Protected Test-Time Adaptation via Online Entropy Matching: A Betting Approach

0

Sign in to get full access
Overview
- Proposes a method for "protected" test-time adaptation to improve model performance on new, unseen data
- Uses online entropy matching to adapt the model in a way that maintains robustness and stability
- Approaches adaptation as a betting game, with the model adapting its probability predictions to "bet" on the best outcomes
Plain English Explanation
The paper introduces a technique called "protected test-time adaptation" to help machine learning models perform better on new, unseen data during deployment. The key idea is to allow the model to adapt its predictions in a careful, controlled way, rather than making drastic changes that could harm performance.
The approach is inspired by the concept of a "betting game." Imagine you're at a casino, and you want to bet on the outcome of a game. You start with a certain amount of "chips" (i.e., your probability predictions), and as you observe more of the game unfold, you can gradually adjust your bets to maximize your winnings. This is similar to how the model adapts its predictions during test time - it starts with an initial set of probability estimates, and then carefully "bets" on the best outcomes as it sees more of the new data.
The researchers use a technique called "online entropy matching" to guide this adaptation process. The goal is to ensure that the model's updated predictions maintain a good balance between being confident in its predictions (high entropy) and remaining robust to potential distribution shifts (low entropy). This helps the model adapt in a way that improves performance without becoming overly confident or unstable.
By approaching test-time adaptation in this "protected" way, the model can leverage the benefits of adaptation while avoiding the potential downsides, such as catastrophic forgetting or overfitting to the new data. The researchers demonstrate the effectiveness of their approach on a variety of machine learning tasks, showing that it can outperform standard adaptation techniques.
Technical Explanation
The paper proposes a novel approach for "protected" test-time adaptation, which allows a machine learning model to adapt its predictions during deployment in a controlled and robust manner. The key idea is to frame the adaptation process as a "betting game," where the model gradually adjusts its probability estimates to "bet" on the best outcomes as it observes new, unseen data.
The core of the proposed method is the use of online entropy matching. This technique guides the adaptation process by ensuring that the model's updated predictions maintain a good balance between being confident in its predictions (high entropy) and remaining robust to potential distribution shifts (low entropy). This helps the model adapt in a way that improves performance without becoming overly confident or unstable.
The researchers formulate the adaptation problem as an optimization task, where the model aims to minimize the difference between its current predictions and the "best" predictions (as determined by the online entropy matching objective). This optimization is performed in an online fashion, allowing the model to adapt incrementally as new data becomes available.
The researchers evaluate their approach on a variety of machine learning tasks, including image classification, language modeling, and reinforcement learning. They show that their "protected" test-time adaptation method can outperform standard adaptation techniques, such as fine-tuning or domain-adversarial training, in terms of both performance and robustness.
Critical Analysis
The paper presents a well-designed and thorough investigation of the proposed "protected" test-time adaptation approach. The researchers provide a clear theoretical foundation for their method, grounding it in the concept of online entropy matching, and demonstrate its effectiveness across multiple domains.
One potential limitation of the approach is that it requires the model to have access to the true labels or rewards during the adaptation process. While this is a common assumption in the test-time adaptation literature, it may not always be realistic in real-world scenarios, where the true labels may not be immediately available. The researchers acknowledge this limitation and suggest exploring alternative approaches that can handle the absence of true labels.
Another area for further research could be exploring the scalability and computational efficiency of the proposed method, especially for large-scale or real-time applications. The online optimization process may introduce additional computational overhead, which could be a concern for certain deployment scenarios.
Finally, the paper focuses on the task-specific benefits of the "protected" test-time adaptation approach, but it would be interesting to investigate its broader implications for model robustness and trustworthiness. Exploring how this technique could be combined with other approaches, such as adversarial training or out-of-distribution detection, could lead to more comprehensive solutions for ensuring the reliability of machine learning models in the real world.
Conclusion
The paper presents a novel and well-designed approach for "protected" test-time adaptation, which allows machine learning models to adapt their predictions during deployment in a controlled and robust manner. By framing the adaptation process as a "betting game" and using online entropy matching to guide the updates, the proposed method can improve model performance on new, unseen data while maintaining stability and robustness.
The results demonstrate the effectiveness of this approach across a variety of tasks, suggesting that it could be a valuable tool for enhancing the real-world reliability and performance of machine learning systems. Furthermore, the theoretical foundations and the critical analysis provided in the paper offer insights and avenues for future research in the important area of test-time adaptation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Protected Test-Time Adaptation via Online Entropy Matching: A Betting Approach
Yarin Bar, Shalev Shaer, Yaniv Romano
We present a novel approach for test-time adaptation via online self-training, consisting of two components. First, we introduce a statistical framework that detects distribution shifts in the classifier's entropy values obtained on a stream of unlabeled samples. Second, we devise an online adaptation mechanism that utilizes the evidence of distribution shifts captured by the detection tool to dynamically update the classifier's parameters. The resulting adaptation process drives the distribution of test entropy values obtained from the self-trained classifier to match those of the source domain, building invariance to distribution shifts. This approach departs from the conventional self-training method, which focuses on minimizing the classifier's entropy. Our approach combines concepts in betting martingales and online learning to form a detection tool capable of quickly reacting to distribution shifts. We then reveal a tight relation between our adaptation scheme and optimal transport, which forms the basis of our novel self-supervised loss. Experimental results demonstrate that our approach improves test-time accuracy under distribution shifts while maintaining accuracy and calibration in their absence, outperforming leading entropy minimization methods across various scenarios.
Read more8/15/2024
🔗
0
Improving Entropy-Based Test-Time Adaptation from a Clustering View
Guoliang Lin, Hanjiang Lai, Yan Pan, Jian Yin
Domain shift is a common problem in the realistic world, where training data and test data follow different data distributions. To deal with this problem, fully test-time adaptation (TTA) leverages the unlabeled data encountered during test time to adapt the model. In particular, entropy-based TTA (EBTTA) methods, which minimize the prediction's entropy on test samples, have shown great success. In this paper, we introduce a new perspective on the EBTTA, which interprets these methods from a view of clustering. It is an iterative algorithm: 1) in the assignment step, the forward process of the EBTTA models is the assignment of labels for these test samples, and 2) in the updating step, the backward process is the update of the model via the assigned samples. Based on the interpretation, we can gain a deeper understanding of EBTTA. Accordingly, we offer an alternative explanation for why existing EBTTA methods are sensitive to initial assignments, nearest neighbor information, outliers, and batch size. This observation can guide us to put forward the improvement of EBTTA. We propose to use robust label assignment, locality-preserving constraint, sample selection, and gradient accumulation to alleviate the above problems. Experimental results demonstrate that our method can achieve consistent improvements on various datasets. Code is provided in the supplementary material.
Read more4/10/2024
0
Test-Time Adaptation with State-Space Models
Mona Schirmer, Dan Zhang, Eric Nalisnick
Distribution shifts between training and test data are all but inevitable over the lifecycle of a deployed model and lead to performance decay. Adapting the model can hopefully mitigate this drop in performance. Yet, adaptation is challenging since it must be unsupervised: we usually do not have access to any labeled data at test time. In this paper, we propose a probabilistic state-space model that can adapt a deployed model subjected to distribution drift. Our model learns the dynamics induced by distribution shifts on the last set of hidden features. Without requiring labels, we infer time-evolving class prototypes that serve as a dynamic classification head. Moreover, our approach is lightweight, modifying only the model's last linear layer. In experiments on real-world distribution shifts and synthetic corruptions, we demonstrate that our approach performs competitively with methods that require back-propagation and access to the model backbone. Our model especially excels in the case of small test batches - the most difficult setting.
Read more7/18/2024
0
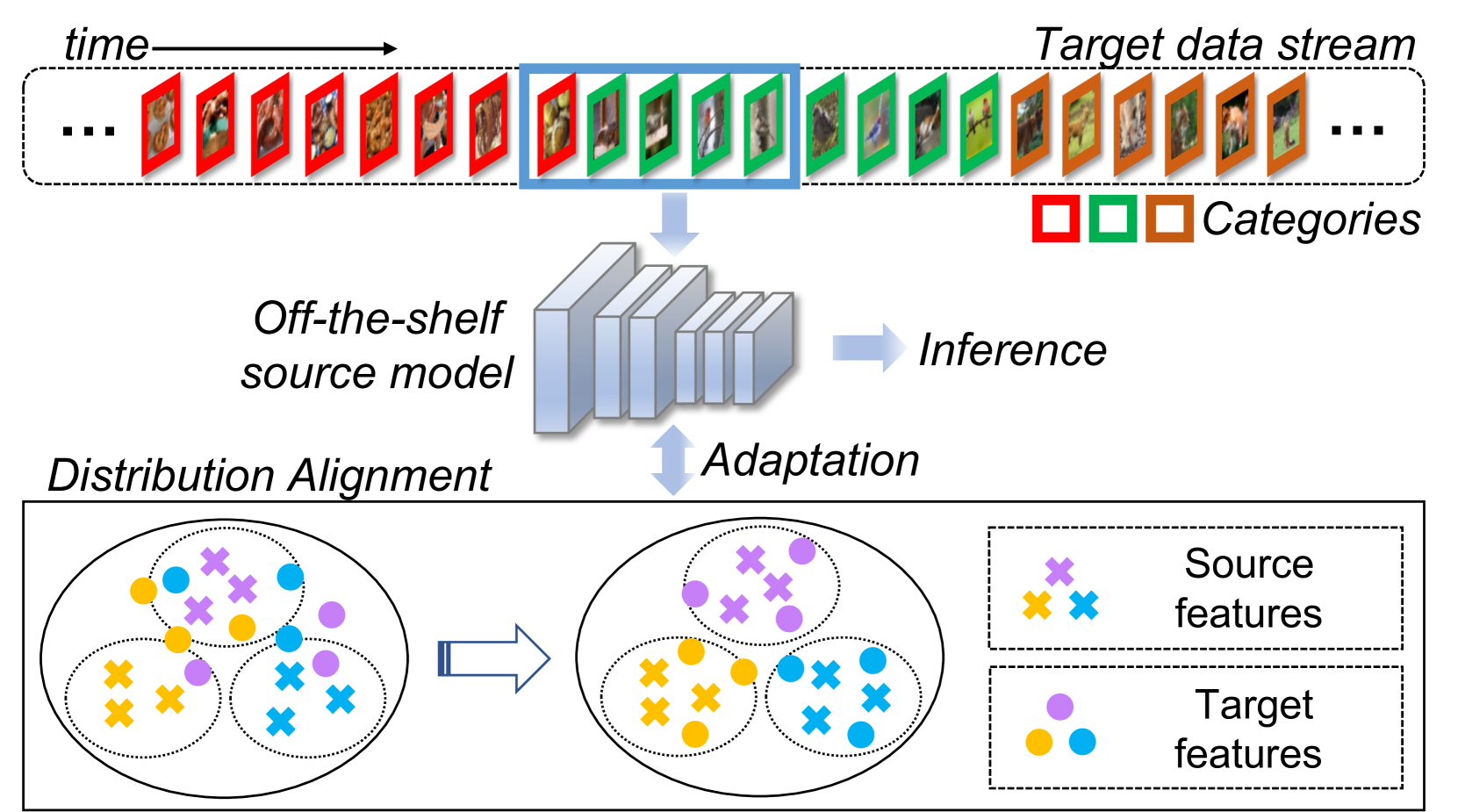
Distribution Alignment for Fully Test-Time Adaptation with Dynamic Online Data Streams
Ziqiang Wang, Zhixiang Chi, Yanan Wu, Li Gu, Zhi Liu, Konstantinos Plataniotis, Yang Wang
Given a model trained on source data, Test-Time Adaptation (TTA) enables adaptation and inference in test data streams with domain shifts from the source. Current methods predominantly optimize the model for each incoming test data batch using self-training loss. While these methods yield commendable results in ideal test data streams, where batches are independently and identically sampled from the target distribution, they falter under more practical test data streams that are not independent and identically distributed (non-i.i.d.). The data batches in a non-i.i.d. stream display prominent label shifts relative to each other. It leads to conflicting optimization objectives among batches during the TTA process. Given the inherent risks of adapting the source model to unpredictable test-time distributions, we reverse the adaptation process and propose a novel Distribution Alignment loss for TTA. This loss guides the distributions of test-time features back towards the source distributions, which ensures compatibility with the well-trained source model and eliminates the pitfalls associated with conflicting optimization objectives. Moreover, we devise a domain shift detection mechanism to extend the success of our proposed TTA method in the continual domain shift scenarios. Our extensive experiments validate the logic and efficacy of our method. On six benchmark datasets, we surpass existing methods in non-i.i.d. scenarios and maintain competitive performance under the ideal i.i.d. assumption.
Read more7/18/2024