Learn When (not) to Trust Language Models: A Privacy-Centric Adaptive Model-Aware Approach
2404.03514
0
0
Abstract
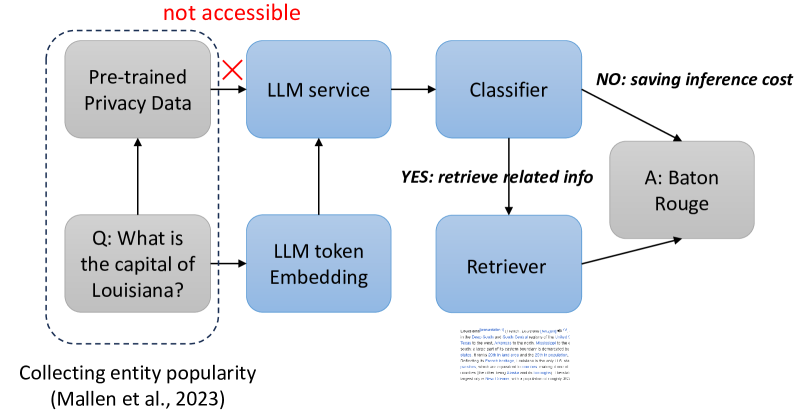
Retrieval-augmented large language models (LLMs) have been remarkably competent in various NLP tasks. Despite their great success, the knowledge provided by the retrieval process is not always useful for improving the model prediction, since in some samples LLMs may already be quite knowledgeable and thus be able to answer the question correctly without retrieval. Aiming to save the cost of retrieval, previous work has proposed to determine when to do/skip the retrieval in a data-aware manner by analyzing the LLMs' pretraining data. However, these data-aware methods pose privacy risks and memory limitations, especially when requiring access to sensitive or extensive pretraining data. Moreover, these methods offer limited adaptability under fine-tuning or continual learning settings. We hypothesize that token embeddings are able to capture the model's intrinsic knowledge, which offers a safer and more straightforward way to judge the need for retrieval without the privacy risks associated with accessing pre-training data. Moreover, it alleviates the need to retain all the data utilized during model pre-training, necessitating only the upkeep of the token embeddings. Extensive experiments and in-depth analyses demonstrate the superiority of our model-aware approach.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper presents a "Model-Aware Adaptive Retrieval Augmentation" (MAARA) approach that helps language models determine when to trust their own outputs versus retrieving information from external sources.
- The key idea is to adaptively balance the use of the language model's own generation capabilities with the retrieval of relevant information from external sources, based on the model's own assessment of its trustworthiness.
- This allows the language model to be more reliable and robust, particularly in sensitive or privacy-critical domains where fully trusting the model's outputs may not be appropriate.
Plain English Explanation
The paper discusses a new approach called "Model-Aware Adaptive Retrieval Augmentation" (MAARA) that helps language models, like chatbots or healthcare AI assistants, figure out when they should trust their own responses versus looking up information from external sources.
The key idea is that language models don't always know when they can be fully trusted. In sensitive domains like healthcare or privacy-critical applications, it's important for the model to have a way to assess its own trustworthiness and supplement its responses with information from reliable external sources when needed.
The MAARA approach allows the language model to adaptively balance its own generation capabilities with retrieving relevant information from external databases or knowledge bases. This makes the model more reliable and robust, since it can double-check its outputs and provide users with a mix of the model's own analysis and verified information from other sources.
Technical Explanation
The paper introduces the "Model-Aware Adaptive Retrieval Augmentation" (MAARA) approach, which allows language models to dynamically determine when to trust their own outputs versus retrieving information from external sources.
The core of MAARA is a module that assesses the model's own trustworthiness in generating a response. This "trustworthiness score" is then used to adaptively balance the model's generated output with relevant information retrieved from external knowledge sources. When the model is less confident in its own generation, it will retrieve more external information to supplement its response.
The authors propose several methods for computing this trustworthiness score, including using the model's own perplexity, a learned regression model, or a combination of these approaches. They evaluate MAARA on a range of language understanding and generation tasks, showing that it can improve performance and robustness compared to baselines that rely solely on the model's generated outputs or external retrieval.
Critical Analysis
The MAARA approach presented in the paper addresses an important challenge in using large language models - determining when their outputs can be fully trusted, particularly in sensitive domains. By giving the model the ability to assess its own trustworthiness and adaptively supplement its responses, MAARA can help make these models more reliable and robust.
However, the paper does not deeply explore the potential pitfalls or limitations of this approach. For example, the trustworthiness scoring mechanisms rely on the model's own internal signals, which could potentially be biased or unreliable. There are also open questions about how to ensure the external information sources used are accurate and up-to-date, especially for rapidly evolving topics.
Additionally, the evaluation is fairly narrow, focusing on standard language understanding and generation benchmarks. More research would be needed to understand how well MAARA performs in real-world, mission-critical applications where the stakes of trusting the model's outputs are high.
Overall, the MAARA concept is promising, but further work is needed to fully understand its limitations and ensure it can be deployed safely in sensitive domains like healthcare planning and editing.
Conclusion
The paper presents a novel "Model-Aware Adaptive Retrieval Augmentation" (MAARA) approach that allows language models to dynamically determine when to trust their own outputs versus retrieving information from external sources. This can improve the reliability and robustness of these models, particularly in sensitive domains where fully trusting the model's generation may not be appropriate.
The key innovation is giving the language model the ability to assess its own trustworthiness and adaptively balance its own generation with external retrieval. This helps address the challenge of when to trust language model outputs, which is crucial for deploying these models in real-world, high-stakes applications.
While the MAARA concept is promising, further research is needed to fully understand its limitations and ensure it can be safely deployed. Ongoing work in this area aims to make language models more reliable, transparent, and accountable, which will be essential as they become more widely used in consequential domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Understanding Privacy Risks of Embeddings Induced by Large Language Models
Zhihao Zhu, Ninglu Shao, Defu Lian, Chenwang Wu, Zheng Liu, Yi Yang, Enhong Chen
0
0
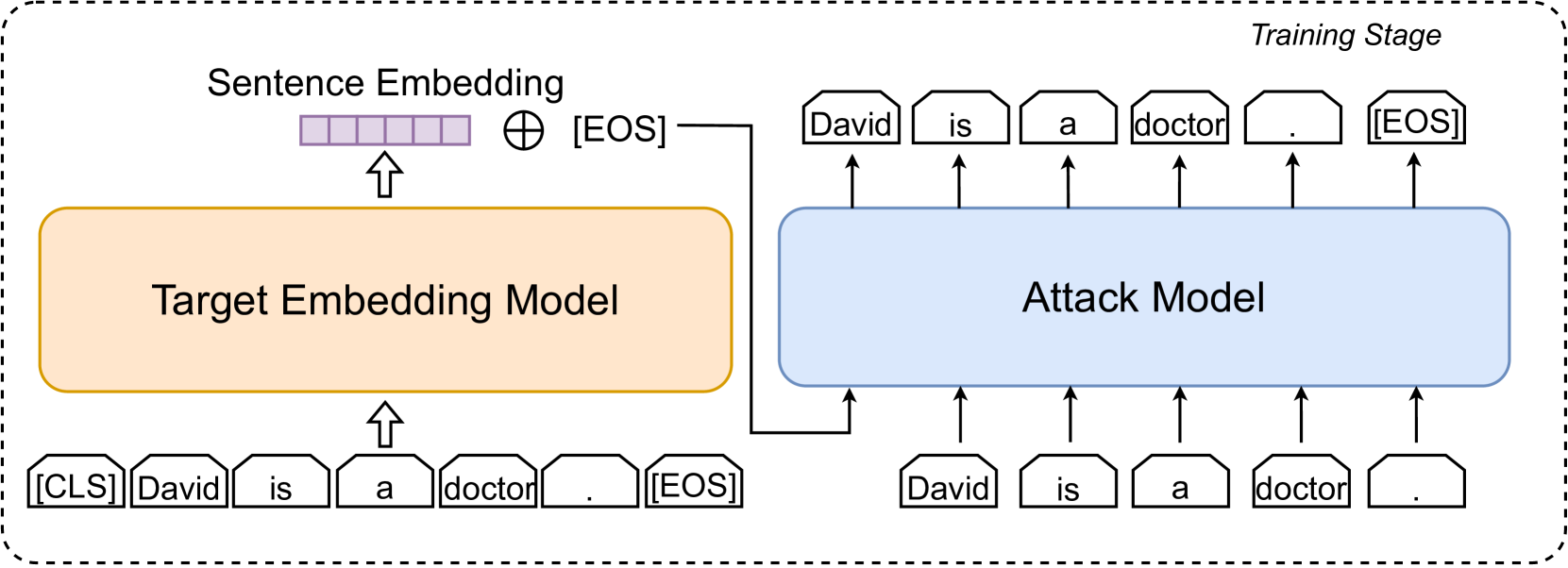
Large language models (LLMs) show early signs of artificial general intelligence but struggle with hallucinations. One promising solution to mitigate these hallucinations is to store external knowledge as embeddings, aiding LLMs in retrieval-augmented generation. However, such a solution risks compromising privacy, as recent studies experimentally showed that the original text can be partially reconstructed from text embeddings by pre-trained language models. The significant advantage of LLMs over traditional pre-trained models may exacerbate these concerns. To this end, we investigate the effectiveness of reconstructing original knowledge and predicting entity attributes from these embeddings when LLMs are employed. Empirical findings indicate that LLMs significantly improve the accuracy of two evaluated tasks over those from pre-trained models, regardless of whether the texts are in-distribution or out-of-distribution. This underscores a heightened potential for LLMs to jeopardize user privacy, highlighting the negative consequences of their widespread use. We further discuss preliminary strategies to mitigate this risk.
4/26/2024
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
0
0
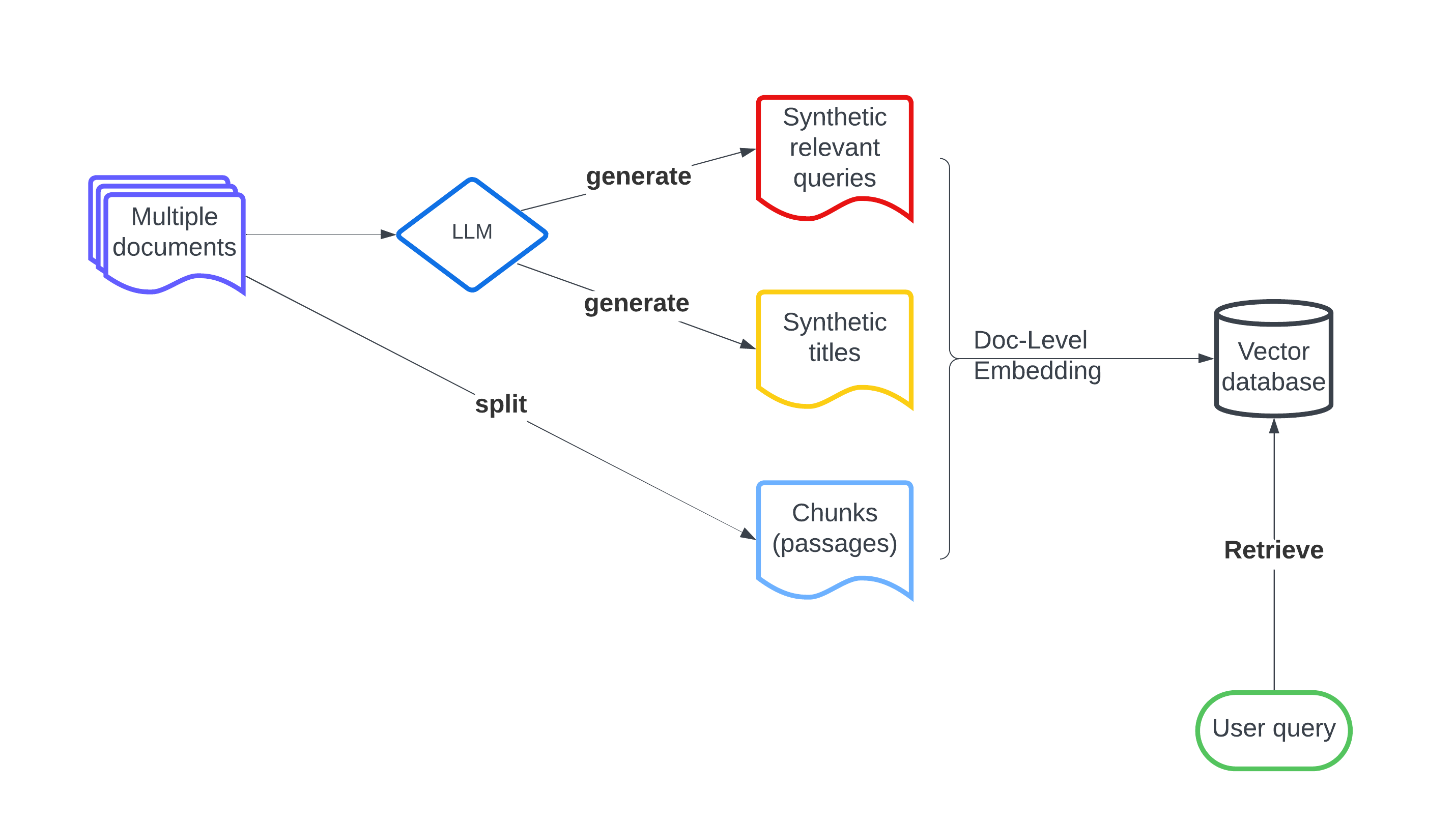
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
4/10/2024
🤯
Beyond Memorization: Violating Privacy Via Inference with Large Language Models
Robin Staab, Mark Vero, Mislav Balunovi'c, Martin Vechev
0
0
Current privacy research on large language models (LLMs) primarily focuses on the issue of extracting memorized training data. At the same time, models' inference capabilities have increased drastically. This raises the key question of whether current LLMs could violate individuals' privacy by inferring personal attributes from text given at inference time. In this work, we present the first comprehensive study on the capabilities of pretrained LLMs to infer personal attributes from text. We construct a dataset consisting of real Reddit profiles, and show that current LLMs can infer a wide range of personal attributes (e.g., location, income, sex), achieving up to $85%$ top-1 and $95%$ top-3 accuracy at a fraction of the cost ($100times$) and time ($240times$) required by humans. As people increasingly interact with LLM-powered chatbots across all aspects of life, we also explore the emerging threat of privacy-invasive chatbots trying to extract personal information through seemingly benign questions. Finally, we show that common mitigations, i.e., text anonymization and model alignment, are currently ineffective at protecting user privacy against LLM inference. Our findings highlight that current LLMs can infer personal data at a previously unattainable scale. In the absence of working defenses, we advocate for a broader discussion around LLM privacy implications beyond memorization, striving for a wider privacy protection.
5/7/2024
🛸
When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
Tiziano Labruna, Jon Ander Campos, Gorka Azkune
0
0
In this paper, we demonstrate how Large Language Models (LLMs) can effectively learn to use an off-the-shelf information retrieval (IR) system specifically when additional context is required to answer a given question. Given the performance of IR systems, the optimal strategy for question answering does not always entail external information retrieval; rather, it often involves leveraging the parametric memory of the LLM itself. Prior research has identified this phenomenon in the PopQA dataset, wherein the most popular questions are effectively addressed using the LLM's parametric memory, while less popular ones require IR system usage. Following this, we propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets. Here, LLMs are trained to generate a special token, , when they do not know the answer to a question. Our evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset showcases improvements over the same LLM under three configurations: (i) retrieving information for all the questions, (ii) using always the parametric memory of the LLM, and (iii) using a popularity threshold to decide when to use a retriever. Through our analysis, we demonstrate that Adapt-LLM is able to generate the token when it determines that it does not know how to answer a question, indicating the need for IR, while it achieves notably high accuracy levels when it chooses to rely only on its parametric memory.
5/8/2024