RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
2404.08555
0
0

Abstract
State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a critical analysis of Reinforcement Learning from Human Feedback (RLHF), a technique used to align large language models (LLMs) with human preferences.
- The authors explore the motivations behind RLHF, the technical implementation details, and the potential limitations and challenges of this approach.
- The paper aims to help readers better understand the mechanics and implications of RLHF, an increasingly influential technique in the field of AI alignment.
Plain English Explanation
Reinforcement Learning from Human Feedback (RLHF) is a technique used to train large language models (LLMs) like ChatGPT to behave in ways that are more aligned with human preferences. The idea is to have humans provide feedback on the model's outputs, either by rating them or providing further instructions, and then use that feedback to fine-tune the model's behavior.
The key motivation behind RLHF is to address the "objective mismatch" problem, where an AI system's goals and behaviors may not fully align with what humans actually want. By incorporating human feedback directly into the training process, the hope is to create LLMs that are more reliable, trustworthy, and beneficial to society.
The technical implementation of RLHF involves training a separate "reward model" that learns to predict human preferences based on the feedback data. This reward model is then used to guide the training of the main language model, nudging it towards generating outputs that are more aligned with what humans want.
However, the paper also highlights some potential limitations and challenges of RLHF, such as the risk of feedback loops, the difficulty of scaling human feedback, and the inherent subjectivity and biases in human preferences. The authors encourage readers to think critically about the implications of this technology and to consider alternative approaches, such as Salmon or Rejection, for aligning AI systems with human values.
Technical Explanation
The paper begins by addressing the "objective mismatch" problem in pre-trained language models, where the model's objectives and behaviors may not fully align with human preferences. To address this, the authors discuss the use of Reinforcement Learning from Human Feedback (RLHF), a technique that incorporates human feedback directly into the training process.
The technical implementation of RLHF involves training a separate "reward model" that learns to predict human preferences based on feedback data. This reward model is then used to guide the training of the main language model, providing rewards for outputs that are more aligned with human preferences. The authors provide a detailed overview of the RLHF process, including the use of techniques like preference learning and reward modeling.
The paper also explores the potential limitations and challenges of RLHF, such as the risk of feedback loops, where the model's outputs may become increasingly skewed towards pleasing the human raters, and the difficulty of scaling human feedback to large, complex language models. The authors also discuss the inherent subjectivity and biases in human preferences, and the potential for RLHF to reinforce these biases in the trained models.
Critical Analysis
While the paper acknowledges the potential benefits of RLHF in aligning LLMs with human values, it also raises several important concerns and limitations that deserve further consideration.
One key limitation is the reliance on human feedback, which can be inherently subjective, biased, and difficult to scale. The authors note that "the subjectivity and biases in human preferences can be reflected and amplified in the trained models," potentially leading to unintended consequences.
Additionally, the paper highlights the risk of feedback loops, where the model's outputs become increasingly tailored to please human raters, rather than reflecting a genuine alignment with broader societal values. This could lead to models that are overly cautious, risk-averse, or even deceptive in their behavior.
The authors also raise concerns about the technical complexity of RLHF, which may make it challenging to implement and maintain, particularly as language models become larger and more sophisticated. They suggest that alternative approaches, such as Salmon or Rejection, may offer more scalable and robust solutions for AI alignment.
Overall, the paper provides a thoughtful and critical analysis of RLHF, highlighting both its potential benefits and its significant limitations. The authors encourage readers to consider the broader implications of this technology and to explore alternative approaches that may be better suited to addressing the challenge of aligning AI systems with human values.
Conclusion
The paper presents a detailed and critical analysis of Reinforcement Learning from Human Feedback (RLHF), a technique used to align large language models (LLMs) with human preferences. The authors explore the motivations behind RLHF, the technical implementation details, and the potential limitations and challenges of this approach.
While RLHF offers a promising approach to addressing the "objective mismatch" problem in pre-trained language models, the paper highlights several key concerns, such as the reliance on subjective human feedback, the risk of feedback loops, and the technical complexity of scaling the technique to large, sophisticated LLMs.
The authors encourage readers to think critically about the implications of RLHF and to consider alternative approaches, such as Salmon or Rejection, that may offer more scalable and robust solutions for aligning AI systems with human values.
Overall, this paper provides a valuable contribution to the ongoing discussion around AI alignment, highlighting the importance of carefully evaluating the strengths and limitations of emerging techniques like RLHF, and exploring alternative paths to ensuring that AI systems remain reliable, trustworthy, and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
A Survey of Reinforcement Learning from Human Feedback
Timo Kaufmann, Paul Weng, Viktor Bengs, Eyke Hullermeier
0
0
Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior work on the related setting of preference-based reinforcement learning (PbRL), it stands at the intersection of artificial intelligence and human-computer interaction. This positioning offers a promising avenue to enhance the performance and adaptability of intelligent systems while also improving the alignment of their objectives with human values. The training of large language models (LLMs) has impressively demonstrated this potential in recent years, where RLHF played a decisive role in directing the model's capabilities toward human objectives. This article provides a comprehensive overview of the fundamentals of RLHF, exploring the intricate dynamics between RL agents and human input. While recent focus has been on RLHF for LLMs, our survey adopts a broader perspective, examining the diverse applications and wide-ranging impact of the technique. We delve into the core principles that underpin RLHF, shedding light on the symbiotic relationship between algorithms and human feedback, and discuss the main research trends in the field. By synthesizing the current landscape of RLHF research, this article aims to provide researchers as well as practitioners with a comprehensive understanding of this rapidly growing field of research.
5/1/2024
🧠
RLHF Workflow: From Reward Modeling to Online RLHF
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
0
0
We present the workflow of Online Iterative Reinforcement Learning from Human Feedback (RLHF) in this technical report, which is widely reported to outperform its offline counterpart by a large margin in the recent large language model (LLM) literature. However, existing open-source RLHF projects are still largely confined to the offline learning setting. In this technical report, we aim to fill in this gap and provide a detailed recipe that is easy to reproduce for online iterative RLHF. In particular, since online human feedback is usually infeasible for open-source communities with limited resources, we start by constructing preference models using a diverse set of open-source datasets and use the constructed proxy preference model to approximate human feedback. Then, we discuss the theoretical insights and algorithmic principles behind online iterative RLHF, followed by a detailed practical implementation. Our trained LLM, SFR-Iterative-DPO-LLaMA-3-8B-R, achieves impressive performance on LLM chatbot benchmarks, including AlpacaEval-2, Arena-Hard, and MT-Bench, as well as other academic benchmarks such as HumanEval and TruthfulQA. We have shown that supervised fine-tuning (SFT) and iterative RLHF can obtain state-of-the-art performance with fully open-source datasets. Further, we have made our models, curated datasets, and comprehensive step-by-step code guidebooks publicly available. Please refer to https://github.com/RLHFlow/RLHF-Reward-Modeling and https://github.com/RLHFlow/Online-RLHF for more detailed information.
5/14/2024
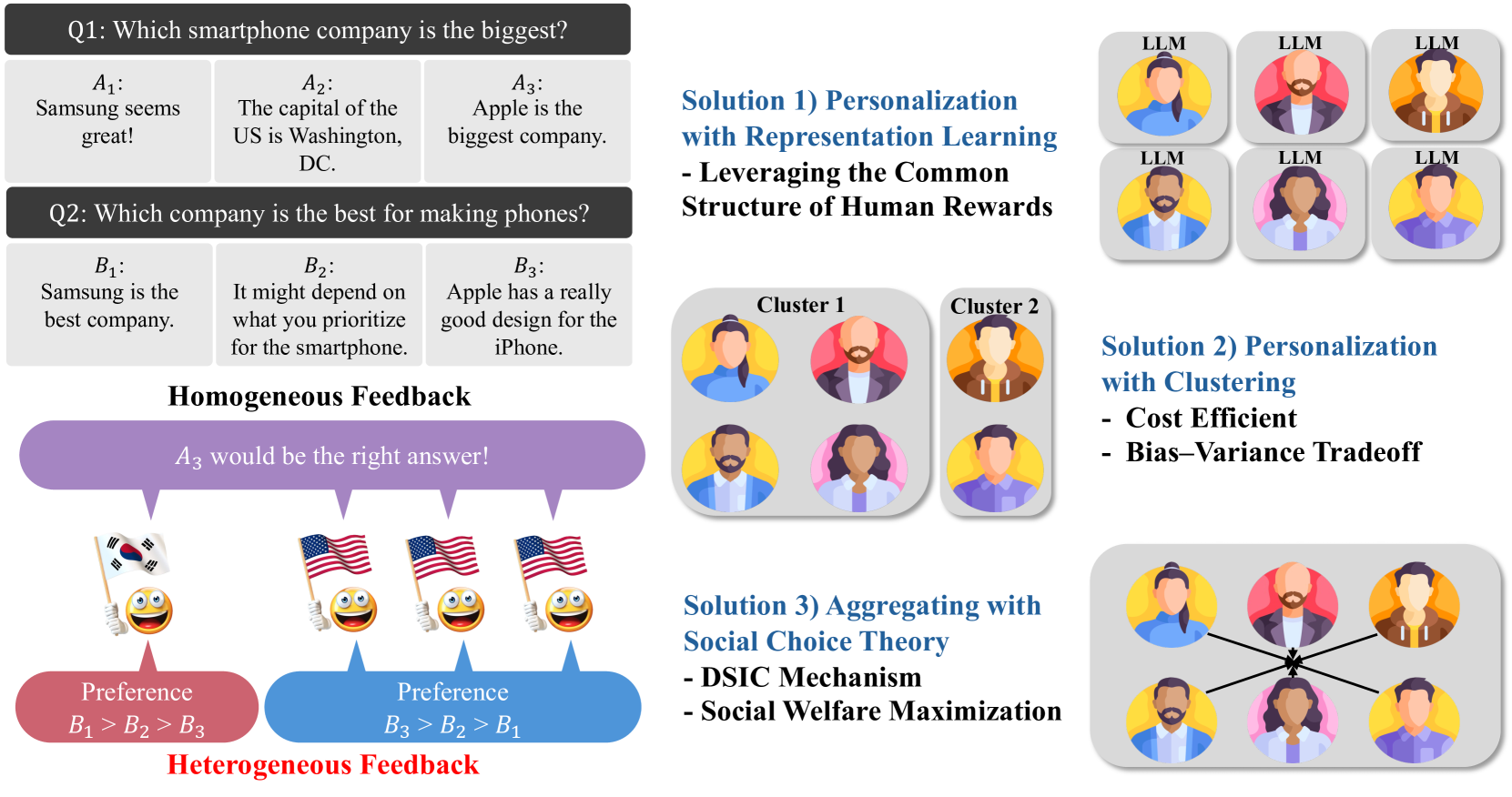
Principled RLHF from Heterogeneous Feedback via Personalization and Preference Aggregation
Chanwoo Park, Mingyang Liu, Kaiqing Zhang, Asuman Ozdaglar
0
0
Reinforcement learning from human feedback (RLHF) has been an effective technique for aligning AI systems with human values, with remarkable successes in fine-tuning large-language models recently. Most existing RLHF paradigms make the underlying assumption that human preferences are relatively homogeneous, and can be encoded by a single reward model. In this paper, we focus on addressing the issues due to the inherent heterogeneity in human preferences, as well as their potential strategic behavior in providing feedback. Specifically, we propose two frameworks to address heterogeneous human feedback in principled ways: personalization-based one and aggregation-based one. For the former, we propose two approaches based on representation learning and clustering, respectively, for learning multiple reward models that trades off the bias (due to preference heterogeneity) and variance (due to the use of fewer data for learning each model by personalization). We then establish sample complexity guarantees for both approaches. For the latter, we aim to adhere to the single-model framework, as already deployed in the current RLHF paradigm, by carefully aggregating diverse and truthful preferences from humans. We propose two approaches based on reward and preference aggregation, respectively: the former utilizes both utilitarianism and Leximin approaches to aggregate individual reward models, with sample complexity guarantees; the latter directly aggregates the human feedback in the form of probabilistic opinions. Under the probabilistic-opinion-feedback model, we also develop an approach to handle strategic human labelers who may bias and manipulate the aggregated preferences with untruthful feedback. Based on the ideas in mechanism design, our approach ensures truthful preference reporting, with the induced aggregation rule maximizing social welfare functions.
5/2/2024
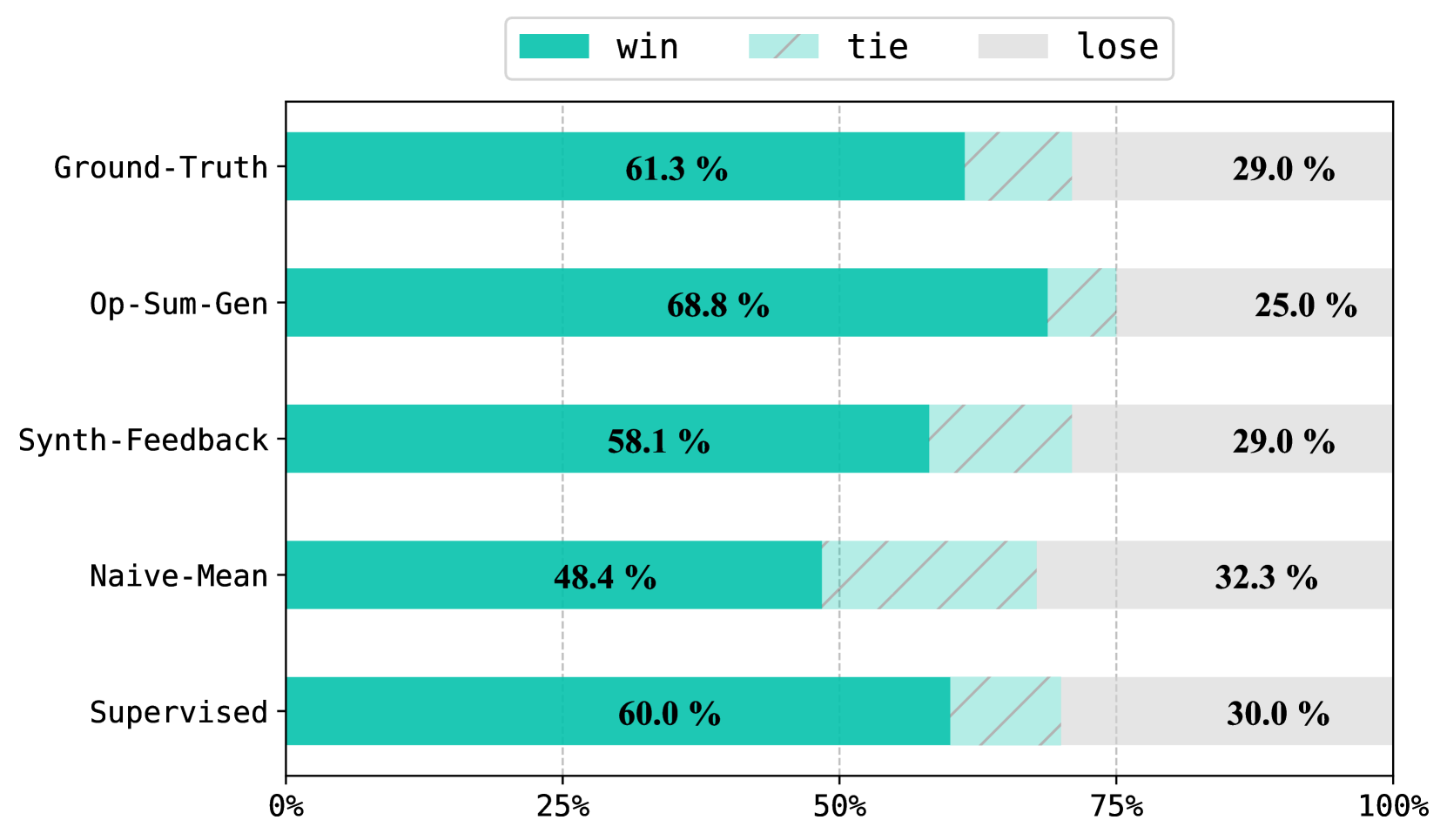
Leveraging Domain Knowledge for Efficient Reward Modelling in RLHF: A Case-Study in E-Commerce Opinion Summarization
Swaroop Nath, Tejpalsingh Siledar, Sankara Sri Raghava Ravindra Muddu, Rupasai Rangaraju, Harshad Khadilkar, Pushpak Bhattacharyya, Suman Banerjee, Amey Patil, Sudhanshu Shekhar Singh, Muthusamy Chelliah, Nikesh Garera
0
0
Reinforcement Learning from Human Feedback (RLHF) has become a dominating strategy in aligning Language Models (LMs) with human values/goals. The key to the strategy is learning a reward model ($varphi$), which can reflect the latent reward model of humans. While this strategy has proven effective, the training methodology requires a lot of human preference annotation (usually in the order of tens of thousands) to train $varphi$. Such a large-scale annotation is justifiable when it's a one-time effort, and the reward model is universally applicable. However, human goals are subjective and depend on the task, requiring task-specific preference annotations, which can be impractical to fulfill. To address this challenge, we propose a novel approach to infuse domain knowledge into $varphi$, which reduces the amount of preference annotation required ($21times$), omits Alignment Tax, and provides some interpretability. We validate our approach in E-Commerce Opinion Summarization, with a significant reduction in dataset size (to just $940$ samples) while advancing the SOTA ($sim4$ point ROUGE-L improvement, $68%$ of times preferred by humans over SOTA). Our contributions include a novel Reward Modeling technique and two new datasets: PromptOpinSumm (supervised data for Opinion Summarization) and OpinPref (a gold-standard human preference dataset). The proposed methodology opens up avenues for efficient RLHF, making it more adaptable to applications with varying human values. We release the artifacts (Code: github.com/efficient-rlhf. PromptOpinSumm: hf.co/prompt-opin-summ. OpinPref: hf.co/opin-pref) for usage under MIT License.
4/19/2024