MADA: Meta-Adaptive Optimizers through hyper-gradient Descent
2401.08893
0
0
Abstract
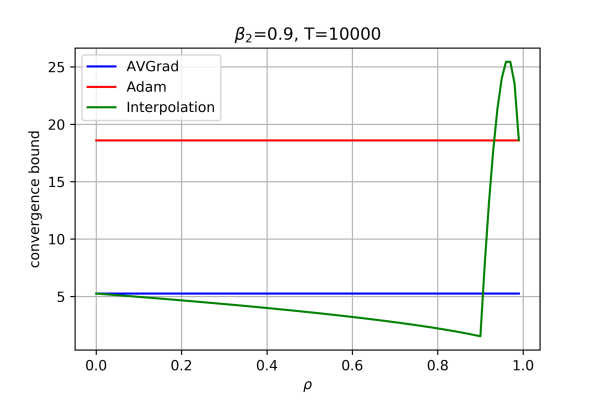
Following the introduction of Adam, several novel adaptive optimizers for deep learning have been proposed. These optimizers typically excel in some tasks but may not outperform Adam uniformly across all tasks. In this work, we introduce Meta-Adaptive Optimizers (MADA), a unified optimizer framework that can generalize several known optimizers and dynamically learn the most suitable one during training. The key idea in MADA is to parameterize the space of optimizers and dynamically search through it using hyper-gradient descent during training. We empirically compare MADA to other popular optimizers on vision and language tasks, and find that MADA consistently outperforms Adam and other popular optimizers, and is robust against sub-optimally tuned hyper-parameters. MADA achieves a greater validation performance improvement over Adam compared to other popular optimizers during GPT-2 training and fine-tuning. We also propose AVGrad, a modification of AMSGrad that replaces the maximum operator with averaging, which is more suitable for hyper-gradient optimization. Finally, we provide a convergence analysis to show that parameterized interpolations of optimizers can improve their error bounds (up to constants), hinting at an advantage for meta-optimizers.
Create account to get full access
Overview
- This paper proposes a novel class of "meta-adaptive" optimizers that can automatically tune their own hyperparameters during training using techniques from bilevel optimization.
- The key idea is to treat the optimizer's hyperparameters as learnable parameters that can be updated through gradient-based optimization, allowing the optimizer to adapt its own behavior to the specific problem at hand.
- The authors demonstrate the effectiveness of this approach on a range of benchmark tasks, showing improvements over standard optimizers like AdaGrad, ADAM, and BADAM.
Plain English Explanation
The paper introduces a new type of optimization algorithm, called a "meta-adaptive" optimizer, that can automatically adjust its own hyperparameters during the training process. Hyperparameters are settings that control how the optimizer behaves, like the learning rate or momentum.
Typically, you have to manually tune these hyperparameters for each problem you're trying to solve, which can be time-consuming and require a lot of trial and error. The key insight of this paper is to treat the hyperparameters as learnable parameters that can be updated through gradient-based optimization, just like the model parameters.
This allows the optimizer to adapt its own behavior to best suit the problem at hand, without the need for manual tuning. The authors show that this approach outperforms standard optimizers like AdaGrad, ADAM, and BADAM on a variety of benchmark tasks.
Technical Explanation
The authors propose a class of "meta-adaptive" optimizers that can automatically tune their own hyperparameters during training. They achieve this by treating the hyperparameters as learnable parameters that can be updated through gradient-based optimization, using techniques from bilevel optimization.
Specifically, the authors define a upper-level optimization problem, where the goal is to find the optimal hyperparameters that minimize the loss on a validation set. They then differentiate through this upper-level problem to compute gradients of the hyperparameters, and use these gradients to update the hyperparameters during training.
The authors demonstrate the effectiveness of this approach on a range of benchmark tasks, including training deep neural networks on image classification and reinforcement learning problems. They show that the meta-adaptive optimizers outperform standard optimizers like AdaGrad, ADAM, and BADAM in terms of both final performance and optimization efficiency.
Critical Analysis
One potential limitation of the meta-adaptive optimizer approach is the computational overhead of differentiating through the upper-level optimization problem to compute the hyperparameter gradients. This may limit the scalability of the method to very large-scale problems or real-time applications.
Additionally, the paper does not provide a thorough analysis of the hyperparameter trajectories or the interpretability of the learned hyperparameters. It would be interesting to understand how the hyperparameters evolve during training and whether they provide any insights into the problem structure or the model dynamics.
Furthermore, the paper focuses on a relatively narrow set of benchmark tasks, and it would be valuable to see how the meta-adaptive optimizers perform on a wider range of applications, including domains beyond deep learning, such as reinforcement learning or optimization.
Conclusion
Overall, the paper presents an interesting and potentially impactful approach to optimizing machine learning models by automatically tuning the optimizer's own hyperparameters. The meta-adaptive optimizers demonstrate strong empirical performance, suggesting that this line of research could lead to more robust and efficient optimization algorithms that can adapt to the specific characteristics of a given problem.
While the method has some computational overhead and may require further analysis and validation, the core idea of treating optimizer hyperparameters as learnable parameters is a promising direction that could inspire future work in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GeoAdaLer: Geometric Insights into Adaptive Stochastic Gradient Descent Algorithms
Chinedu Eleh, Masuzyo Mwanza, Ekene Aguegboh, Hans-Werner van Wyk
0
0
The Adam optimization method has achieved remarkable success in addressing contemporary challenges in stochastic optimization. This method falls within the realm of adaptive sub-gradient techniques, yet the underlying geometric principles guiding its performance have remained shrouded in mystery, and have long confounded researchers. In this paper, we introduce GeoAdaLer (Geometric Adaptive Learner), a novel adaptive learning method for stochastic gradient descent optimization, which draws from the geometric properties of the optimization landscape. Beyond emerging as a formidable contender, the proposed method extends the concept of adaptive learning by introducing a geometrically inclined approach that enhances the interpretability and effectiveness in complex optimization scenarios
5/28/2024

MicroAdam: Accurate Adaptive Optimization with Low Space Overhead and Provable Convergence
Ionut-Vlad Modoranu, Mher Safaryan, Grigory Malinovsky, Eldar Kurtic, Thomas Robert, Peter Richtarik, Dan Alistarh
0
0
We propose a new variant of the Adam optimizer [Kingma and Ba, 2014] called MICROADAM that specifically minimizes memory overheads, while maintaining theoretical convergence guarantees. We achieve this by compressing the gradient information before it is fed into the optimizer state, thereby reducing its memory footprint significantly. We control the resulting compression error via a novel instance of the classical error feedback mechanism from distributed optimization [Seide et al., 2014, Alistarh et al., 2018, Karimireddy et al., 2019] in which the error correction information is itself compressed to allow for practical memory gains. We prove that the resulting approach maintains theoretical convergence guarantees competitive to those of AMSGrad, while providing good practical performance. Specifically, we show that MICROADAM can be implemented efficiently on GPUs: on both million-scale (BERT) and billion-scale (LLaMA) models, MicroAdam provides practical convergence competitive to that of the uncompressed Adam baseline, with lower memory usage and similar running time. Our code is available at https://github.com/IST-DASLab/MicroAdam.
5/27/2024

BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models
Qijun Luo, Hengxu Yu, Xiao Li
0
0
This work presents BAdam, an optimization method that leverages the block coordinate descent framework with Adam as the inner solver. BAdam offers a memory efficient approach to the full parameter finetuning of large language models. We conduct theoretical convergence analysis for BAdam in the deterministic case. Experimentally, we apply BAdam to instruction-tune the Llama 2-7B and Llama 3-8B models using a single RTX3090-24GB GPU. The results confirm BAdam's efficiency in terms of memory and running time. Additionally, the convergence verification indicates that BAdam exhibits superior convergence behavior compared to LoRA. Furthermore, the downstream performance evaluation using the MT-bench shows that BAdam modestly surpasses LoRA and more substantially outperforms LOMO. Finally, we compare BAdam with Adam on a medium-sized task, i.e., finetuning RoBERTa-large on the SuperGLUE benchmark. The results demonstrate that BAdam is capable of narrowing the performance gap with Adam more effectively than LoRA. Our code is available at https://github.com/Ledzy/BAdam.
5/24/2024
⚙️
Promoting Exploration in Memory-Augmented Adam using Critical Momenta
Pranshu Malviya, Gonc{c}alo Mordido, Aristide Baratin, Reza Babanezhad Harikandeh, Jerry Huang, Simon Lacoste-Julien, Razvan Pascanu, Sarath Chandar
0
0
Adaptive gradient-based optimizers, notably Adam, have left their mark in training large-scale deep learning models, offering fast convergence and robustness to hyperparameter settings. However, they often struggle with generalization, attributed to their tendency to converge to sharp minima in the loss landscape. To address this, we propose a new memory-augmented version of Adam that encourages exploration towards flatter minima by incorporating a buffer of critical momentum terms during training. This buffer prompts the optimizer to overshoot beyond narrow minima, promoting exploration. Through comprehensive analysis in simple settings, we illustrate the efficacy of our approach in increasing exploration and bias towards flatter minima. We empirically demonstrate that it can improve model performance for image classification on ImageNet and CIFAR10/100, language modelling on Penn Treebank, and online learning tasks on TinyImageNet and 5-dataset. Our code is available at url{https://github.com/chandar-lab/CMOptimizer}.
6/19/2024