues to explore the role of noise and uncertainty in machine learning, this paper provides an important contribution to our understanding of how to leverage these concepts for practical benefit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pretraining with Random Noise for Fast and Robust Learning without Weight Transport
Jeonghwan Cheon, Sang Wan Lee, Se-Bum Paik
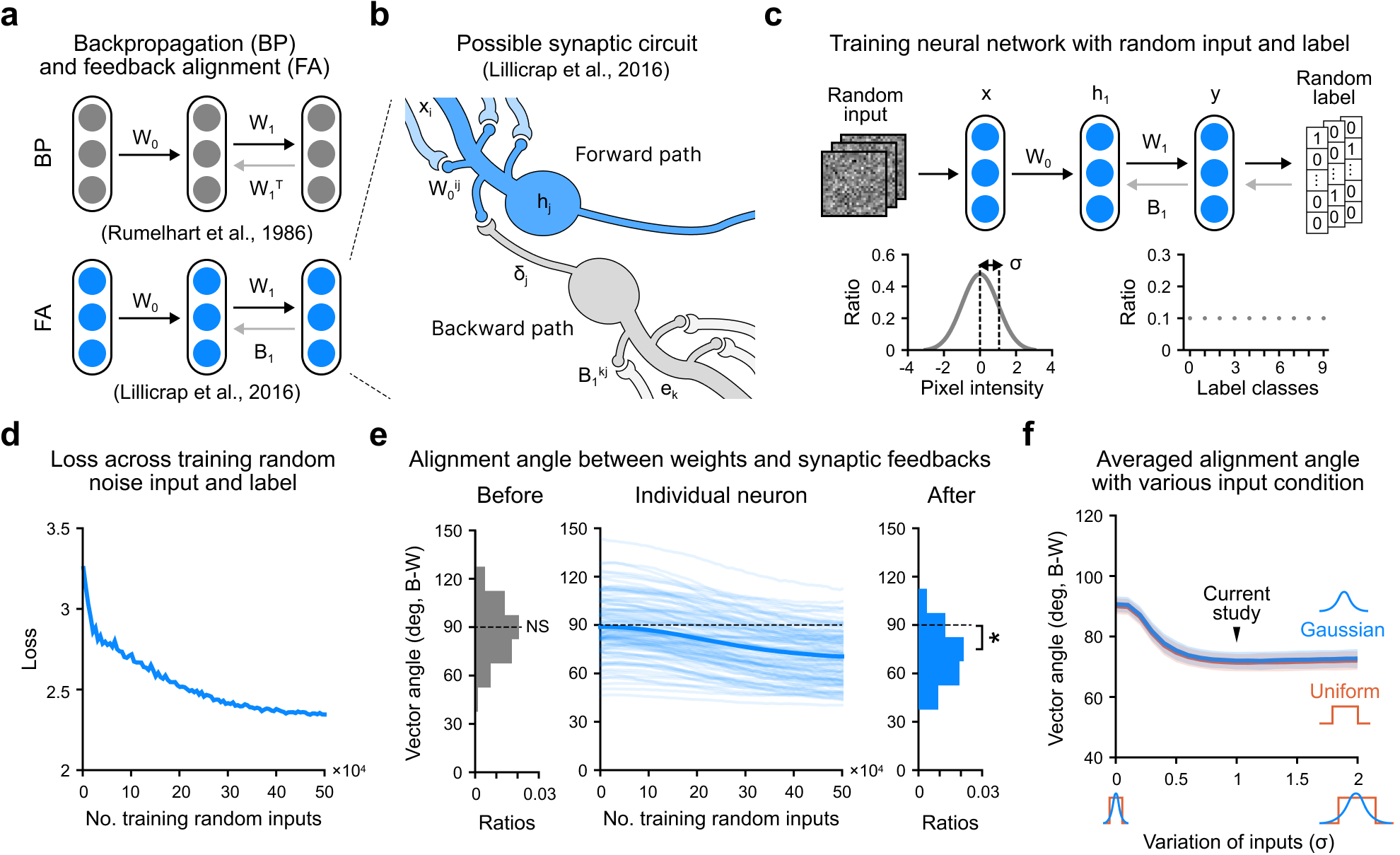
The brain prepares for learning even before interacting with the environment, by refining and optimizing its structures through spontaneous neural activity that resembles random noise. However, the mechanism of such a process has yet to be thoroughly understood, and it is unclear whether this process can benefit the algorithm of machine learning. Here, we study this issue using a neural network with a feedback alignment algorithm, demonstrating that pretraining neural networks with random noise increases the learning efficiency as well as generalization abilities without weight transport. First, we found that random noise training modifies forward weights to match backward synaptic feedback, which is necessary for teaching errors by feedback alignment. As a result, a network with pre-aligned weights learns notably faster than a network without random noise training, even reaching a convergence speed comparable to that of a backpropagation algorithm. Sequential training with both random noise and data brings weights closer to synaptic feedback than training solely with data, enabling more precise credit assignment and faster learning. We also found that each readout probability approaches the chance level and that the effective dimensionality of weights decreases in a network pretrained with random noise. This pre-regularization allows the network to learn simple solutions of a low rank, reducing the generalization loss during subsequent training. This also enables the network robustly to generalize a novel, out-of-distribution dataset. Lastly, we confirmed that random noise pretraining reduces the amount of meta-loss, enhancing the network ability to adapt to various tasks. Overall, our results suggest that random noise training with feedback alignment offers a straightforward yet effective method of pretraining that facilitates quick and reliable learning without weight transport.
Read more5/28/2024
🏋️
0
Training neural networks with structured noise improves classification and generalization
Marco Benedetti, Enrico Ventura
The beneficial role of noise-injection in learning is a consolidated concept in the field of artificial neural networks, suggesting that even biological systems might take advantage of similar mechanisms to optimize their performance. The training-with-noise algorithm proposed by Gardner and collaborators is an emblematic example of a noise-injection procedure in recurrent networks, which can be used to model biological neural systems. We show how adding structure to noisy training data can substantially improve the algorithm performance, allowing the network to approach perfect retrieval of the memories and wide basins of attraction, even in the scenario of maximal injected noise. We also prove that the so-called Hebbian Unlearning rule coincides with the training-with-noise algorithm when noise is maximal and data are stable fixed points of the network dynamics.
Read more4/1/2024
🤿
0
Rolling the dice for better deep learning performance: A study of randomness techniques in deep neural networks
Mohammed Ghaith Altarabichi, S{l}awomir Nowaczyk, Sepideh Pashami, Peyman Sheikholharam Mashhadi, Julia Handl
This paper investigates how various randomization techniques impact Deep Neural Networks (DNNs). Randomization, like weight noise and dropout, aids in reducing overfitting and enhancing generalization, but their interactions are poorly understood. The study categorizes randomness techniques into four types and proposes new methods: adding noise to the loss function and random masking of gradient updates. Using Particle Swarm Optimizer (PSO) for hyperparameter optimization, it explores optimal configurations across MNIST, FASHION-MNIST, CIFAR10, and CIFAR100 datasets. Over 30,000 configurations are evaluated, revealing data augmentation and weight initialization randomness as main performance contributors. Correlation analysis shows different optimizers prefer distinct randomization types. The complete implementation and dataset are available on GitHub.
Read more4/8/2024
🧠
0
Navigating Noise: A Study of How Noise Influences Generalisation and Calibration of Neural Networks
Martin Ferianc, Ondrej Bohdal, Timothy Hospedales, Miguel Rodrigues
Enhancing the generalisation abilities of neural networks (NNs) through integrating noise such as MixUp or Dropout during training has emerged as a powerful and adaptable technique. Despite the proven efficacy of noise in NN training, there is no consensus regarding which noise sources, types and placements yield maximal benefits in generalisation and confidence calibration. This study thoroughly explores diverse noise modalities to evaluate their impacts on NN's generalisation and calibration under in-distribution or out-of-distribution settings, paired with experiments investigating the metric landscapes of the learnt representations across a spectrum of NN architectures, tasks, and datasets. Our study shows that AugMix and weak augmentation exhibit cross-task effectiveness in computer vision, emphasising the need to tailor noise to specific domains. Our findings emphasise the efficacy of combining noises and successful hyperparameter transfer within a single domain but the difficulties in transferring the benefits to other domains. Furthermore, the study underscores the complexity of simultaneously optimising for both generalisation and calibration, emphasising the need for practitioners to carefully consider noise combinations and hyperparameter tuning for optimal performance in specific tasks and datasets.
Read more4/4/2024