Pruning is Optimal for Learning Sparse Features in High-Dimensions
2406.08658
0
0
↗️
Abstract
While it is commonly observed in practice that pruning networks to a certain level of sparsity can improve the quality of the features, a theoretical explanation of this phenomenon remains elusive. In this work, we investigate this by demonstrating that a broad class of statistical models can be optimally learned using pruned neural networks trained with gradient descent, in high-dimensions.
We consider learning both single-index and multi-index models of the form $y = sigma^
Create account to get full access
Overview
- The paper explores the phenomenon of neural network pruning and how it can lead to improved feature quality.
- It investigates a class of statistical models that can be optimally learned using pruned neural networks trained with gradient descent, in high-dimensional settings.
- The paper shows that pruning neural networks proportional to the sparsity level of the relevant model directions can improve the sample complexity compared to unpruned networks.
- It also establishes Correlational Statistical Query (CSQ) lower bounds and demonstrates that gradient descent on pruned networks can achieve the sample complexity suggested by these bounds, while basis-independent methods cannot.
Plain English Explanation
Neural networks are often pruned, or simplified, to a certain level of sparsity (i.e., having many zero-valued connections). This practice is commonly observed to improve the quality of the features learned by the network, but the reasons behind this phenomenon have remained unclear.
This paper investigates a class of statistical models that can be optimally learned using pruned neural networks trained with gradient descent, even in high-dimensional settings. These models take the form of a polynomial function applied to a small number of relevant directions in the input data. The paper shows that if the relevant directions are sparse (i.e., have many zero-valued elements), then pruning the neural network proportional to this sparsity level can improve the sample complexity, or the amount of training data required, compared to using an unpruned network.
Furthermore, the paper establishes a theoretical lower bound, called the Correlational Statistical Query (CSQ) lower bound, which takes the sparsity level of the relevant directions into account. It demonstrates that if the sparsity level exceeds a certain threshold, then training pruned networks with gradient descent can achieve the sample complexity suggested by this lower bound. However, methods that are not sensitive to the network's topology, such as standard gradient descent with random weight initialization, can only achieve suboptimal sample complexity in this scenario.
Technical Explanation
The paper considers learning both single-index and multi-index models of the form y = σ*(V^T x) + ε, where σ* is a degree-p polynomial, and V is a d x r matrix with r << d, containing the relevant model directions. It is assumed that V satisfies an ℓ_q-sparsity condition, meaning that the matrix has a certain level of sparsity.
The key findings are:
-
Pruning neural networks proportional to the sparsity level of
Vimproves their sample complexity compared to unpruned networks. This is demonstrated through a theoretical analysis. -
The paper establishes Correlational Statistical Query (CSQ) lower bounds, which take the sparsity level of
Vinto account. It shows that if the sparsity level ofVexceeds a certain threshold, then training pruned networks with gradient descent can achieve the sample complexity suggested by the CSQ lower bound. -
In the same scenario, basis-independent methods such as standard gradient descent with random weight initialization can only achieve suboptimal sample complexity, as implied by the results.
The intuition behind these findings is that by aligning the network's sparse structure with the sparsity pattern of the relevant model directions, the optimization process can more efficiently learn the underlying statistical model, leading to improved sample complexity.
Critical Analysis
The paper provides a theoretical explanation for the commonly observed phenomenon of neural network pruning improving feature quality. However, it is important to note that the analysis is limited to a specific class of statistical models, and the assumptions, such as the ℓ_q-sparsity condition on the relevant directions, may not always hold in practice.
Additionally, the paper does not address the practical challenges of identifying the relevant model directions and the appropriate level of pruning for a given task. Techniques like value-based pruning may provide more practical guidance in this regard.
Further research is needed to understand how these theoretical insights can be applied to a wider range of models and tasks, and to develop more robust and adaptive pruning strategies that can be applied in real-world scenarios.
Conclusion
This paper offers a theoretical framework for understanding the benefits of neural network pruning, specifically in the context of learning high-dimensional statistical models with sparse relevant directions. The key finding is that aligning the network's sparse structure with the sparsity pattern of the relevant model directions can lead to improved sample complexity, with important implications for the design and optimization of neural networks.
While the analysis is limited to a specific class of models, the insights provide a valuable foundation for further research into the role of network topology and sparsity in deep learning. Ultimately, this work contributes to our understanding of the inner workings of neural networks and may inspire the development of more efficient and robust training algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
NeuroPrune: A Neuro-inspired Topological Sparse Training Algorithm for Large Language Models
Amit Dhurandhar, Tejaswini Pedapati, Ronny Luss, Soham Dan, Aurelie Lozano, Payel Das, Georgios Kollias
0
0
Transformer-based Language Models have become ubiquitous in Natural Language Processing (NLP) due to their impressive performance on various tasks. However, expensive training as well as inference remains a significant impediment to their widespread applicability. While enforcing sparsity at various levels of the model architecture has found promise in addressing scaling and efficiency issues, there remains a disconnect between how sparsity affects network topology. Inspired by brain neuronal networks, we explore sparsity approaches through the lens of network topology. Specifically, we exploit mechanisms seen in biological networks, such as preferential attachment and redundant synapse pruning, and show that principled, model-agnostic sparsity approaches are performant and efficient across diverse NLP tasks, spanning both classification (such as natural language inference) and generation (summarization, machine translation), despite our sole objective not being optimizing performance. NeuroPrune is competitive with (or sometimes superior to) baselines on performance and can be up to $10$x faster in terms of training time for a given level of sparsity, simultaneously exhibiting measurable improvements in inference time in many cases.
6/6/2024
💬
Beyond Size: How Gradients Shape Pruning Decisions in Large Language Models
Rocktim Jyoti Das, Mingjie Sun, Liqun Ma, Zhiqiang Shen
0
0
Large Language Models (LLMs) with billions of parameters are prime targets for network pruning, removing some model weights without hurting performance. Prior approaches such as magnitude pruning, SparseGPT, and Wanda, either concentrated solely on weights or integrated weights with activations for sparsity. However, they overlooked the informative gradients derived from pretrained LLMs. In this paper, we present a novel sparsity-centric pruning method for pretrained LLMs, termed Gradient-based Language Model Pruner (GBLM-Pruner). GBLM-Pruner leverages the first-order term of the Taylor expansion, operating in a training-free manner by harnessing properly normalized gradients from a few calibration samples to determine the pruning metric, and substantially outperforms competitive counterparts like SparseGPT and Wanda in multiple benchmarks. Intriguingly, by incorporating gradients, unstructured pruning with our method tends to reveal some structural patterns, which mirrors the geometric interdependence inherent in the LLMs' parameter structure. Additionally, GBLM-Pruner functions without any subsequent retraining or weight updates to maintain its simplicity as other counterparts. Extensive evaluations on LLaMA-1 and LLaMA-2 across various benchmarks show that GBLM-Pruner surpasses magnitude pruning, Wanda and SparseGPT by significant margins. We further extend our approach on Vision Transformer. Our code and models are available at https://github.com/VILA-Lab/GBLM-Pruner.
4/10/2024

Subspace Node Pruning
Joshua Offergeld, Marcel van Gerven, Nasir Ahmad
0
0
A significant increase in the commercial use of deep neural network models increases the need for efficient AI. Node pruning is the art of removing computational units such as neurons, filters, attention heads, or even entire layers while keeping network performance at a maximum. This can significantly reduce the inference time of a deep network and thus enhance its efficiency. Few of the previous works have exploited the ability to recover performance by reorganizing network parameters while pruning. In this work, we propose to create a subspace from unit activations which enables node pruning while recovering maximum accuracy. We identify that for effective node pruning, a subspace can be created using a triangular transformation matrix, which we show to be equivalent to Gram-Schmidt orthogonalization, which automates this procedure. We further improve this method by reorganizing the network prior to subspace formation. Finally, we leverage the orthogonal subspaces to identify layer-wise pruning ratios appropriate to retain a significant amount of the layer-wise information. We show that this measure outperforms existing pruning methods on VGG networks. We further show that our method can be extended to other network architectures such as residual networks.
5/29/2024
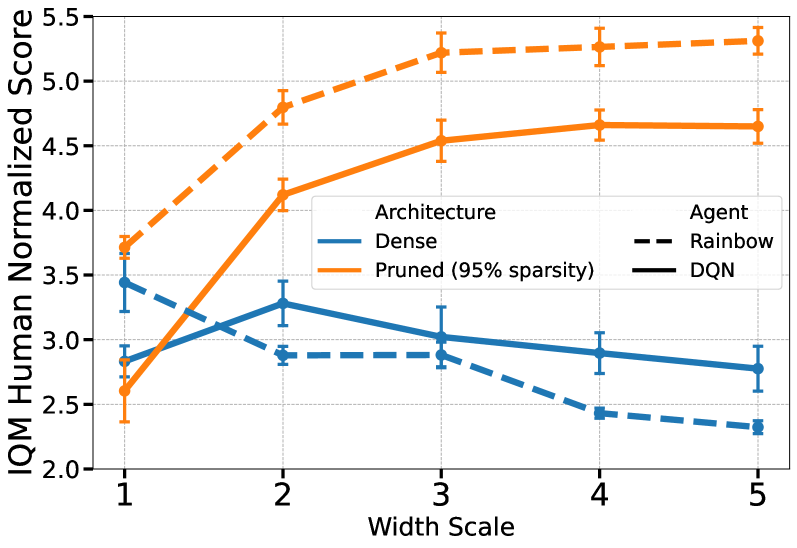
In value-based deep reinforcement learning, a pruned network is a good network
Johan Obando-Ceron, Aaron Courville, Pablo Samuel Castro
0
0
Recent work has shown that deep reinforcement learning agents have difficulty in effectively using their network parameters. We leverage prior insights into the advantages of sparse training techniques and demonstrate that gradual magnitude pruning enables value-based agents to maximize parameter effectiveness. This results in networks that yield dramatic performance improvements over traditional networks, using only a small fraction of the full network parameters.
6/5/2024