Prompt Tuning Strikes Back: Customizing Foundation Models with Low-Rank Prompt Adaptation

0

Sign in to get full access
Overview
- This paper introduces a new method called "Prompt Tuning Strikes Back" for customizing large language models (foundation models) using low-rank prompt adaptation.
- The key idea is to fine-tune only a small number of prompt parameters instead of the entire model, making the process more efficient and less computationally expensive.
- The approach is evaluated on a range of natural language processing tasks and shows promising results, achieving performance comparable to full model fine-tuning while requiring much fewer parameters to be updated.
Plain English Explanation
Large language models like GPT-3 have become incredibly powerful and useful for a wide variety of natural language processing tasks. However, fine-tuning these models from scratch for a specific application can be computationally expensive and time-consuming.
The "Prompt Tuning Strikes Back" method offers a more efficient alternative. Instead of fine-tuning the entire model, it only updates a small number of prompt parameters. This allows the model to be customized for a particular task or domain while requiring far fewer changes to the underlying model weights.
The basic idea is to learn a low-rank transformation of the input prompt that can steer the model's predictions in the desired direction. This "prompt adaptation" process is much faster and more lightweight than full model fine-tuning, making it more accessible for many real-world applications.
The researchers evaluate this approach on a range of NLP tasks and find that it can match the performance of full fine-tuning, but with a significantly smaller computational footprint. This could enable more widespread and customized use of large language models, unlocking their potential for a variety of use cases.
Technical Explanation
The paper introduces a novel technique called "Prompt Tuning Strikes Back" for efficiently customizing large language models (LLMs) like GPT-3 for specific tasks or domains. Instead of fine-tuning the entire model, the method only updates a small number of prompt parameters, which allows the model to be adapted while requiring far fewer changes to the underlying model weights.
The core idea is to learn a low-rank transformation of the input prompt that can steer the model's predictions towards the desired output. This "prompt adaptation" process is achieved by introducing a small number of trainable prompt parameters that are combined with the original prompt using a linear transformation. The resulting "adapted prompt" is then fed into the LLM, which produces the final output.
The advantages of this approach are twofold. First, it is computationally much more efficient than full model fine-tuning, as only a small subset of the model parameters need to be updated. This makes the customization process faster and less resource-intensive, enabling more widespread use of LLMs. Second, the low-rank nature of the prompt adaptation ensures that the model's general capabilities are preserved, while still allowing for significant task-specific customization.
The researchers evaluate the "Prompt Tuning Strikes Back" method on a range of natural language processing tasks, including text classification, generation, and question answering. The results show that this approach can achieve performance on par with full model fine-tuning, while requiring much fewer parameters to be updated. This demonstrates the effectiveness of the low-rank prompt adaptation in customizing LLMs for specific applications.
Critical Analysis
The "Prompt Tuning Strikes Back" method presented in this paper offers a promising approach for efficiently customizing large language models for a variety of tasks. By only updating a small subset of the model parameters, the technique is able to achieve comparable performance to full fine-tuning while being significantly more computationally efficient.
One potential limitation of the approach is that it may not be able to capture all the nuances and complexities of a task that full fine-tuning could. The low-rank nature of the prompt adaptation, while beneficial for efficiency, may restrict the model's ability to learn highly specialized or complex task-specific features. This could be a concern for particularly challenging or domain-specific applications.
Additionally, the paper does not explore the limitations of the method in terms of the size or complexity of the target task. It's possible that for very large or intricate tasks, the prompt adaptation approach may struggle to achieve the same level of performance as full fine-tuning, even with its efficiency advantages.
Further research could also investigate the generalization capabilities of the prompt-adapted models. It would be interesting to see how well they perform on out-of-distribution or unseen data, and how the low-rank nature of the adaptation affects their robustness and versatility.
Despite these potential caveats, the "Prompt Tuning Strikes Back" method represents an important step forward in making large language models more accessible and customizable for a wide range of applications. As the field of efficient fine-tuning techniques continues to evolve, this work could inspire further innovations and contribute to the broader goal of making foundation models more practical and widely applicable.
Conclusion
The "Prompt Tuning Strikes Back" paper introduces a novel approach for efficiently customizing large language models using low-rank prompt adaptation. By only updating a small subset of the model parameters, the technique can achieve comparable performance to full fine-tuning while being significantly more computationally efficient.
This work has the potential to make large language models more accessible and widely applicable, as the reduced computational overhead allows for faster and more cost-effective model customization. While the method may have some limitations in capturing highly complex task-specific features, the overall approach represents an important step forward in the field of efficient fine-tuning techniques.
As the research in this area continues to evolve, the "Prompt Tuning Strikes Back" method could inspire further innovations and contribute to the broader goal of making foundation models more practical and widely usable across a variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompt Tuning Strikes Back: Customizing Foundation Models with Low-Rank Prompt Adaptation
Abhinav Jain, Swarat Chaudhuri, Thomas Reps, Chris Jermaine
Parameter-Efficient Fine-Tuning (PEFT) has become the standard for customising Foundation Models (FMs) to user-specific downstream tasks. However, typical PEFT methods require storing multiple task-specific adapters, creating scalability issues as these adapters must be housed and run at the FM server. Traditional prompt tuning offers a potential solution by customising them through task-specific input prefixes, but it under-performs compared to other PEFT methods like LoRA. To address this gap, we propose Low-Rank Prompt Adaptation (LOPA), a prompt-tuning-based approach that performs on par with state-of-the-art PEFT methods and full fine-tuning while being more parameter-efficient and not requiring a server-based adapter. LOPA generates soft prompts by balancing between sharing task-specific information across instances and customization for each instance. It uses a low-rank decomposition of the soft-prompt component encoded for each instance to achieve parameter efficiency. We provide a comprehensive evaluation on multiple natural language understanding and code generation and understanding tasks across a wide range of foundation models with varying sizes.
Read more5/27/2024
💬
0
LoPT: Low-Rank Prompt Tuning for Parameter Efficient Language Models
Shouchang Guo, Sonam Damani, Keng-hao Chang
In prompt tuning, a prefix or suffix text is added to the prompt, and the embeddings (soft prompts) or token indices (hard prompts) of the prefix/suffix are optimized to gain more control over language models for specific tasks. This approach eliminates the need for hand-crafted prompt engineering or explicit model fine-tuning. Prompt tuning is significantly more parameter-efficient than model fine-tuning, as it involves optimizing partial inputs of language models to produce desired outputs. In this work, we aim to further reduce the amount of trainable parameters required for a language model to perform well on specific tasks. We propose Low-rank Prompt Tuning (LoPT), a low-rank model for prompts that achieves efficient prompt optimization. The proposed method demonstrates similar outcomes to full parameter prompt tuning while reducing the number of trainable parameters by a factor of 5. It also provides promising results compared to the state-of-the-art methods that would require 10 to 20 times more parameters.
Read more7/1/2024

0
Choice of PEFT Technique in Continual Learning: Prompt Tuning is Not All You Need
Martin Wistuba, Prabhu Teja Sivaprasad, Lukas Balles, Giovanni Zappella
Recent Continual Learning (CL) methods have combined pretrained Transformers with prompt tuning, a parameter-efficient fine-tuning (PEFT) technique. We argue that the choice of prompt tuning in prior works was an undefended and unablated decision, which has been uncritically adopted by subsequent research, but warrants further research to understand its implications. In this paper, we conduct this research and find that the choice of prompt tuning as a PEFT method hurts the overall performance of the CL system. To illustrate this, we replace prompt tuning with LoRA in two state-of-the-art continual learning methods: Learning to Prompt and S-Prompts. These variants consistently achieve higher accuracy across a wide range of domain-incremental and class-incremental benchmarks, while being competitive in inference speed. Our work highlights a crucial argument: unexamined choices can hinder progress in the field, and rigorous ablations, such as the PEFT method, are required to drive meaningful adoption of CL techniques in real-world applications.
Read more6/6/2024
0
Customizing Large Language Model Generation Style using Parameter-Efficient Finetuning
Xinyue Liu, Harshita Diddee, Daphne Ippolito
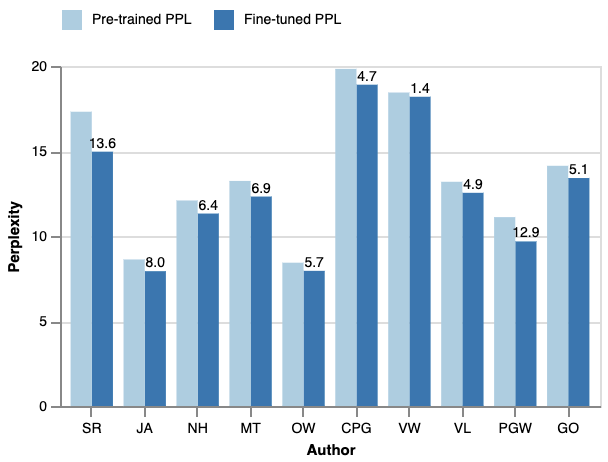
One-size-fits-all large language models (LLMs) are increasingly being used to help people with their writing. However, the style these models are trained to write in may not suit all users or use cases. LLMs would be more useful as writing assistants if their idiolect could be customized to match each user. In this paper, we explore whether parameter-efficient finetuning (PEFT) with Low-Rank Adaptation can effectively guide the style of LLM generations. We use this method to customize LLaMA-2 to ten different authors and show that the generated text has lexical, syntactic, and surface alignment with the target author but struggles with content memorization. Our findings highlight the potential of PEFT to support efficient, user-level customization of LLMs.
Read more9/10/2024