Prompt-Consistency Image Generation (PCIG): A Unified Framework Integrating LLMs, Knowledge Graphs, and Controllable Diffusion Models

0

Sign in to get full access
Overview
- This paper proposes a unified framework called Prompt-Consistency Image Generation (PCIG) that integrates Large Language Models (LLMs), Knowledge Graphs, and Controllable Diffusion Models to generate high-quality images from textual prompts.
- The key idea is to leverage the strengths of LLMs for understanding and generating prompts, knowledge graphs for grounding prompts in facts and commonsense, and diffusion models for generating diverse and realistic images.
- The framework aims to produce images that are consistent with the provided textual prompts, addressing limitations of existing text-to-image generation approaches.
Plain English Explanation
The paper introduces a new system called Prompt-Consistency Image Generation (PCIG) that can create images based on written descriptions. This is done by combining three key technologies:
-
Large Language Models (LLMs): These are powerful AI systems that can understand and generate human-like text. LLMs are used to interpret the written prompts and ensure the generated images match the intended meaning.
-
Knowledge Graphs: These are structured databases of facts and relationships. PCIG uses knowledge graphs to ground the text prompts in real-world knowledge, helping the system understand the context and create more coherent images.
-
Diffusion Models: These are AI models that can generate highly detailed and realistic images. PCIG uses diffusion models to actually create the visual output based on the interpreted prompt and grounded knowledge.
The key advantage of PCIG is that it can generate images that are consistently aligned with the provided text descriptions, overcoming limitations of existing text-to-image systems. By integrating these three components, PCIG aims to produce images that are both visually compelling and semantically meaningful.
Technical Explanation
The PCIG framework consists of three main components:
-
Prompt Encoder: This module uses a Large Language Model (LLM) to encode the input text prompt into a high-dimensional representation that captures the semantic and syntactic meaning.
-
Knowledge Graph Reasoner: This component retrieves relevant factual knowledge from a knowledge graph based on the encoded prompt. The knowledge is used to ground the prompt in real-world concepts and relationships.
-
Diffusion-based Image Generator: This is a Controllable Diffusion Model that generates the final image based on the encoded prompt and the grounded knowledge. The diffusion process allows for diverse and realistic image outputs.
The key innovation of PCIG is the tight integration of these three modules. The Prompt Encoder and Knowledge Graph Reasoner work together to translate the textual prompt into a structured representation that the Diffusion-based Image Generator can use to produce high-quality, prompt-consistent images.
This approach addresses limitations of prior text-to-image methods, such as DALL-E and GLIDE, which may struggle with maintaining consistency between the prompt and the generated image. By incorporating knowledge-grounding and controlled diffusion, PCIG aims to generate images that are both visually appealing and semantically aligned with the input text.
Critical Analysis
The PCIG framework represents an important advancement in text-to-image generation, addressing key limitations of prior approaches. However, the paper also acknowledges several caveats and areas for further research:
-
Scaling and Efficiency: The integration of LLMs, knowledge graphs, and diffusion models may present challenges in terms of computational complexity and memory requirements, especially for large-scale deployment. Further optimizations may be needed to improve the efficiency of the system.
-
Knowledge Graph Coverage: The performance of the Knowledge Graph Reasoner component is dependent on the breadth and depth of the underlying knowledge graph. Expanding the knowledge base or developing techniques to handle missing or incomplete knowledge could further improve the system's capabilities.
-
Prompt Ambiguity: While PCIG aims to improve prompt-consistency, complex or ambiguous prompts may still pose challenges. Exploring techniques to handle ambiguity, context-awareness, and multi-modal interactions could be fruitful areas for future research.
-
Evaluation Metrics: The paper introduces new evaluation metrics to assess prompt-consistency, but the validity and generalizability of these metrics could be further investigated and validated by the research community.
Overall, the PCIG framework represents a significant step forward in text-to-image generation, but continued research and development will be necessary to address the identified limitations and unlock the full potential of this approach.
Conclusion
The Prompt-Consistency Image Generation (PCIG) framework proposed in this paper presents a novel and promising approach to generating high-quality images from textual prompts. By integrating Large Language Models, Knowledge Graphs, and Controllable Diffusion Models, PCIG aims to produce images that are visually compelling and semantically aligned with the input text.
The key innovation of PCIG is its ability to leverage the complementary strengths of these three core technologies to address limitations of existing text-to-image generation methods. This unified framework has the potential to significantly advance the field of multimodal AI, with applications in areas such as creative content generation, information visualization, and human-computer interaction.
While the paper identifies several areas for further research and optimization, the PCIG framework represents an important step towards more robust and versatile text-to-image generation capabilities. As the field continues to evolve, the insights and techniques presented in this work are likely to have a lasting impact on the development of future multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompt-Consistency Image Generation (PCIG): A Unified Framework Integrating LLMs, Knowledge Graphs, and Controllable Diffusion Models
Yichen Sun, Zhixuan Chu, Zhan Qin, Kui Ren
The rapid advancement of Text-to-Image(T2I) generative models has enabled the synthesis of high-quality images guided by textual descriptions. Despite this significant progress, these models are often susceptible in generating contents that contradict the input text, which poses a challenge to their reliability and practical deployment. To address this problem, we introduce a novel diffusion-based framework to significantly enhance the alignment of generated images with their corresponding descriptions, addressing the inconsistency between visual output and textual input. Our framework is built upon a comprehensive analysis of inconsistency phenomena, categorizing them based on their manifestation in the image. Leveraging a state-of-the-art large language module, we first extract objects and construct a knowledge graph to predict the locations of these objects in potentially generated images. We then integrate a state-of-the-art controllable image generation model with a visual text generation module to generate an image that is consistent with the original prompt, guided by the predicted object locations. Through extensive experiments on an advanced multimodal hallucination benchmark, we demonstrate the efficacy of our approach in accurately generating the images without the inconsistency with the original prompt. The code can be accessed via https://github.com/TruthAI-Lab/PCIG.
Read more6/26/2024

0
PCQA: A Strong Baseline for AIGC Quality Assessment Based on Prompt Condition
Xi Fang, Weigang Wang, Xiaoxin Lv, Jun Yan
The development of Large Language Models (LLM) and Diffusion Models brings the boom of Artificial Intelligence Generated Content (AIGC). It is essential to build an effective quality assessment framework to provide a quantifiable evaluation of different images or videos based on the AIGC technologies. The content generated by AIGC methods is driven by the crafted prompts. Therefore, it is intuitive that the prompts can also serve as the foundation of the AIGC quality assessment. This study proposes an effective AIGC quality assessment (QA) framework. First, we propose a hybrid prompt encoding method based on a dual-source CLIP (Contrastive Language-Image Pre-Training) text encoder to understand and respond to the prompt conditions. Second, we propose an ensemble-based feature mixer module to effectively blend the adapted prompt and vision features. The empirical study practices in two datasets: AIGIQA-20K (AI-Generated Image Quality Assessment database) and T2VQA-DB (Text-to-Video Quality Assessment DataBase), which validates the effectiveness of our proposed method: Prompt Condition Quality Assessment (PCQA). Our proposed simple and feasible framework may promote research development in the multimodal generation field.
Read more4/23/2024
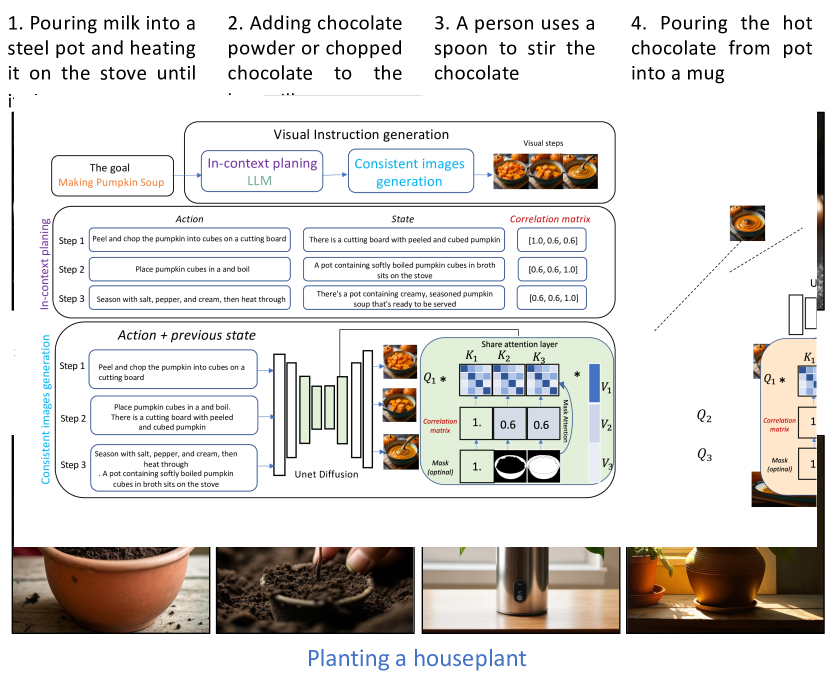
0
Coherent Zero-Shot Visual Instruction Generation
Quynh Phung, Songwei Ge, Jia-Bin Huang
Despite the advances in text-to-image synthesis, particularly with diffusion models, generating visual instructions that require consistent representation and smooth state transitions of objects across sequential steps remains a formidable challenge. This paper introduces a simple, training-free framework to tackle the issues, capitalizing on the advancements in diffusion models and large language models (LLMs). Our approach systematically integrates text comprehension and image generation to ensure visual instructions are visually appealing and maintain consistency and accuracy throughout the instruction sequence. We validate the effectiveness by testing multi-step instructions and comparing the text alignment and consistency with several baselines. Our experiments show that our approach can visualize coherent and visually pleasing instructions
Read more6/11/2024

0
Unified Text-to-Image Generation and Retrieval
Leigang Qu, Haochuan Li, Tan Wang, Wenjie Wang, Yongqi Li, Liqiang Nie, Tat-Seng Chua
How humans can efficiently and effectively acquire images has always been a perennial question. A typical solution is text-to-image retrieval from an existing database given the text query; however, the limited database typically lacks creativity. By contrast, recent breakthroughs in text-to-image generation have made it possible to produce fancy and diverse visual content, but it faces challenges in synthesizing knowledge-intensive images. In this work, we rethink the relationship between text-to-image generation and retrieval and propose a unified framework in the context of Multimodal Large Language Models (MLLMs). Specifically, we first explore the intrinsic discriminative abilities of MLLMs and introduce a generative retrieval method to perform retrieval in a training-free manner. Subsequently, we unify generation and retrieval in an autoregressive generation way and propose an autonomous decision module to choose the best-matched one between generated and retrieved images as the response to the text query. Additionally, we construct a benchmark called TIGeR-Bench, including creative and knowledge-intensive domains, to standardize the evaluation of unified text-to-image generation and retrieval. Extensive experimental results on TIGeR-Bench and two retrieval benchmarks, i.e., Flickr30K and MS-COCO, demonstrate the superiority and effectiveness of our proposed method.
Read more6/11/2024