Privacy-Aware Semantic Cache for Large Language Models
2403.02694
0
0
💬
Abstract
Large Language Models (LLMs) like ChatGPT and Llama2 have revolutionized natural language processing and search engine dynamics. However, these models incur exceptionally high computational costs. For instance, GPT-3 consists of 175 billion parameters where inference demands billions of floating-point operations. Caching is a natural solution to reduce LLM inference costs on repeated queries which constitute about 31% of the total queries. However, existing caching methods are incapable of finding semantic similarities among LLM queries, leading to unacceptable false hit-and-miss rates. This paper introduces MeanCache, a user-centric semantic cache for LLMs that identifies semantically similar queries to determine cache hit or miss. Using MeanCache, the response to a user's semantically similar query can be retrieved from a local cache rather than re-querying the LLM, thus reducing costs, service provider load, and environmental impact. Existing caching solutions for LLMs raise privacy and scalability concerns and perform wasteful query requests. MeanCache leverages Federated Learning (FL) to collaboratively train a query similarity model across LLM users without violating privacy. By placing a local cache in each user's device and using FL, MeanCache reduces the latency and costs and enhances model performance, resulting in lower false hit rates. MeanCache compresses the embedding dimensions to minimize cache storage and also finds the optimal cosine similarity threshold. Our experiments benchmarked against the state-of-the-art caching method, reveal that MeanCache attains an approximately 17% higher F-score and a 20% increase in precision during semantic cache hit-and-miss decisions. It also reduces the storage requirement by 83% and accelerates semantic cache hit-and-miss decisions by 11%.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a privacy-aware semantic cache for large language models (LLMs) like ChatGPT and LLaMA.
- The cache aims to improve the efficiency and reduce the privacy risks of using LLMs by storing and retrieving text responses based on their semantic similarity, rather than just exact matches.
- The authors develop a federated learning approach to train the cache without exposing the contents of users' conversations to the server.
Plain English Explanation
The paper tackles the challenge of using large language models (LLMs) like ChatGPT in a way that protects user privacy. LLMs are powerful AI systems that can generate human-like text, but they require sending a user's input to a remote server for processing. This raises privacy concerns, as the server could potentially access the contents of users' conversations.
The researchers propose a "semantic cache" that stores and retrieves text responses based on their meaning, rather than just exact matches. This allows the system to quickly provide relevant responses without needing to send the user's input to the server each time. To protect privacy, the cache is trained using a federated learning approach, where the model is updated collaboratively without exposing the actual text from users' conversations.
Imagine you're using a digital assistant to get information. Instead of sending your every question to a central server, the assistant has a local "memory" that can quickly retrieve relevant responses based on the meaning of what you're asking. And this memory is trained in a way that keeps the content of your conversations private. This is the core idea behind the privacy-aware semantic cache described in the paper.
Technical Explanation
The paper proposes a federated learning approach to train a semantic cache for LLMs. The cache stores text responses along with their semantic embeddings, which capture the meaning of the text. When a user query comes in, the cache first checks if a semantically similar response is available, and if so, returns it directly without needing to query the LLM.
To train the cache, the authors use a federated learning setup where multiple client devices collaboratively update a shared cache model without exchanging the actual text data. Each client device generates text responses using the LLM and computes their semantic embeddings. These embeddings are then used to update the cache model on the server, while the actual text content remains on the client devices.
The paper evaluates the performance of the semantic cache using datasets of conversational interactions. They measure the cache hit rate, which indicates how often a relevant response can be retrieved from the cache instead of querying the LLM. The results show that the semantic cache can achieve significantly higher hit rates compared to a baseline cache that only stores exact matches.
Critical Analysis
The paper presents a promising approach to improving the efficiency and privacy of using LLMs, but there are a few potential limitations and areas for further research:
-
The performance of the semantic cache is heavily dependent on the quality of the semantic embeddings used. The paper does not explore the impact of different embedding models or techniques on the cache's performance.
-
The federated learning approach assumes that client devices have sufficient computational resources to generate text responses and compute embeddings. This may not be the case for resource-constrained devices, limiting the scalability of the approach.
-
The paper focuses on the technical aspects of the semantic cache, but does not delve into the broader implications of such a system. There could be concerns around the potential for the cache to inadvertently introduce biases or amplify certain types of content.
-
The evaluation is limited to conversational datasets, and it's unclear how the semantic cache would perform in other domains or use cases for LLMs, such as content generation or task completion.
Overall, the privacy-aware semantic cache proposed in this paper represents an interesting step towards more efficient and privacy-preserving use of large language models. However, further research is needed to address the potential limitations and explore the broader societal implications of such a system.
Conclusion
This paper presents a novel approach to improving the efficiency and privacy of using large language models like ChatGPT and LLaMA. By introducing a semantic cache that stores and retrieves text responses based on their meaning rather than exact matches, the system can provide relevant information to users without needing to send their queries to a remote server each time. The use of federated learning techniques allows the cache to be trained collaboratively without exposing the contents of users' conversations.
While the paper demonstrates the potential of this approach, there are still some challenges and areas for further research to address, such as the impact of different embedding models and the broader implications of such a system. Nevertheless, the privacy-aware semantic cache represents an important step towards more efficient and privacy-preserving use of powerful language models, which could have significant implications for the future of AI-powered digital assistants and other applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Efficient LLM Inference with Kcache
Qiaozhi He, Zhihua Wu
0
0
Large Language Models(LLMs) have had a profound impact on AI applications, particularly in the domains of long-text comprehension and generation. KV Cache technology is one of the most widely used techniques in the industry. It ensures efficient sequence generation by caching previously computed KV states. However, it also introduces significant memory overhead. We discovered that KV Cache is not necessary and proposed a novel KCache technique to alleviate the memory bottleneck issue during the LLMs inference process. KCache can be used directly for inference without any training process, Our evaluations show that KCache improves the throughput of popular LLMs by 40% with the baseline, while keeping accuracy.
4/30/2024
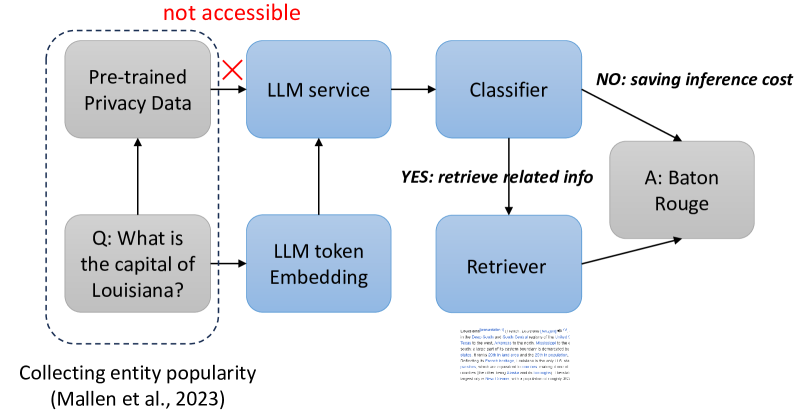
Learn When (not) to Trust Language Models: A Privacy-Centric Adaptive Model-Aware Approach
Chengkai Huang, Rui Wang, Kaige Xie, Tong Yu, Lina Yao
0
0
Retrieval-augmented large language models (LLMs) have been remarkably competent in various NLP tasks. Despite their great success, the knowledge provided by the retrieval process is not always useful for improving the model prediction, since in some samples LLMs may already be quite knowledgeable and thus be able to answer the question correctly without retrieval. Aiming to save the cost of retrieval, previous work has proposed to determine when to do/skip the retrieval in a data-aware manner by analyzing the LLMs' pretraining data. However, these data-aware methods pose privacy risks and memory limitations, especially when requiring access to sensitive or extensive pretraining data. Moreover, these methods offer limited adaptability under fine-tuning or continual learning settings. We hypothesize that token embeddings are able to capture the model's intrinsic knowledge, which offers a safer and more straightforward way to judge the need for retrieval without the privacy risks associated with accessing pre-training data. Moreover, it alleviates the need to retain all the data utilized during model pre-training, necessitating only the upkeep of the token embeddings. Extensive experiments and in-depth analyses demonstrate the superiority of our model-aware approach.
4/5/2024

Can large language models understand uncommon meanings of common words?
Jinyang Wu, Feihu Che, Xinxin Zheng, Shuai Zhang, Ruihan Jin, Shuai Nie, Pengpeng Shao, Jianhua Tao
0
0
Large language models (LLMs) like ChatGPT have shown significant advancements across diverse natural language understanding (NLU) tasks, including intelligent dialogue and autonomous agents. Yet, lacking widely acknowledged testing mechanisms, answering `whether LLMs are stochastic parrots or genuinely comprehend the world' remains unclear, fostering numerous studies and sparking heated debates. Prevailing research mainly focuses on surface-level NLU, neglecting fine-grained explorations. However, such explorations are crucial for understanding their unique comprehension mechanisms, aligning with human cognition, and finally enhancing LLMs' general NLU capacities. To address this gap, our study delves into LLMs' nuanced semantic comprehension capabilities, particularly regarding common words with uncommon meanings. The idea stems from foundational principles of human communication within psychology, which underscore accurate shared understandings of word semantics. Specifically, this paper presents the innovative construction of a Lexical Semantic Comprehension (LeSC) dataset with novel evaluation metrics, the first benchmark encompassing both fine-grained and cross-lingual dimensions. Introducing models of both open-source and closed-source, varied scales and architectures, our extensive empirical experiments demonstrate the inferior performance of existing models in this basic lexical-meaning understanding task. Notably, even the state-of-the-art LLMs GPT-4 and GPT-3.5 lag behind 16-year-old humans by 3.9% and 22.3%, respectively. Additionally, multiple advanced prompting techniques and retrieval-augmented generation are also introduced to help alleviate this trouble, yet limitations persist. By highlighting the above critical shortcomings, this research motivates further investigation and offers novel insights for developing more intelligent LLMs.
5/10/2024
💬
Improving the Capabilities of Large Language Model Based Marketing Analytics Copilots With Semantic Search And Fine-Tuning
Yilin Gao, Sai Kumar Arava, Yancheng Li, James W. Snyder Jr
0
0
Artificial intelligence (AI) is widely deployed to solve problems related to marketing attribution and budget optimization. However, AI models can be quite complex, and it can be difficult to understand model workings and insights without extensive implementation teams. In principle, recently developed large language models (LLMs), like GPT-4, can be deployed to provide marketing insights, reducing the time and effort required to make critical decisions. In practice, there are substantial challenges that need to be overcome to reliably use such models. We focus on domain-specific question-answering, SQL generation needed for data retrieval, and tabular analysis and show how a combination of semantic search, prompt engineering, and fine-tuning can be applied to dramatically improve the ability of LLMs to execute these tasks accurately. We compare both proprietary models, like GPT-4, and open-source models, like Llama-2-70b, as well as various embedding methods. These models are tested on sample use cases specific to marketing mix modeling and attribution.
4/23/2024