ProG: A Graph Prompt Learning Benchmark

0

Sign in to get full access
Overview
- This paper introduces ProG, a new benchmark for evaluating graph prompt learning models.
- Graph prompt learning is a technique where a model is trained to generate prompts that can be used to fine-tune a larger model for graph-based tasks.
- ProG includes a variety of graph-based tasks and datasets to assess the performance of different prompt learning approaches.
Plain English Explanation
The paper describes a new benchmark called ProG that is designed to evaluate how well machine learning models can learn "prompts" for graph-based tasks. Prompt learning is a technique where a model is trained to generate short inputs that can then be used to fine-tune a larger model for a specific task.
The key idea behind ProG is to provide a standardized set of graph-based tasks and datasets that researchers can use to compare the effectiveness of different prompt learning approaches. Graphs are a way of representing complex, interconnected data, and they have applications in areas like social network analysis, recommendation systems, and drug discovery. By having a common benchmark, researchers can more easily assess the strengths and weaknesses of new prompt learning methods for working with graph-structured data.
The paper covers the technical details of how ProG is designed, including the types of tasks and datasets it includes. But the main contribution is simply providing this new standardized benchmark to help advance research in this emerging area of prompt learning for graphs. Other recent work has also explored prompt learning techniques for graph data, and ProG should help accelerate progress in this exciting field.
Technical Explanation
The key technical components of the ProG benchmark are:
-
Task Suite: ProG includes a variety of graph-based tasks such as node classification, link prediction, and graph classification. These tasks cover a range of real-world applications of graph ML.
-
Dataset Collection: The benchmark includes both synthetic and real-world graph datasets of varying sizes and complexities. This diversity allows evaluating prompt learning methods across different data characteristics.
-
Evaluation Protocols: ProG defines standardized evaluation metrics and procedures for each task to ensure fair comparisons between different prompt learning approaches. This includes train/val/test splits and performance reporting.
-
Baselines: The authors provide baseline results using several prominent prompt learning methods, such as Universal Prompt Tuning and Pre-training with Structure Prompts. These baselines serve as reference points for new methods.
The technical details of the benchmark design and baseline results are thoroughly documented in the paper. Overall, ProG aims to accelerate research progress in graph prompt learning by providing a standardized, comprehensive evaluation framework.
Critical Analysis
The authors have done a commendable job in developing a thorough and well-designed benchmark for graph prompt learning. A few potential limitations and areas for further research include:
-
Task and Dataset Coverage: While ProG includes a diverse set of tasks and datasets, there may be other important graph-based applications and real-world datasets that are not represented. Expanding the benchmark over time could make it even more comprehensive.
-
Scalability: The largest datasets in ProG may still be relatively small compared to real-world graph problems. Evaluating prompt learning methods on truly massive graphs would be valuable.
-
Dynamic Graphs: The current benchmark focuses on static graphs, but many real-world graphs evolve over time. Techniques for prompt learning on dynamic graphs could be an important extension.
-
Interpretability: The paper does not explore how well the learned prompts can be interpreted by humans. Developing prompt learning methods that are more transparent could be an interesting direction.
Despite these potential avenues for future work, ProG represents a significant contribution to the field of graph machine learning. By providing a standardized benchmark, the authors have laid the groundwork for more rigorous and comparable evaluations of prompt learning techniques for graphs.
Conclusion
In summary, the ProG benchmark introduced in this paper offers a comprehensive evaluation framework for assessing graph prompt learning models. By including a diverse set of graph-based tasks and datasets, ProG enables researchers to thoroughly compare the performance of different prompt learning approaches. This should accelerate progress in an important and growing area of graph machine learning research. While there are always opportunities for further refinement and expansion, ProG is a valuable resource that will likely become a standard reference for the community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ProG: A Graph Prompt Learning Benchmark
Chenyi Zi, Haihong Zhao, Xiangguo Sun, Yiqing Lin, Hong Cheng, Jia Li
Artificial general intelligence on graphs has shown significant advancements across various applications, yet the traditional 'Pre-train & Fine-tune' paradigm faces inefficiencies and negative transfer issues, particularly in complex and few-shot settings. Graph prompt learning emerges as a promising alternative, leveraging lightweight prompts to manipulate data and fill the task gap by reformulating downstream tasks to the pretext. However, several critical challenges still remain: how to unify diverse graph prompt models, how to evaluate the quality of graph prompts, and to improve their usability for practical comparisons and selection. In response to these challenges, we introduce the first comprehensive benchmark for graph prompt learning. Our benchmark integrates SIX pre-training methods and FIVE state-of-the-art graph prompt techniques, evaluated across FIFTEEN diverse datasets to assess performance, flexibility, and efficiency. We also present 'ProG', an easy-to-use open-source library that streamlines the execution of various graph prompt models, facilitating objective evaluations. Additionally, we propose a unified framework that categorizes existing graph prompt methods into two main approaches: prompts as graphs and prompts as tokens. This framework enhances the applicability and comparison of graph prompt techniques. The code is available at: https://github.com/sheldonresearch/ProG.
Read more6/21/2024

0
Towards Graph Prompt Learning: A Survey and Beyond
Qingqing Long, Yuchen Yan, Peiyan Zhang, Chen Fang, Wentao Cui, Zhiyuan Ning, Meng Xiao, Ning Cao, Xiao Luo, Lingjun Xu, Shiyue Jiang, Zheng Fang, Chong Chen, Xian-Sheng Hua, Yuanchun Zhou
Large-scale pre-train and prompt learning paradigms have demonstrated remarkable adaptability, enabling broad applications across diverse domains such as question answering, image recognition, and multimodal retrieval. This approach fully leverages the potential of large-scale pre-trained models, reducing downstream data requirements and computational costs while enhancing model applicability across various tasks. Graphs, as versatile data structures that capture relationships between entities, play pivotal roles in fields such as social network analysis, recommender systems, and biological graphs. Despite the success of pre-train and prompt learning paradigms in Natural Language Processing (NLP) and Computer Vision (CV), their application in graph domains remains nascent. In graph-structured data, not only do the node and edge features often have disparate distributions, but the topological structures also differ significantly. This diversity in graph data can lead to incompatible patterns or gaps between pre-training and fine-tuning on downstream graphs. We aim to bridge this gap by summarizing methods for alleviating these disparities. This includes exploring prompt design methodologies, comparing related techniques, assessing application scenarios and datasets, and identifying unresolved problems and challenges. This survey categorizes over 100 relevant works in this field, summarizing general design principles and the latest applications, including text-attributed graphs, molecules, proteins, and recommendation systems. Through this extensive review, we provide a foundational understanding of graph prompt learning, aiming to impact not only the graph mining community but also the broader Artificial General Intelligence (AGI) community.
Read more9/2/2024
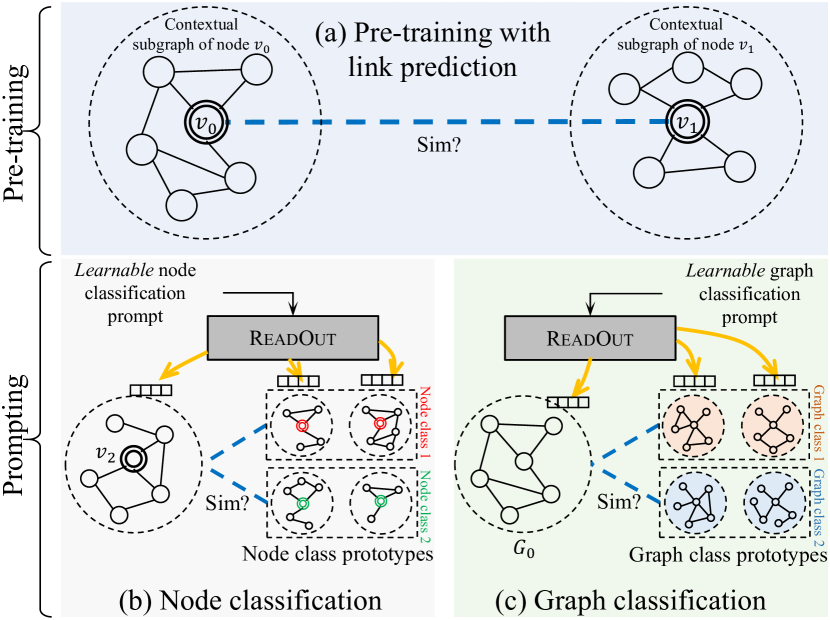
0
Generalized Graph Prompt: Toward a Unification of Pre-Training and Downstream Tasks on Graphs
Xingtong Yu, Zhenghao Liu, Yuan Fang, Zemin Liu, Sihong Chen, Xinming Zhang
Graph neural networks have emerged as a powerful tool for graph representation learning, but their performance heavily relies on abundant task-specific supervision. To reduce labeling requirement, the pre-train, prompt paradigms have become increasingly common. However, existing study of prompting on graphs is limited, lacking a universal treatment to appeal to different downstream tasks. In this paper, we propose GraphPrompt, a novel pre-training and prompting framework on graphs. GraphPrompt not only unifies pre-training and downstream tasks into a common task template but also employs a learnable prompt to assist a downstream task in locating the most relevant knowledge from the pre-trained model in a task-specific manner. To further enhance GraphPrompt in these two stages, we extend it into GraphPrompt+ with two major enhancements. First, we generalize several popular graph pre-training tasks beyond simple link prediction to broaden the compatibility with our task template. Second, we propose a more generalized prompt design that incorporates a series of prompt vectors within every layer of the pre-trained graph encoder, in order to capitalize on the hierarchical information across different layers beyond just the readout layer. Finally, we conduct extensive experiments on five public datasets to evaluate and analyze GraphPrompt and GraphPrompt+.
Read more8/27/2024

0
Self-Pro: Self-Prompt and Tuning Framework for Graph Neural Networks
Chenghua Gong, Xiang Li, Jianxiang Yu, Cheng Yao, Jiaqi Tan, Chengcheng Yu
Graphs have become an important modeling tool for web applications, and Graph Neural Networks (GNNs) have achieved great success in graph representation learning. However, the performance of traditional GNNs heavily relies on a large amount of supervision. Recently, ``pre-train, fine-tune'' has become the paradigm to address the issues of label dependency and poor generalization. However, the pre-training strategies vary for graphs with homophily and heterophily, and the objectives for various downstream tasks also differ. This leads to a gap between pretexts and downstream tasks, resulting in ``negative transfer'' and poor performance. Inspired by prompt learning in Natural Language Processing (NLP), many studies turn to bridge the gap and fully leverage the pre-trained model. However, existing methods for graph prompting are tailored to homophily, neglecting inherent heterophily on graphs. Meanwhile, most of them rely on the randomly initialized prompts, which negatively impact on the stability. Therefore, we propose Self-Prompt, a prompting framework for graphs based on the model and data itself. We first introduce asymmetric graph contrastive learning for pretext to address heterophily and align the objectives of pretext and downstream tasks. Then we reuse the component from pre-training phase as the self adapter and introduce self-prompts based on graph itself for task adaptation. Finally, we conduct extensive experiments on 11 benchmark datasets to demonstrate its superiority. We provide our codes at https://github.com/gongchenghua/Self-Pro.
Read more6/5/2024