Principled RLHF from Heterogeneous Feedback via Personalization and Preference Aggregation
2405.00254
0
0
Abstract
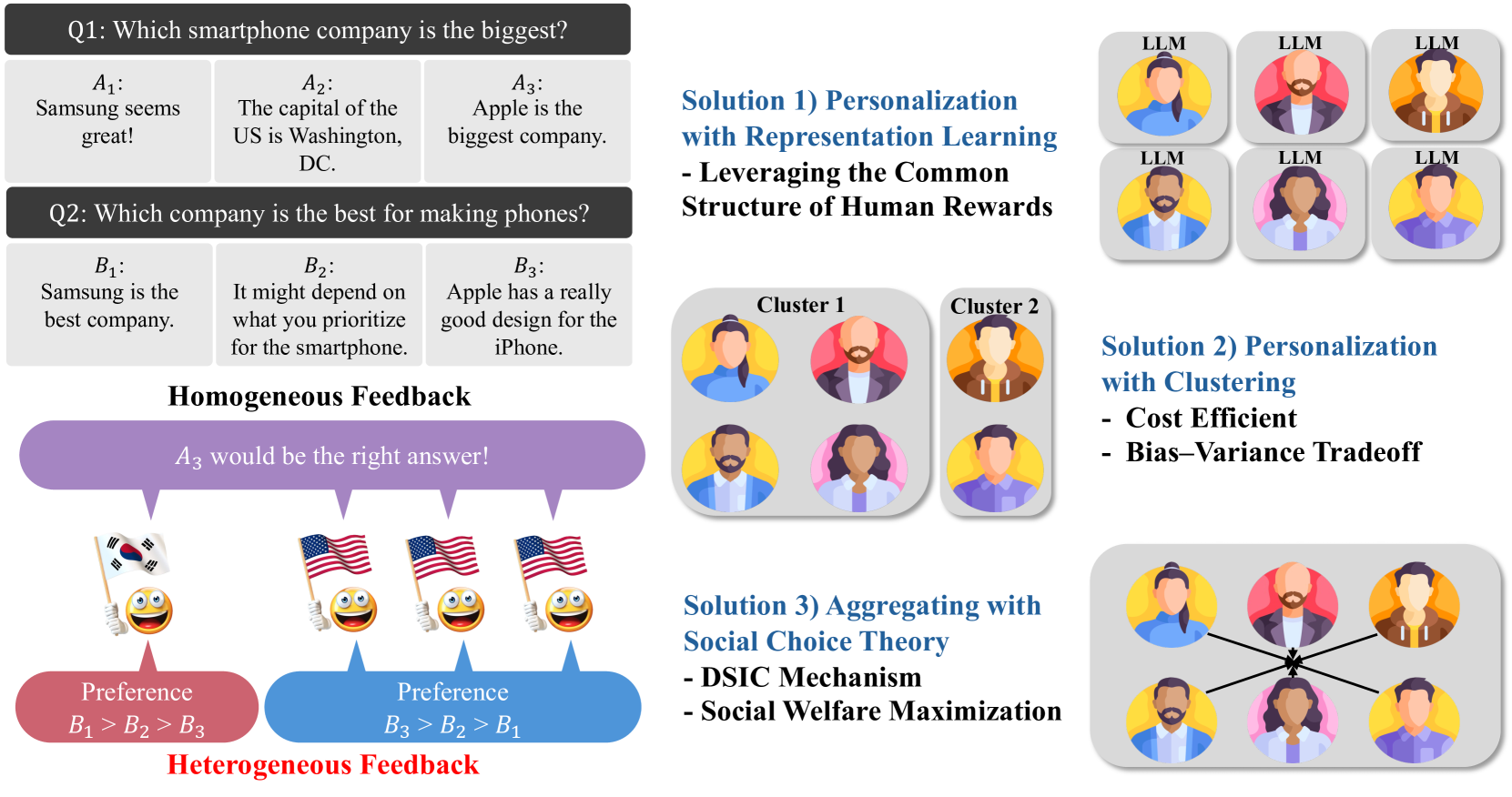
Reinforcement learning from human feedback (RLHF) has been an effective technique for aligning AI systems with human values, with remarkable successes in fine-tuning large-language models recently. Most existing RLHF paradigms make the underlying assumption that human preferences are relatively homogeneous, and can be encoded by a single reward model. In this paper, we focus on addressing the issues due to the inherent heterogeneity in human preferences, as well as their potential strategic behavior in providing feedback. Specifically, we propose two frameworks to address heterogeneous human feedback in principled ways: personalization-based one and aggregation-based one. For the former, we propose two approaches based on representation learning and clustering, respectively, for learning multiple reward models that trades off the bias (due to preference heterogeneity) and variance (due to the use of fewer data for learning each model by personalization). We then establish sample complexity guarantees for both approaches. For the latter, we aim to adhere to the single-model framework, as already deployed in the current RLHF paradigm, by carefully aggregating diverse and truthful preferences from humans. We propose two approaches based on reward and preference aggregation, respectively: the former utilizes both utilitarianism and Leximin approaches to aggregate individual reward models, with sample complexity guarantees; the latter directly aggregates the human feedback in the form of probabilistic opinions. Under the probabilistic-opinion-feedback model, we also develop an approach to handle strategic human labelers who may bias and manipulate the aggregated preferences with untruthful feedback. Based on the ideas in mechanism design, our approach ensures truthful preference reporting, with the induced aggregation rule maximizing social welfare functions.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper proposes a new approach to Reinforcement Learning from Human Feedback (RLHF) that addresses challenges with heterogeneous feedback and individual preferences.
- The key ideas are to personalize the learning process for each user and aggregate feedback from multiple users to learn a shared preference model.
- The authors conduct experiments to evaluate their approach and compare it to existing RLHF methods.
Plain English Explanation
This paper focuses on a technique called Reinforcement Learning from Human Feedback (RLHF), which is used to train AI systems by having humans provide feedback on the system's actions. The authors recognized that existing RLHF approaches have some limitations, such as not accounting for the fact that different people may have different preferences or ways of providing feedback.
To address this, the researchers developed a new RLHF method that personalizes the learning process for each individual user and also aggregates the feedback from multiple users to learn a shared preference model. The idea is that by understanding each user's unique preferences and combining feedback from many users, the AI system can learn to behave in a way that satisfies a wider range of people.
The researchers tested their new approach in experiments and compared it to other existing RLHF methods. Their results suggest that this personalized and aggregated approach can lead to better performance and more robust learning compared to previous techniques.
Technical Explanation
The key technical contributions of this paper are:
-
Personalized RLHF: The authors develop a method to personalize the RLHF process for each individual user, modeling their unique preferences and feedback patterns.
-
Preference Aggregation: They also introduce a technique to aggregate feedback from multiple users to learn a shared preference model, allowing the AI system to balance the needs and desires of a diverse user base.
-
Experimental Evaluation: The authors conduct experiments to assess the performance of their personalized and aggregated RLHF approach, comparing it to existing methods on a range of tasks.
The personalized RLHF component uses Bayesian inference to model each user's preferences, while the preference aggregation builds on techniques from social choice theory to combine the feedback signals. The experiments demonstrate that this principled approach can outperform standard RLHF methods, particularly in scenarios with heterogeneous user preferences.
Critical Analysis
The paper presents a well-reasoned and technically sound approach to addressing some of the key challenges in RLHF. However, there are a few potential limitations and areas for further research:
- The personalization and aggregation techniques rely on strong assumptions about the structure of user preferences and the feedback process. In practice, these assumptions may not always hold, and the performance could be sensitive to violations.
- The experiments are conducted in relatively simple, synthetic environments. More research is needed to understand how well the approach scales to real-world, complex scenarios with noisy and ambiguous human feedback.
- The paper does not address the potential ethical and societal implications of developing more powerful RLHF systems, such as concerns around fairness, transparency, and the broader impacts on human-AI interaction.
Overall, this research represents an important step forward in the field of RLHF, but continued work is needed to fully realize the potential of this approach and address its limitations.
Conclusion
This paper proposes a novel RLHF method that personalizes the learning process for each user and aggregates feedback from multiple users to learn a shared preference model. The key innovations are the personalization and preference aggregation components, which allow the AI system to better account for heterogeneous user feedback and individual differences in preferences.
The experimental results suggest that this principled approach can outperform existing RLHF techniques, particularly in scenarios with diverse user preferences. While the paper identifies some potential limitations, it represents an important step forward in developing more robust and effective RLHF systems. As the use of AI systems in high-stakes applications continues to grow, techniques like the one presented here will become increasingly crucial for ensuring these systems behave in alignment with human values and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024
🏅
A Survey of Reinforcement Learning from Human Feedback
Timo Kaufmann, Paul Weng, Viktor Bengs, Eyke Hullermeier
0
0
Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior work on the related setting of preference-based reinforcement learning (PbRL), it stands at the intersection of artificial intelligence and human-computer interaction. This positioning offers a promising avenue to enhance the performance and adaptability of intelligent systems while also improving the alignment of their objectives with human values. The training of large language models (LLMs) has impressively demonstrated this potential in recent years, where RLHF played a decisive role in directing the model's capabilities toward human objectives. This article provides a comprehensive overview of the fundamentals of RLHF, exploring the intricate dynamics between RL agents and human input. While recent focus has been on RLHF for LLMs, our survey adopts a broader perspective, examining the diverse applications and wide-ranging impact of the technique. We delve into the core principles that underpin RLHF, shedding light on the symbiotic relationship between algorithms and human feedback, and discuss the main research trends in the field. By synthesizing the current landscape of RLHF research, this article aims to provide researchers as well as practitioners with a comprehensive understanding of this rapidly growing field of research.
5/1/2024
📶
Contrastive Preference Learning: Learning from Human Feedback without RL
Joey Hejna, Rafael Rafailov, Harshit Sikchi, Chelsea Finn, Scott Niekum, W. Bradley Knox, Dorsa Sadigh
0
0
Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular paradigm for aligning models with human intent. Typically RLHF algorithms operate in two phases: first, use human preferences to learn a reward function and second, align the model by optimizing the learned reward via reinforcement learning (RL). This paradigm assumes that human preferences are distributed according to reward, but recent work suggests that they instead follow the regret under the user's optimal policy. Thus, learning a reward function from feedback is not only based on a flawed assumption of human preference, but also leads to unwieldy optimization challenges that stem from policy gradients or bootstrapping in the RL phase. Because of these optimization challenges, contemporary RLHF methods restrict themselves to contextual bandit settings (e.g., as in large language models) or limit observation dimensionality (e.g., state-based robotics). We overcome these limitations by introducing a new family of algorithms for optimizing behavior from human feedback using the regret-based model of human preferences. Using the principle of maximum entropy, we derive Contrastive Preference Learning (CPL), an algorithm for learning optimal policies from preferences without learning reward functions, circumventing the need for RL. CPL is fully off-policy, uses only a simple contrastive objective, and can be applied to arbitrary MDPs. This enables CPL to elegantly scale to high-dimensional and sequential RLHF problems while being simpler than prior methods.
5/1/2024

RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
0
0
State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
4/17/2024