PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference

0
🤯
Sign in to get full access
Overview
- Large language models (LLMs) have impressive comprehension abilities but struggle with GPU memory usage during inference, limiting their use in real-time applications.
- Existing methods try to compress the pre-computed key-value (KV) cache to reduce memory, but they overlook the inter-layer dependencies and high memory consumption during pre-computation.
- The paper introduces PyramidInfer, a method that compresses the KV cache by retaining only the crucial context layer-wise, improving throughput by 2.2x and reducing GPU memory by over 54% compared to previous approaches.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, these models require a lot of computer memory to run, which can limit their use in real-time applications like chatbots.
One way to speed up these models is to pre-compute and store certain information, called a key-value (KV) cache, in the computer's memory. This can help the model run faster, but the KV cache can also take up a lot of space.
Previous methods have tried to compress the KV cache to save memory, but they haven't considered how the different layers of the model interact with each other. They also didn't think about how much memory is used when pre-computing the KV cache in the first place.
The researchers in this paper found that the number of important keys and values that influence the model's future decisions decreases as you go from one layer to the next. They developed a new method called PyramidInfer that takes advantage of this by only storing the crucial information in the KV cache.
This approach saves a lot of memory without sacrificing the model's performance. In fact, PyramidInfer can run 2.2 times faster and use over 54% less GPU memory compared to previous methods.
Technical Explanation
The paper proposes PyramidInfer, a method to accelerate large language model (LLM) inference by efficiently compressing the key-value (KV) cache.
Existing KV cache compression techniques, such as Accelerate, SqueezeAttention, and KV-1bit, focus on pruning the pre-computed KV cache to reduce memory consumption. However, they overlook the inter-layer dependencies and the high memory usage during the pre-computation phase.
The key insight of PyramidInfer is that the number of crucial keys and values that influence future generations decreases layer by layer. The researchers leverage this observation and propose a layer-wise KV cache compression approach. Specifically, PyramidInfer extracts the crucial context by analyzing the consistency in attention weights across layers.
The experimental results show that PyramidInfer achieves a 2.2x throughput improvement compared to Accelerate, while reducing the GPU memory consumption of the KV cache by over 54%. This significant memory savings is enabled by computing fewer keys and values without compromising performance.
Critical Analysis
The paper presents a promising approach to improve the efficiency of large language model inference, but there are a few potential limitations and areas for further research:
-
The evaluation is limited to a single model (GPT-2) and dataset (WikiText-103). It would be valuable to assess the performance of PyramidInfer on a broader range of LLMs and tasks to understand its generalizability.
-
The paper does not provide a detailed analysis of the computational overhead introduced by the layer-wise KV cache extraction and compression. Understanding the end-to-end latency and throughput impact would be important for real-world deployment.
-
The proposed method relies on the assumption that the importance of keys and values decreases layer by layer. While the paper provides empirical evidence, it would be helpful to have a more rigorous theoretical justification for this phenomenon.
-
The authors mention the potential for further memory savings by selectively caching the KV pairs based on their importance, as explored in SnapKV. Combining PyramidInfer with such adaptive caching strategies could lead to even greater efficiency improvements.
Overall, the paper makes a valuable contribution by addressing the critical challenge of GPU memory usage in large language model inference. The proposed PyramidInfer method demonstrates promising results and opens up avenues for further research in this important area.
Conclusion
The paper introduces PyramidInfer, a novel method to improve the efficiency of large language model inference by compressing the key-value (KV) cache in a layer-wise manner. By leveraging the observation that the number of crucial keys and values decreases across layers, PyramidInfer can significantly reduce GPU memory consumption without sacrificing model performance.
The experimental results show that PyramidInfer achieves a 2.2x throughput improvement and over 54% GPU memory reduction compared to existing KV cache compression techniques. This advance in efficiency could enable the wider deployment of large language models in real-time applications, such as interactive chatbots and virtual assistants, where memory and latency constraints are critical.
The paper also highlights potential areas for further research, including evaluating PyramidInfer on a broader range of models and tasks, analyzing the computational overhead, and exploring synergies with other adaptive caching strategies. By addressing these challenges, the research community can continue to push the boundaries of large language model efficiency and unlock new applications for these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
Dongjie Yang, XiaoDong Han, Yan Gao, Yao Hu, Shilin Zhang, Hai Zhao
Large Language Models (LLMs) have shown remarkable comprehension abilities but face challenges in GPU memory usage during inference, hindering their scalability for real-time applications like chatbots. To accelerate inference, we store computed keys and values (KV cache) in the GPU memory. Existing methods study the KV cache compression to reduce memory by pruning the pre-computed KV cache. However, they neglect the inter-layer dependency between layers and huge memory consumption in pre-computation. To explore these deficiencies, we find that the number of crucial keys and values that influence future generations decreases layer by layer and we can extract them by the consistency in attention weights. Based on the findings, we propose PyramidInfer, a method that compresses the KV cache by layer-wise retaining crucial context. PyramidInfer saves significant memory by computing fewer keys and values without sacrificing performance. Experimental results show PyramidInfer improves 2.2x throughput compared to Accelerate with over 54% GPU memory reduction in KV cache.
Read more6/6/2024
0
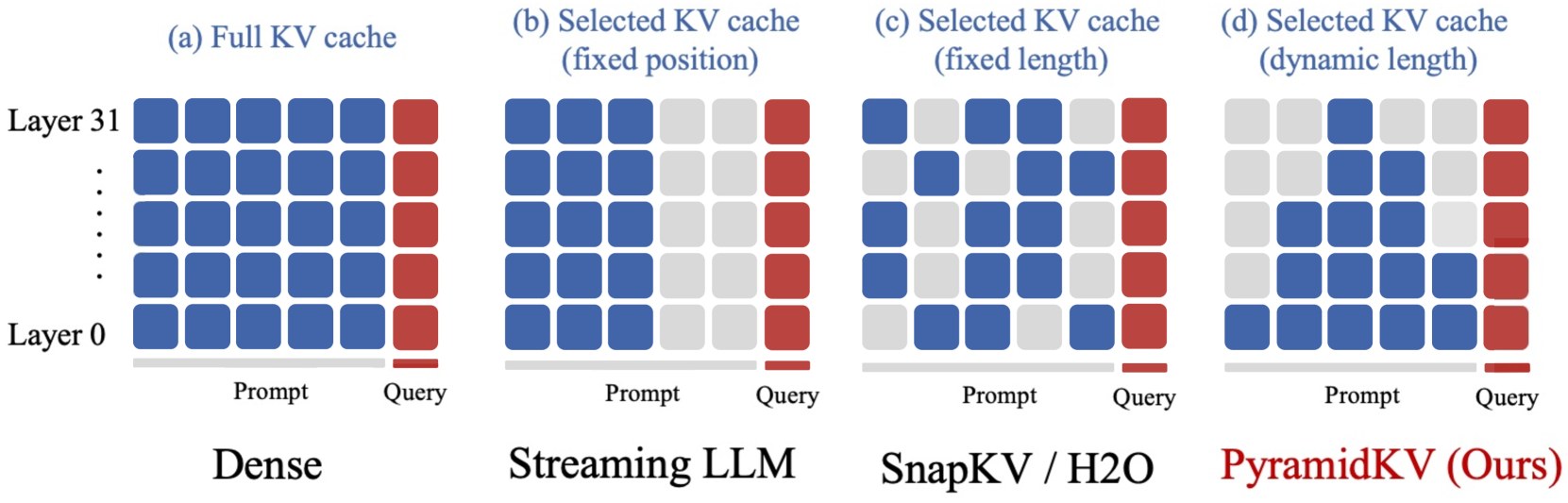
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai., Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, Wen Xiao
In this study, we investigate whether attention-based information flow inside large language models (LLMs) is aggregated through noticeable patterns for long context processing. Our observations reveal that LLMs aggregate information through Pyramidal Information Funneling where attention is scattering widely in lower layers, progressively consolidating within specific contexts, and ultimately focusin on critical tokens (a.k.a massive activation or attention sink) in higher layers. Motivated by these insights, we developed PyramidKV, a novel and effective KV cache compression method. This approach dynamically adjusts the KV cache size across different layers, allocating more cache in lower layers and less in higher ones, diverging from traditional methods that maintain a uniform KV cache size. Our experimental evaluations, utilizing the LongBench benchmark, show that PyramidKV matches the performance of models with a full KV cache while retaining only 12% of the KV cache, thus significantly reducing memory usage. In scenarios emphasizing memory efficiency, where only 0.7% of the KV cache is maintained, PyramidKV surpasses other KV cache compression techniques achieving up to a 20.5 absolute accuracy improvement on TREC.
Read more6/18/2024
88
Layer-Condensed KV Cache for Efficient Inference of Large Language Models
Haoyi Wu, Kewei Tu
Huge memory consumption has been a major bottleneck for deploying high-throughput large language models in real-world applications. In addition to the large number of parameters, the key-value (KV) cache for the attention mechanism in the transformer architecture consumes a significant amount of memory, especially when the number of layers is large for deep language models. In this paper, we propose a novel method that only computes and caches the KVs of a small number of layers, thus significantly saving memory consumption and improving inference throughput. Our experiments on large language models show that our method achieves up to 26$times$ higher throughput than standard transformers and competitive performance in language modeling and downstream tasks. In addition, our method is orthogonal to existing transformer memory-saving techniques, so it is straightforward to integrate them with our model, achieving further improvement in inference efficiency. Our code is available at https://github.com/whyNLP/LCKV.
Read more6/5/2024
💬
0
MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
Akide Liu, Jing Liu, Zizheng Pan, Yefei He, Gholamreza Haffari, Bohan Zhuang
A critical approach for efficiently deploying computationally demanding large language models (LLMs) is Key-Value (KV) caching. The KV cache stores key-value states of previously generated tokens, significantly reducing the need for repetitive computations and thereby lowering latency in autoregressive generation. However, the size of the KV cache grows linearly with sequence length, posing challenges for applications requiring long context input and extensive sequence generation. In this paper, we present a simple yet effective approach, called MiniCache, to compress the KV cache across layers from a novel depth perspective, significantly reducing the memory footprint for LLM inference. Our approach is based on the observation that KV cache states exhibit high similarity between the adjacent layers in the middle-to-deep portion of LLMs. To facilitate merging, we propose disentangling the states into the magnitude and direction components, interpolating the directions of the state vectors while preserving their lengths unchanged. Furthermore, we introduce a token retention strategy to keep highly distinct state pairs unmerged, thus preserving the information with minimal additional storage overhead. Our MiniCache is training-free and general, complementing existing KV cache compression strategies, such as quantization and sparsity. We conduct a comprehensive evaluation of MiniCache utilizing various models including LLaMA-2, LLaMA-3, Phi-3, Mistral, and Mixtral across multiple benchmarks, demonstrating its exceptional performance in achieving superior compression ratios and high throughput. On the ShareGPT dataset, LLaMA-2-7B with 4-bit MiniCache achieves a remarkable compression ratio of up to 5.02x, enhances inference throughput by approximately 5x, and reduces the memory footprint by 41% compared to the FP16 full cache baseline, all while maintaining near-lossless performance.
Read more9/10/2024