Prompt Tuning on Graph-augmented Low-resource Text Classification

0
🏷️
Sign in to get full access
Overview
- Text classification is a fundamental problem in information retrieval with many real-world applications.
- Low-resource text classification, with no or few labeled samples, presents a serious concern for supervised learning.
- Many text data are inherently grounded on a network structure, which can potentially augment low-resource text classification.
Plain English Explanation
The paper presents a novel approach called Graph-Grounded Pre-training and Prompting (G2P2) to address the challenge of low-resource text classification. Text classification is the task of assigning categories or labels to pieces of text, such as predicting the topics of online articles or the categories of e-commerce product descriptions. This is a fundamental problem in information retrieval with many practical applications.
However, low-resource text classification, where there are no or only a few labeled samples available for training, poses a significant challenge for traditional supervised learning methods. The paper proposes that many text data are inherently grounded on a network structure, such as a hyperlink network for online articles or a user-item purchase network for e-commerce products. These graph structures capture rich semantic relationships that can potentially be leveraged to improve the performance of low-resource text classification.
Technical Explanation
The paper's Graph-Grounded Pre-training and Prompting (G2P2) model takes a two-pronged approach to address low-resource text classification:
-
Pre-training: During the pre-training stage, the model uses three graph interaction-based contrastive strategies to jointly pre-train a graph-text model.
-
Downstream Classification: For the downstream text classification task, the model explores handcrafted discrete prompts and continuous prompt tuning to achieve zero-shot and few-shot classification, respectively.
Furthermore, the paper explores the possibility of employing continuous prompt tuning for zero-shot inference. Specifically, it aims to generalize continuous prompts to unseen classes while leveraging a set of base classes. To this end, the paper extends the G2P2 model into G2P2$^*$, which introduces a new architecture of conditional prompt tuning.
Critical Analysis
The paper presents a comprehensive approach to addressing the challenge of low-resource text classification by leveraging the inherent graph structure of text data. The proposed G2P2 and G2P2$^*$ models demonstrate strong performance in zero-shot and few-shot classification tasks, which is a significant achievement.
However, the paper does not discuss the computational complexity or training time of the proposed models, which could be important considerations for practical applications. Additionally, the paper could have explored the robustness of the models to different types of graph structures or the impact of the quality and coverage of the base classes on the zero-shot classification performance.
Conclusion
The paper's Graph-Grounded Pre-training and Prompting (G2P2) approach presents a promising solution to the challenge of low-resource text classification. By leveraging the inherent graph structure of text data and employing pre-training and prompt-based techniques, the proposed models demonstrate strong performance in zero-shot and few-shot classification tasks. This research has the potential to significantly improve the applicability of text classification in a wide range of real-world scenarios with limited labeled data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Prompt Tuning on Graph-augmented Low-resource Text Classification
Zhihao Wen, Yuan Fang
Text classification is a fundamental problem in information retrieval with many real-world applications, such as predicting the topics of online articles and the categories of e-commerce product descriptions. However, low-resource text classification, with no or few labeled samples, presents a serious concern for supervised learning. Meanwhile, many text data are inherently grounded on a network structure, such as a hyperlink/citation network for online articles, and a user-item purchase network for e-commerce products. These graph structures capture rich semantic relationships, which can potentially augment low-resource text classification. In this paper, we propose a novel model called Graph-Grounded Pre-training and Prompting (G2P2) to address low-resource text classification in a two-pronged approach. During pre-training, we propose three graph interaction-based contrastive strategies to jointly pre-train a graph-text model; during downstream classification, we explore handcrafted discrete prompts and continuous prompt tuning for the jointly pre-trained model to achieve zero- and few-shot classification, respectively. Moreover, we explore the possibility of employing continuous prompt tuning for zero-shot inference. Specifically, we aim to generalize continuous prompts to unseen classes while leveraging a set of base classes. To this end, we extend G2P2 into G2P2$^*$, hinging on a new architecture of conditional prompt tuning. Extensive experiments on four real-world datasets demonstrate the strength of G2P2 in zero- and few-shot low-resource text classification tasks, and illustrate the advantage of G2P2$^*$ in dealing with unseen classes.
Read more8/20/2024
🧠
0
Universal Prompt Tuning for Graph Neural Networks
Taoran Fang, Yunchao Zhang, Yang Yang, Chunping Wang, Lei Chen
In recent years, prompt tuning has sparked a research surge in adapting pre-trained models. Unlike the unified pre-training strategy employed in the language field, the graph field exhibits diverse pre-training strategies, posing challenges in designing appropriate prompt-based tuning methods for graph neural networks. While some pioneering work has devised specialized prompting functions for models that employ edge prediction as their pre-training tasks, these methods are limited to specific pre-trained GNN models and lack broader applicability. In this paper, we introduce a universal prompt-based tuning method called Graph Prompt Feature (GPF) for pre-trained GNN models under any pre-training strategy. GPF operates on the input graph's feature space and can theoretically achieve an equivalent effect to any form of prompting function. Consequently, we no longer need to illustrate the prompting function corresponding to each pre-training strategy explicitly. Instead, we employ GPF to obtain the prompted graph for the downstream task in an adaptive manner. We provide rigorous derivations to demonstrate the universality of GPF and make guarantee of its effectiveness. The experimental results under various pre-training strategies indicate that our method performs better than fine-tuning, with an average improvement of about 1.4% in full-shot scenarios and about 3.2% in few-shot scenarios. Moreover, our method significantly outperforms existing specialized prompt-based tuning methods when applied to models utilizing the pre-training strategy they specialize in. These numerous advantages position our method as a compelling alternative to fine-tuning for downstream adaptations.
Read more4/11/2024

0
Pre-Training and Prompting for Few-Shot Node Classification on Text-Attributed Graphs
Huanjing Zhao, Beining Yang, Yukuo Cen, Junyu Ren, Chenhui Zhang, Yuxiao Dong, Evgeny Kharlamov, Shu Zhao, Jie Tang
The text-attributed graph (TAG) is one kind of important real-world graph-structured data with each node associated with raw texts. For TAGs, traditional few-shot node classification methods directly conduct training on the pre-processed node features and do not consider the raw texts. The performance is highly dependent on the choice of the feature pre-processing method. In this paper, we propose P2TAG, a framework designed for few-shot node classification on TAGs with graph pre-training and prompting. P2TAG first pre-trains the language model (LM) and graph neural network (GNN) on TAGs with self-supervised loss. To fully utilize the ability of language models, we adapt the masked language modeling objective for our framework. The pre-trained model is then used for the few-shot node classification with a mixed prompt method, which simultaneously considers both text and graph information. We conduct experiments on six real-world TAGs, including paper citation networks and product co-purchasing networks. Experimental results demonstrate that our proposed framework outperforms existing graph few-shot learning methods on these datasets with +18.98% ~ +35.98% improvements.
Read more7/23/2024
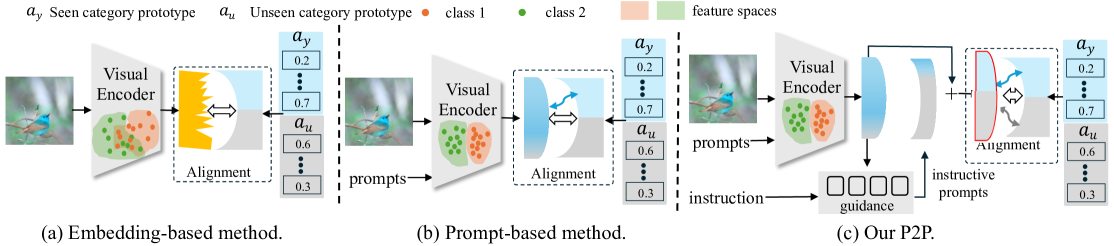
0
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Man Liu, Huihui Bai, Feng Li, Chunjie Zhang, Yunchao Wei, Meng Wang, Tat-Seng Chua, Yao Zhao
Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a textbf{P}rompt-to-textbf{P}rompt generation methodology (textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
Read more6/6/2024