Promoting Exploration in Memory-Augmented Adam using Critical Momenta
2307.09638
0
0
⚙️
Abstract
Adaptive gradient-based optimizers, notably Adam, have left their mark in training large-scale deep learning models, offering fast convergence and robustness to hyperparameter settings. However, they often struggle with generalization, attributed to their tendency to converge to sharp minima in the loss landscape. To address this, we propose a new memory-augmented version of Adam that encourages exploration towards flatter minima by incorporating a buffer of critical momentum terms during training. This buffer prompts the optimizer to overshoot beyond narrow minima, promoting exploration. Through comprehensive analysis in simple settings, we illustrate the efficacy of our approach in increasing exploration and bias towards flatter minima. We empirically demonstrate that it can improve model performance for image classification on ImageNet and CIFAR10/100, language modelling on Penn Treebank, and online learning tasks on TinyImageNet and 5-dataset. Our code is available at url{https://github.com/chandar-lab/CMOptimizer}.
Create account to get full access
Overview
- The paper proposes a new memory-augmented version of the popular Adam optimizer to improve generalization in deep learning models.
- Adam, a widely-used adaptive gradient-based optimizer, often struggles with generalization due to its tendency to converge to sharp minima in the loss landscape.
- The proposed approach, called "CMOptimizer," incorporates a buffer of critical momentum terms to encourage exploration towards flatter minima, which can lead to better generalization.
- The authors provide comprehensive analysis and empirical demonstrations of the benefits of their approach on various tasks, including image classification, language modeling, and online learning.
Plain English Explanation
The paper tackles a problem with a popular algorithm used to train deep learning models, called the Adam optimizer. Adam is known for its fast convergence and robustness to hyperparameter settings, but it often struggles with helping the model generalize well to new data. This is because Adam tends to converge to "sharp" minima in the loss landscape, which means the model performs well on the training data but not as well on new, unseen data.
To address this issue, the researchers propose a new version of Adam called "CMOptimizer" that encourages the model to explore "flatter" minima in the loss landscape. This is achieved by incorporating a buffer of critical momentum terms during training, which prompts the optimizer to overshoot beyond narrow minima and explore more of the landscape.
Through various experiments, the authors demonstrate that CMOptimizer can improve model performance on tasks like image classification, language modeling, and online learning, compared to the standard Adam optimizer. The key idea is to strike a better balance between exploiting the current solution and exploring the broader landscape, which can lead to better generalization.
Technical Explanation
The paper introduces a new memory-augmented version of the Adam optimizer, called "CMOptimizer," which aims to improve the generalization performance of deep learning models. The Adam optimizer, while known for its fast convergence and robustness to hyperparameter settings, often struggles with generalization due to its tendency to converge to sharp minima in the loss landscape.
To address this issue, the authors propose incorporating a buffer of critical momentum terms during the training process. This buffer prompts the optimizer to overshoot beyond narrow minima, encouraging exploration and bias towards flatter minima in the loss landscape. The authors provide a comprehensive analysis of their approach in simple settings, illustrating its efficacy in increasing exploration and bias towards flatter minima.
Empirically, the authors demonstrate that CMOptimizer can improve model performance for a variety of tasks, including image classification on ImageNet and CIFAR10/100, language modeling on Penn Treebank, and online learning tasks on TinyImageNet and 5-dataset. The authors make their code available at https://github.com/chandar-lab/CMOptimizer.
Critical Analysis
The paper presents a novel approach to addressing the generalization issues associated with the popular Adam optimizer. The proposed CMOptimizer introduces an interesting mechanism to encourage exploration towards flatter minima in the loss landscape, which aligns with recent research on the benefits of such minima for generalization [1, 2].
However, the paper does not provide a deep analysis of the underlying reasons for the performance improvements, and the authors acknowledge that further investigation is needed to fully understand the dynamics of the CMOptimizer. Additionally, the authors only compare their approach to the standard Adam optimizer and do not consider other recent adaptive optimizers [3, 4] that may offer different trade-offs between convergence and generalization.
It would be valuable for the authors to explore the sensitivity of CMOptimizer to hyperparameter settings, as well as its performance on a wider range of tasks and datasets. Furthermore, a comparison to non-adaptive optimization methods, such as [5], could provide additional insights into the strengths and limitations of the proposed approach.
Conclusion
The paper introduces a novel memory-augmented version of the Adam optimizer, called CMOptimizer, which aims to improve the generalization performance of deep learning models. By incorporating a buffer of critical momentum terms, CMOptimizer encourages exploration towards flatter minima in the loss landscape, addressing a key limitation of the standard Adam optimizer.
The authors provide comprehensive analysis and empirical demonstrations of the benefits of their approach on various tasks, including image classification, language modeling, and online learning. While the paper presents a promising direction for improving generalization in deep learning, further research is needed to fully understand the dynamics and potential limitations of the CMOptimizer approach.
[1] Conjugate Gradient-like Based Adaptive Moment Estimation [2] AdaLoMo: Low Memory Optimization with Adaptive Learning Rates [3] MOMO: Momentum Models with Adaptive Learning Rates [4] MADA: Meta-Adaptive Optimizers through Hyper-Gradient [5] MicroAdam: Accurate Adaptive Optimization with Low Space Overhead
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MicroAdam: Accurate Adaptive Optimization with Low Space Overhead and Provable Convergence
Ionut-Vlad Modoranu, Mher Safaryan, Grigory Malinovsky, Eldar Kurtic, Thomas Robert, Peter Richtarik, Dan Alistarh
0
0
We propose a new variant of the Adam optimizer [Kingma and Ba, 2014] called MICROADAM that specifically minimizes memory overheads, while maintaining theoretical convergence guarantees. We achieve this by compressing the gradient information before it is fed into the optimizer state, thereby reducing its memory footprint significantly. We control the resulting compression error via a novel instance of the classical error feedback mechanism from distributed optimization [Seide et al., 2014, Alistarh et al., 2018, Karimireddy et al., 2019] in which the error correction information is itself compressed to allow for practical memory gains. We prove that the resulting approach maintains theoretical convergence guarantees competitive to those of AMSGrad, while providing good practical performance. Specifically, we show that MICROADAM can be implemented efficiently on GPUs: on both million-scale (BERT) and billion-scale (LLaMA) models, MicroAdam provides practical convergence competitive to that of the uncompressed Adam baseline, with lower memory usage and similar running time. Our code is available at https://github.com/IST-DASLab/MicroAdam.
5/27/2024
Conjugate-Gradient-like Based Adaptive Moment Estimation Optimization Algorithm for Deep Learning
Jiawu Tian, Liwei Xu, Xiaowei Zhang, Yongqi Li
0
0
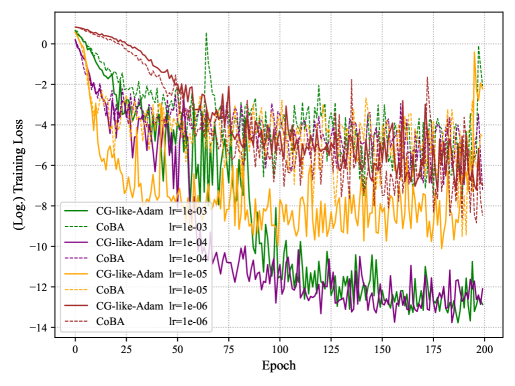
Training deep neural networks is a challenging task. In order to speed up training and enhance the performance of deep neural networks, we rectify the vanilla conjugate gradient as conjugate-gradient-like and incorporate it into the generic Adam, and thus propose a new optimization algorithm named CG-like-Adam for deep learning. Specifically, both the first-order and the second-order moment estimation of generic Adam are replaced by the conjugate-gradient-like. Convergence analysis handles the cases where the exponential moving average coefficient of the first-order moment estimation is constant and the first-order moment estimation is unbiased. Numerical experiments show the superiority of the proposed algorithm based on the CIFAR10/100 dataset.
5/14/2024
MADA: Meta-Adaptive Optimizers through hyper-gradient Descent
Kaan Ozkara, Can Karakus, Parameswaran Raman, Mingyi Hong, Shoham Sabach, Branislav Kveton, Volkan Cevher
0
0
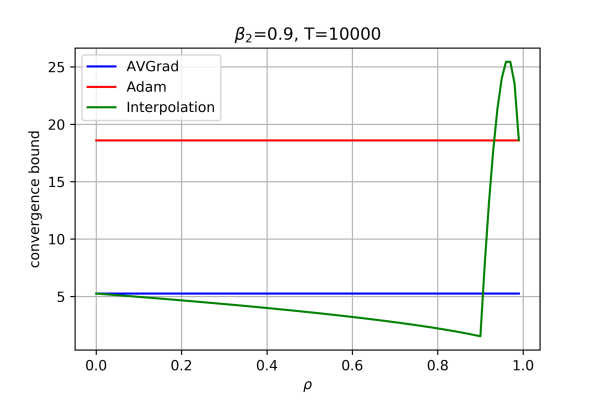
Following the introduction of Adam, several novel adaptive optimizers for deep learning have been proposed. These optimizers typically excel in some tasks but may not outperform Adam uniformly across all tasks. In this work, we introduce Meta-Adaptive Optimizers (MADA), a unified optimizer framework that can generalize several known optimizers and dynamically learn the most suitable one during training. The key idea in MADA is to parameterize the space of optimizers and dynamically search through it using hyper-gradient descent during training. We empirically compare MADA to other popular optimizers on vision and language tasks, and find that MADA consistently outperforms Adam and other popular optimizers, and is robust against sub-optimally tuned hyper-parameters. MADA achieves a greater validation performance improvement over Adam compared to other popular optimizers during GPT-2 training and fine-tuning. We also propose AVGrad, a modification of AMSGrad that replaces the maximum operator with averaging, which is more suitable for hyper-gradient optimization. Finally, we provide a convergence analysis to show that parameterized interpolations of optimizers can improve their error bounds (up to constants), hinting at an advantage for meta-optimizers.
6/18/2024

AdaLomo: Low-memory Optimization with Adaptive Learning Rate
Kai Lv, Hang Yan, Qipeng Guo, Haijun Lv, Xipeng Qiu
0
0
Large language models have achieved remarkable success, but their extensive parameter size necessitates substantial memory for training, thereby setting a high threshold. While the recently proposed low-memory optimization (LOMO) reduces memory footprint, its optimization technique, akin to stochastic gradient descent, is sensitive to hyper-parameters and exhibits suboptimal convergence, failing to match the performance of the prevailing optimizer for large language models, AdamW. Through empirical analysis of the Adam optimizer, we found that, compared to momentum, the adaptive learning rate is more critical for bridging the gap. Building on this insight, we introduce the low-memory optimization with adaptive learning rate (AdaLomo), which offers an adaptive learning rate for each parameter. To maintain memory efficiency, we employ non-negative matrix factorization for the second-order moment estimation in the optimizer state. Additionally, we suggest the use of a grouped update normalization to stabilize convergence. Our experiments with instruction-tuning and further pre-training demonstrate that AdaLomo achieves results on par with AdamW, while significantly reducing memory requirements, thereby lowering the hardware barrier to training large language models. The code is accessible at https://github.com/OpenLMLab/LOMO.
6/7/2024