In value-based deep reinforcement learning, a pruned network is a good network
2402.12479
0
0
Abstract
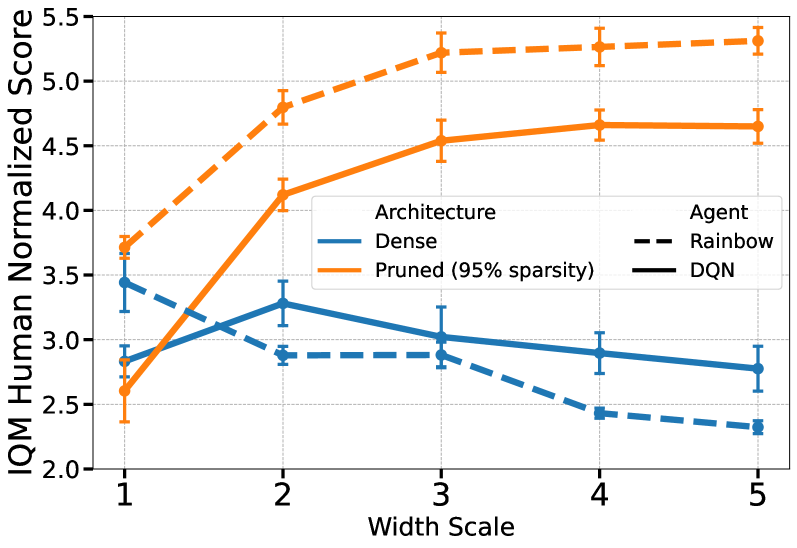
Recent work has shown that deep reinforcement learning agents have difficulty in effectively using their network parameters. We leverage prior insights into the advantages of sparse training techniques and demonstrate that gradual magnitude pruning enables value-based agents to maximize parameter effectiveness. This results in networks that yield dramatic performance improvements over traditional networks, using only a small fraction of the full network parameters.
Create account to get full access
Overview
- This paper explores the surprising finding that in deep reinforcement learning, pruned neural networks can outperform their unpruned counterparts.
- The researchers investigate this phenomenon and offer insights into how and why pruned networks can be more effective for reinforcement learning tasks.
- They also discuss the implications of this discovery for the field of neural network compression and its applications in real-world scenarios.
Plain English Explanation
Typically, when you train a neural network, the goal is to create a complex, highly-detailed model that can perform a task extremely well. However, this paper reveals that for certain reinforcement learning problems, a pruned network - a network that has had some of its connections and neurons removed - can actually outperform the original, full-sized network.
The researchers looked into why this might be the case. They found that pruning can help the network focus on the most important features and connections, making it more efficient and effective for the specific task at hand. This is especially valuable in reinforcement learning, where the agent needs to quickly learn the optimal actions to take in a complex environment.
Additionally, the researchers discovered that subspace node pruning - a technique that selectively removes nodes based on their importance in the network's latent space - can be particularly beneficial for reinforcement learning tasks. This approach helps the network streamline its decision-making process and allocate resources more effectively.
The implications of this work are significant. By leveraging pruned networks, researchers and developers can create more efficient and powerful reinforcement learning systems that are better suited for real-world applications, such as robotics, autonomous vehicles, and game AI. This could lead to more reliable, cost-effective, and energy-efficient solutions in these domains.
Technical Explanation
The paper begins by highlighting the recent advancements in deep reinforcement learning, which have led to impressive results in a wide range of applications. However, the authors note that the large size and complexity of these deep neural networks can be a hindrance, particularly in resource-constrained environments.
To address this issue, the researchers investigate the surprising finding that pruned neural networks can outperform their unpruned counterparts in deep reinforcement learning tasks. They conduct a series of experiments across different environments and network architectures to validate this observation.
One key insight from the paper is the importance of subspace node pruning. This technique selectively removes nodes from the network based on their importance in the latent space, effectively streamlining the decision-making process and improving the network's efficiency. The researchers demonstrate the benefits of this approach in several reinforcement learning scenarios.
Additionally, the paper explores the relationship between network compression and reinforcement learning performance. The authors found that the pruned networks were able to learn more efficiently and achieve higher rewards in the target environments, suggesting that the compression process can actually enhance the network's ability to learn and make optimal decisions.
The researchers also discuss the potential mechanisms underlying this phenomenon. They hypothesize that pruning helps the network focus on the most relevant features and connections, reducing the impact of irrelevant or redundant information and improving the overall decision-making process.
Critical Analysis
While the findings presented in the paper are intriguing and have significant implications for the field of deep reinforcement learning, there are a few potential limitations and areas for further research:
-
Generalization: The experiments were conducted on a limited set of environments and network architectures. It would be valuable to explore the generalizability of the results across a wider range of tasks and model types to ensure the findings are robust and widely applicable.
-
Interpretability: The paper provides insights into the mechanisms behind the performance of pruned networks, but a more in-depth understanding of the underlying reasons for this phenomenon could lead to further advancements in network compression and reinforcement learning optimization.
-
Real-world Deployment: While the theoretical and experimental results are promising, the true test will be the deployment of these techniques in real-world, resource-constrained environments. Factors such as hardware limitations, power consumption, and latency requirements may present additional challenges that need to be addressed.
-
Ethical Considerations: As the field of deep reinforcement learning continues to advance, it is important to consider the potential societal and ethical implications of these techniques, particularly in domains such as autonomous decision-making and human-robot interaction.
Overall, the findings presented in this paper represent a significant step forward in our understanding of the interplay between neural network compression and reinforcement learning performance. By exploring these insights further, researchers and developers can unlock new opportunities for more efficient and effective deep reinforcement learning systems.
Conclusion
This paper challenges the conventional wisdom that larger, more complex neural networks are always superior for deep reinforcement learning tasks. Instead, it demonstrates that pruned networks can outperform their unpruned counterparts, particularly when leveraging techniques like subspace node pruning.
The insights gained from this research have the potential to transform the way we approach neural network design and optimization for reinforcement learning applications. By embracing the power of pruned networks, we can create more efficient, effective, and resource-conscious deep reinforcement learning systems that can thrive in real-world, constrained environments.
As the field continues to evolve, it will be crucial to carefully consider the broader implications of these techniques, ensuring that they are developed and deployed in a responsible and ethical manner. Nevertheless, the findings presented in this paper represent an exciting step forward in our understanding of the complex relationship between neural network structure and reinforcement learning performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
Pruning is Optimal for Learning Sparse Features in High-Dimensions
Nuri Mert Vural, Murat A. Erdogdu
0
0
While it is commonly observed in practice that pruning networks to a certain level of sparsity can improve the quality of the features, a theoretical explanation of this phenomenon remains elusive. In this work, we investigate this by demonstrating that a broad class of statistical models can be optimally learned using pruned neural networks trained with gradient descent, in high-dimensions. We consider learning both single-index and multi-index models of the form $y = sigma^*(boldsymbol{V}^{top} boldsymbol{x}) + epsilon$, where $sigma^*$ is a degree-$p$ polynomial, and $boldsymbol{V} in mathbbm{R}^{d times r}$ with $r ll d$, is the matrix containing relevant model directions. We assume that $boldsymbol{V}$ satisfies a certain $ell_q$-sparsity condition for matrices and show that pruning neural networks proportional to the sparsity level of $boldsymbol{V}$ improves their sample complexity compared to unpruned networks. Furthermore, we establish Correlational Statistical Query (CSQ) lower bounds in this setting, which take the sparsity level of $boldsymbol{V}$ into account. We show that if the sparsity level of $boldsymbol{V}$ exceeds a certain threshold, training pruned networks with a gradient descent algorithm achieves the sample complexity suggested by the CSQ lower bound. In the same scenario, however, our results imply that basis-independent methods such as models trained via standard gradient descent initialized with rotationally invariant random weights can provably achieve only suboptimal sample complexity.
6/14/2024
🧠
Neural Network Compression for Reinforcement Learning Tasks
Dmitry A. Ivanov, Denis A. Larionov, Oleg V. Maslennikov, Vladimir V. Voevodin
0
0
In real applications of Reinforcement Learning (RL), such as robotics, low latency and energy efficient inference is very desired. The use of sparsity and pruning for optimizing Neural Network inference, and particularly to improve energy and latency efficiency, is a standard technique. In this work, we perform a systematic investigation of applying these optimization techniques for different RL algorithms in different RL environments, yielding up to a 400-fold reduction in the size of neural networks.
5/14/2024
🛠️
Rethinking Pruning for Backdoor Mitigation: An Optimization Perspective
Nan Li, Haiyang Yu, Ping Yi
0
0
Deep Neural Networks (DNNs) are known to be vulnerable to backdoor attacks, posing concerning threats to their reliable deployment. Recent research reveals that backdoors can be erased from infected DNNs by pruning a specific group of neurons, while how to effectively identify and remove these backdoor-associated neurons remains an open challenge. Most of the existing defense methods rely on defined rules and focus on neuron's local properties, ignoring the exploration and optimization of pruning policies. To address this gap, we propose an Optimized Neuron Pruning (ONP) method combined with Graph Neural Network (GNN) and Reinforcement Learning (RL) to repair backdoor models. Specifically, ONP first models the target DNN as graphs based on neuron connectivity, and then uses GNN-based RL agents to learn graph embeddings and find a suitable pruning policy. To the best of our knowledge, this is the first attempt to employ GNN and RL for optimizing pruning policies in the field of backdoor defense. Experiments show, with a small amount of clean data, ONP can effectively prune the backdoor neurons implanted by a set of backdoor attacks at the cost of negligible performance degradation, achieving a new state-of-the-art performance for backdoor mitigation.
5/29/2024

Subspace Node Pruning
Joshua Offergeld, Marcel van Gerven, Nasir Ahmad
0
0
A significant increase in the commercial use of deep neural network models increases the need for efficient AI. Node pruning is the art of removing computational units such as neurons, filters, attention heads, or even entire layers while keeping network performance at a maximum. This can significantly reduce the inference time of a deep network and thus enhance its efficiency. Few of the previous works have exploited the ability to recover performance by reorganizing network parameters while pruning. In this work, we propose to create a subspace from unit activations which enables node pruning while recovering maximum accuracy. We identify that for effective node pruning, a subspace can be created using a triangular transformation matrix, which we show to be equivalent to Gram-Schmidt orthogonalization, which automates this procedure. We further improve this method by reorganizing the network prior to subspace formation. Finally, we leverage the orthogonal subspaces to identify layer-wise pruning ratios appropriate to retain a significant amount of the layer-wise information. We show that this measure outperforms existing pruning methods on VGG networks. We further show that our method can be extended to other network architectures such as residual networks.
5/29/2024