A Probabilistic Approach to Learning the Degree of Equivariance in Steerable CNNs
2406.03946
0
0

Abstract
Steerable convolutional neural networks (SCNNs) enhance task performance by modelling geometric symmetries through equivariance constraints on weights. Yet, unknown or varying symmetries can lead to overconstrained weights and decreased performance. To address this, this paper introduces a probabilistic method to learn the degree of equivariance in SCNNs. We parameterise the degree of equivariance as a likelihood distribution over the transformation group using Fourier coefficients, offering the option to model layer-wise and shared equivariance. These likelihood distributions are regularised to ensure an interpretable degree of equivariance across the network. Advantages include the applicability to many types of equivariant networks through the flexible framework of SCNNs and the ability to learn equivariance with respect to any subgroup of any compact group without requiring additional layers. Our experiments reveal competitive performance on datasets with mixed symmetries, with learnt likelihood distributions that are representative of the underlying degree of equivariance.
Create account to get full access
Overview
- This paper proposes a novel approach for learning the degree of equivariance in steerable convolutional neural networks (CNNs).
- The key idea is to use a probabilistic model to estimate the degree of equivariance, which allows the network to learn the appropriate level of equivariance for a given task.
- The authors demonstrate the effectiveness of their approach on various computer vision tasks, showing improved performance compared to standard steerable CNNs.
Plain English Explanation
Steerable convolutional neural networks (CNNs) are a type of deep learning model that can be equivariant to certain transformations, such as rotation or scaling. This means that the network's output will transform in a predictable way when the input image is transformed.
However, in many real-world scenarios, the degree of equivariance required may not be known in advance. This paper presents a probabilistic approach to learning the appropriate level of equivariance for a given task.
The key idea is to introduce a set of learnable parameters that control the degree of equivariance in the network. These parameters are trained alongside the other network weights, allowing the model to automatically discover the optimal level of equivariance for the task at hand.
This approach has several advantages. First, it avoids the need to manually tune the degree of equivariance, which can be a tedious and error-prone process. Second, it allows the network to adapt its equivariance properties to the specific requirements of the task, potentially leading to better performance.
The authors demonstrate the effectiveness of their approach on a variety of computer vision tasks, such as image classification and object detection. Their results show that the proposed method outperforms standard steerable CNNs, highlighting the benefits of learning the degree of equivariance in a more principled way.
Technical Explanation
The authors propose a novel approach for learning the degree of equivariance in steerable convolutional neural networks (CNNs). Steerable CNNs are a class of deep learning models that can be equivariant to certain transformations, such as rotation or scaling.
Traditionally, the degree of equivariance in steerable CNNs is set manually based on prior knowledge or heuristics. However, this can be a challenging and error-prone process, as the optimal degree of equivariance may vary depending on the task and dataset.
To address this issue, the authors introduce a probabilistic model that learns the degree of equivariance as part of the training process. Specifically, they parameterize the equivariance properties of the network using a set of learnable variables, which are optimized alongside the other network weights.
This learning-based approach allows the network to automatically discover the appropriate level of equivariance for a given task, without the need for manual tuning.
The authors evaluate their proposed method on a variety of computer vision tasks, including image classification and object detection. Their results demonstrate that the learned degree of equivariance can outperform standard steerable CNNs, highlighting the benefits of this more flexible and principled approach to equivariance.
Critical Analysis
The authors present a compelling approach for learning the degree of equivariance in steerable CNNs. By introducing learnable parameters that control the equivariance properties of the network, they allow the model to automatically adapt to the specific requirements of the task at hand.
One potential limitation of the proposed method is the computational overhead associated with the additional learnable parameters. Depending on the complexity of the task and the size of the network, this could lead to increased training and inference times. The authors acknowledge this issue and suggest that future work could explore ways to reduce the computational cost, such as through the use of efficient parameterizations.
Another area for further research could be the interpretability of the learned equivariance parameters. While the authors demonstrate the effectiveness of their approach, it would be interesting to gain a deeper understanding of how the network is using these parameters to optimize its equivariance properties. This could lead to additional insights about the relationship between equivariance and task performance.
Overall, the authors have presented a novel and promising approach for learning the degree of equivariance in steerable CNNs. Their work highlights the importance of equivariance in deep learning and the potential benefits of a more flexible and adaptive approach to this property.
Conclusion
This paper introduces a probabilistic approach for learning the degree of equivariance in steerable convolutional neural networks (CNNs). By parameterizing the equivariance properties of the network and optimizing these parameters during training, the authors enable the model to automatically discover the appropriate level of equivariance for a given task.
The authors demonstrate the effectiveness of their approach on various computer vision tasks, showing improved performance compared to standard steerable CNNs. This work highlights the importance of equivariance in deep learning and the potential benefits of a more flexible and adaptive approach to this property.
The proposed method offers a promising direction for future research, as it could lead to more robust and efficient deep learning models that can better adapt to the specific requirements of a given task or dataset.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Leveraging SO(3)-steerable convolutions for pose-robust semantic segmentation in 3D medical data
Ivan Diaz, Mario Geiger, Richard Iain McKinley
0
0
Convolutional neural networks (CNNs) allow for parameter sharing and translational equivariance by using convolutional kernels in their linear layers. By restricting these kernels to be SO(3)-steerable, CNNs can further improve parameter sharing. These rotationally-equivariant convolutional layers have several advantages over standard convolutional layers, including increased robustness to unseen poses, smaller network size, and improved sample efficiency. Despite this, most segmentation networks used in medical image analysis continue to rely on standard convolutional kernels. In this paper, we present a new family of segmentation networks that use equivariant voxel convolutions based on spherical harmonics. These networks are robust to data poses not seen during training, and do not require rotation-based data augmentation during training. In addition, we demonstrate improved segmentation performance in MRI brain tumor and healthy brain structure segmentation tasks, with enhanced robustness to reduced amounts of training data and improved parameter efficiency. Code to reproduce our results, and to implement the equivariant segmentation networks for other tasks is available at http://github.com/SCAN-NRAD/e3nn_Unet
5/20/2024
🧠
Theory for Equivariant Quantum Neural Networks
Quynh T. Nguyen, Louis Schatzki, Paolo Braccia, Michael Ragone, Patrick J. Coles, Frederic Sauvage, Martin Larocca, M. Cerezo
0
0
Quantum neural network architectures that have little-to-no inductive biases are known to face trainability and generalization issues. Inspired by a similar problem, recent breakthroughs in machine learning address this challenge by creating models encoding the symmetries of the learning task. This is materialized through the usage of equivariant neural networks whose action commutes with that of the symmetry. In this work, we import these ideas to the quantum realm by presenting a comprehensive theoretical framework to design equivariant quantum neural networks (EQNN) for essentially any relevant symmetry group. We develop multiple methods to construct equivariant layers for EQNNs and analyze their advantages and drawbacks. Our methods can find unitary or general equivariant quantum channels efficiently even when the symmetry group is exponentially large or continuous. As a special implementation, we show how standard quantum convolutional neural networks (QCNN) can be generalized to group-equivariant QCNNs where both the convolution and pooling layers are equivariant to the symmetry group. We then numerically demonstrate the effectiveness of a SU(2)-equivariant QCNN over symmetry-agnostic QCNN on a classification task of phases of matter in the bond-alternating Heisenberg model. Our framework can be readily applied to virtually all areas of quantum machine learning. Lastly, we discuss about how symmetry-informed models such as EQNNs provide hopes to alleviate central challenges such as barren plateaus, poor local minima, and sample complexity.
5/14/2024
✨
The Lie Derivative for Measuring Learned Equivariance
Nate Gruver, Marc Finzi, Micah Goldblum, Andrew Gordon Wilson
0
0
Equivariance guarantees that a model's predictions capture key symmetries in data. When an image is translated or rotated, an equivariant model's representation of that image will translate or rotate accordingly. The success of convolutional neural networks has historically been tied to translation equivariance directly encoded in their architecture. The rising success of vision transformers, which have no explicit architectural bias towards equivariance, challenges this narrative and suggests that augmentations and training data might also play a significant role in their performance. In order to better understand the role of equivariance in recent vision models, we introduce the Lie derivative, a method for measuring equivariance with strong mathematical foundations and minimal hyperparameters. Using the Lie derivative, we study the equivariance properties of hundreds of pretrained models, spanning CNNs, transformers, and Mixer architectures. The scale of our analysis allows us to separate the impact of architecture from other factors like model size or training method. Surprisingly, we find that many violations of equivariance can be linked to spatial aliasing in ubiquitous network layers, such as pointwise non-linearities, and that as models get larger and more accurate they tend to display more equivariance, regardless of architecture. For example, transformers can be more equivariant than convolutional neural networks after training.
6/19/2024
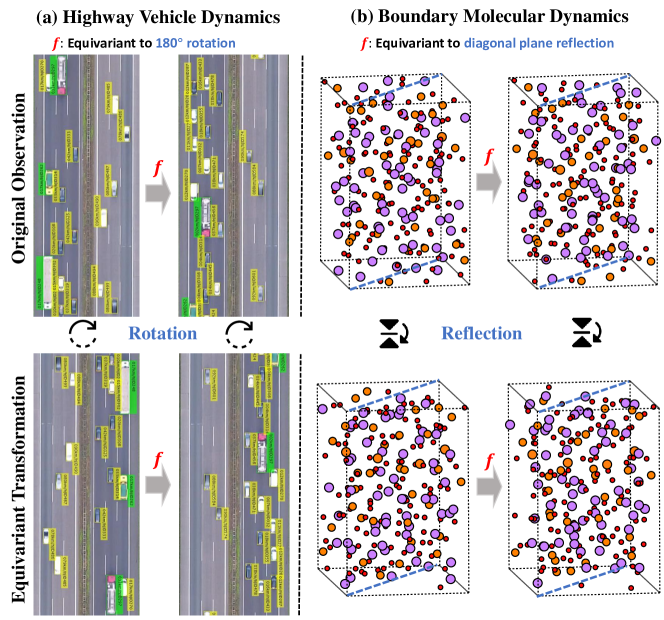
New!Relaxing Continuous Constraints of Equivariant Graph Neural Networks for Physical Dynamics Learning
Zinan Zheng, Yang Liu, Jia Li, Jianhua Yao, Yu Rong
0
0
Incorporating Euclidean symmetries (e.g. rotation equivariance) as inductive biases into graph neural networks has improved their generalization ability and data efficiency in unbounded physical dynamics modeling. However, in various scientific and engineering applications, the symmetries of dynamics are frequently discrete due to the boundary conditions. Thus, existing GNNs either overlook necessary symmetry, resulting in suboptimal representation ability, or impose excessive equivariance, which fails to generalize to unobserved symmetric dynamics. In this work, we propose a general Discrete Equivariant Graph Neural Network (DEGNN) that guarantees equivariance to a given discrete point group. Specifically, we show that such discrete equivariant message passing could be constructed by transforming geometric features into permutation-invariant embeddings. Through relaxing continuous equivariant constraints, DEGNN can employ more geometric feature combinations to approximate unobserved physical object interaction functions. Two implementation approaches of DEGNN are proposed based on ranking or pooling permutation-invariant functions. We apply DEGNN to various physical dynamics, ranging from particle, molecular, crowd to vehicle dynamics. In twenty scenarios, DEGNN significantly outperforms existing state-of-the-art approaches. Moreover, we show that DEGNN is data efficient, learning with less data, and can generalize across scenarios such as unobserved orientation.
6/26/2024