Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM
2404.19128
0
0
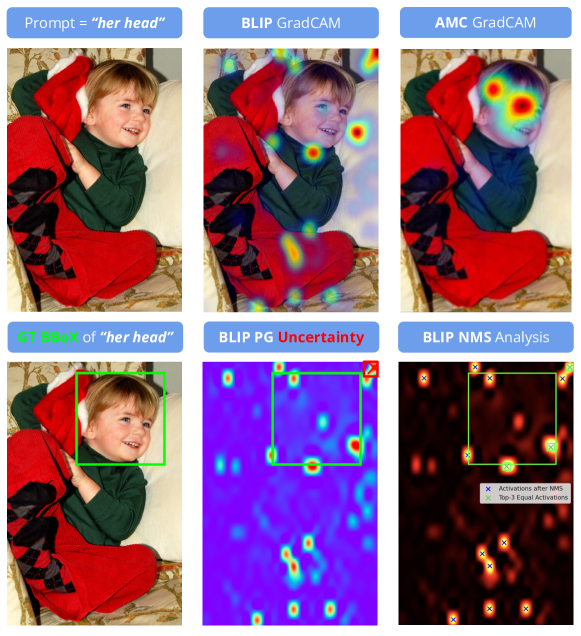
Abstract
Vision and Language Models (VLMs) continue to demonstrate remarkable zero-shot (ZS) performance across various tasks. However, many probing studies have revealed that even the best-performing VLMs struggle to capture aspects of compositional scene understanding, lacking the ability to properly ground and localize linguistic phrases in images. Recent VLM advancements include scaling up both model and dataset sizes, additional training objectives and levels of supervision, and variations in the model architectures. To characterize the grounding ability of VLMs, such as phrase grounding, referring expressions comprehension, and relationship understanding, Pointing Game has been used as an evaluation metric for datasets with bounding box annotations. In this paper, we introduce a novel suite of quantitative metrics that utilize GradCAM activations to rigorously evaluate the grounding capabilities of pre-trained VLMs like CLIP, BLIP, and ALBEF. These metrics offer an explainable and quantifiable approach for a more detailed comparison of the zero-shot capabilities of VLMs and enable measuring models' grounding uncertainty. This characterization reveals interesting tradeoffs between the size of the model, the dataset size, and their performance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces Q-GroundCAM, a method for quantifying the grounding of vision-language models using Gradient-weighted Class Activation Mapping (GradCAM).
- Q-GroundCAM aims to provide a systematic way to measure how well a model grounds its language output in the corresponding visual input.
- The method is evaluated on various vision-language tasks, including image captioning, visual question answering, and visual reasoning.
Plain English Explanation
Q-GroundCAM is a new technique that helps understand how well vision-language models, such as those used for image captioning or visual question answering, connect their language outputs to the visual inputs they are processing. These models are often "black boxes" where it's difficult to see how they are making their decisions.
The key idea behind Q-GroundCAM is to use a technique called GradCAM, which can highlight the regions of an image that are most important for a model's output. By applying GradCAM to vision-language models, the researchers can quantify how well the model's language output is grounded in the corresponding visual input. This provides a way to assess the model's performance and interpretability.
The paper evaluates Q-GroundCAM on several different vision-language tasks, showing that it can provide useful insights into model behavior. For example, it can help identify cases where a model is generating language outputs that are not well-aligned with the visual input, which could indicate problems with the model's training or architecture.
Overall, Q-GroundCAM represents a valuable tool for researchers and developers working on vision-language models, as it can help them better understand how these models are making decisions and identify areas for improvement. It builds on related work on grounding large language models and visual grounding of language, and could be used in combination with other techniques like GPT-4V-AD or zero-shot medical phrase grounding to further enhance the grounding and interpretability of vision-language models.
Technical Explanation
The paper introduces Q-GroundCAM, a method for quantifying the grounding of vision-language models using Gradient-weighted Class Activation Mapping (GradCAM). GradCAM is a technique that can identify the regions of an image that are most important for a model's output, by analyzing the gradients of the model's activations.
The key idea behind Q-GroundCAM is to apply GradCAM to the language outputs of vision-language models, in order to measure how well those language outputs are grounded in the corresponding visual inputs. The authors propose several metrics to quantify this grounding, such as the "Grounding Score" and the "Grounding Coherence".
The paper evaluates Q-GroundCAM on a range of vision-language tasks, including image captioning, visual question answering, and visual reasoning. The results show that Q-GroundCAM can provide valuable insights into the behavior of these models, and can help identify cases where the language outputs are not well-aligned with the visual inputs.
For example, the authors demonstrate how Q-GroundCAM can be used to identify "language hallucination" in image captioning models, where the model generates language outputs that are not grounded in the visual input. They also show how Q-GroundCAM can be used to assess the grounding of visual reasoning models, and to identify cases where the model is relying too heavily on language-based reasoning rather than visual grounding.
Overall, the Q-GroundCAM method represents a significant advance in the field of vision-language research, as it provides a systematic way to measure and understand the grounding of these models. It builds on related work on grounding large language models and visual grounding of language, and could be used in combination with other techniques like GPT-4V-AD or zero-shot medical phrase grounding to further enhance the grounding and interpretability of vision-language models.
Critical Analysis
The Q-GroundCAM method presented in the paper represents an important step forward in understanding the grounding of vision-language models. By providing a systematic way to measure and quantify the alignment between a model's language outputs and its visual inputs, the method offers valuable insights that can inform model development and evaluation.
That said, the paper does acknowledge some limitations and areas for further research. For example, the authors note that Q-GroundCAM may not be able to capture more complex or abstract forms of grounding that go beyond simple visual-linguistic associations. There is also a need to further validate the method's effectiveness across a broader range of vision-language tasks and model architectures.
Additionally, while the paper demonstrates the utility of Q-GroundCAM, it does not directly address the question of how to improve the grounding of vision-language models. Further research may be needed to understand the specific architectural and training factors that contribute to well-grounded language outputs, and to develop techniques for enhancing the grounding capabilities of these models.
Overall, the Q-GroundCAM method represents an important contribution to the field of vision-language research, and the paper provides a solid foundation for future work in this area. As the development of advanced vision-language models continues, tools like Q-GroundCAM will become increasingly valuable for ensuring the robustness, interpretability, and real-world applicability of these systems.
Conclusion
The Q-GroundCAM method introduced in this paper provides a valuable new tool for quantifying the grounding of vision-language models. By applying GradCAM to the language outputs of these models, the method can measure how well the language is aligned with the corresponding visual inputs, offering insights into the model's reasoning and performance.
The paper's evaluation of Q-GroundCAM across various vision-language tasks demonstrates the method's versatility and usefulness. It shows how Q-GroundCAM can help identify issues like language hallucination, and can provide a more nuanced understanding of a model's reliance on visual versus language-based reasoning.
While the method has some limitations, and further research is needed to fully understand its capabilities and applications, Q-GroundCAM represents an important step forward in the quest to build more robust, interpretable, and grounded vision-language models. As the field continues to evolve, tools like Q-GroundCAM will become increasingly valuable for researchers and developers working to advance the state of the art in this rapidly progressing area of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
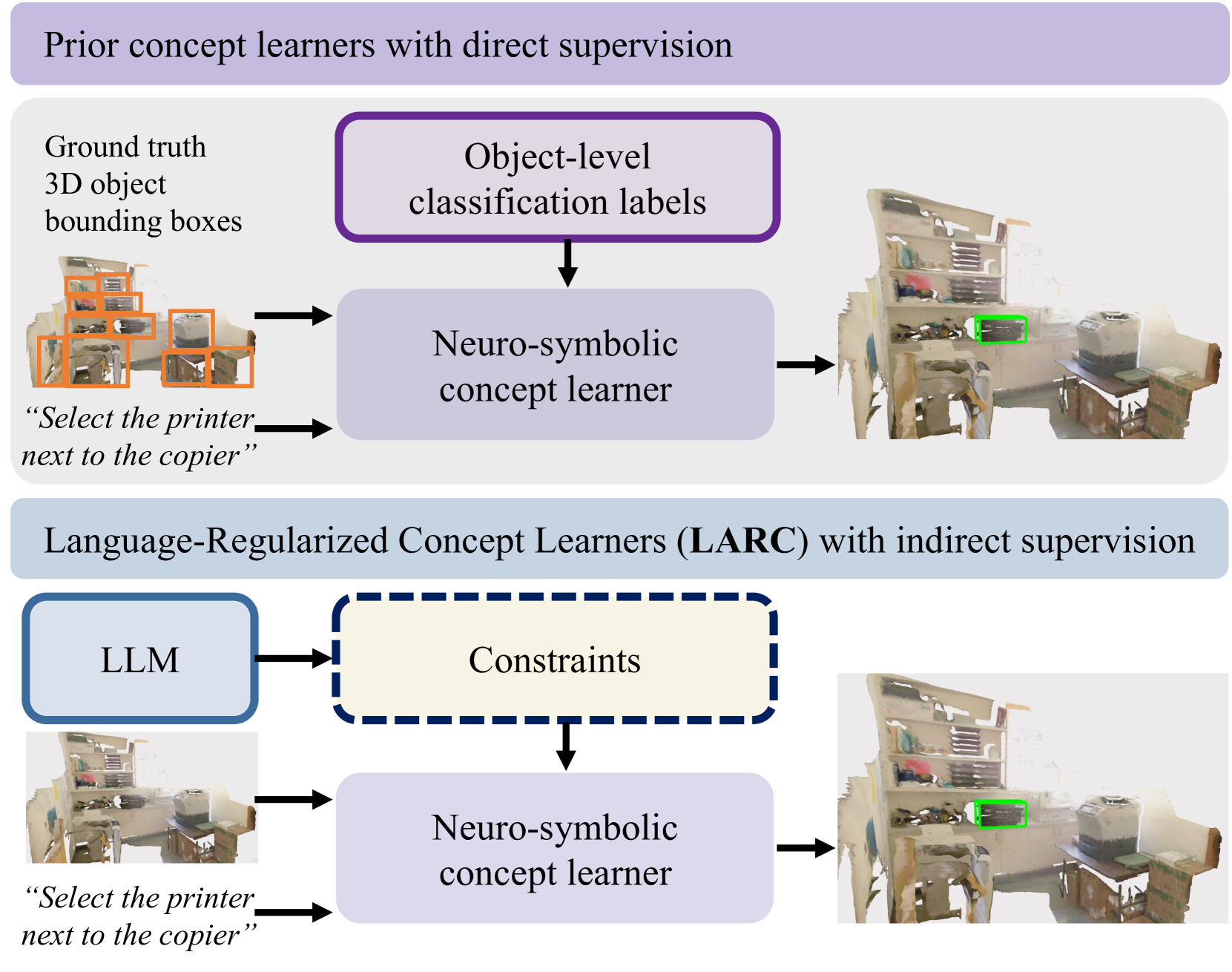
Naturally Supervised 3D Visual Grounding with Language-Regularized Concept Learners
Chun Feng, Joy Hsu, Weiyu Liu, Jiajun Wu
0
0
3D visual grounding is a challenging task that often requires direct and dense supervision, notably the semantic label for each object in the scene. In this paper, we instead study the naturally supervised setting that learns from only 3D scene and QA pairs, where prior works underperform. We propose the Language-Regularized Concept Learner (LARC), which uses constraints from language as regularization to significantly improve the accuracy of neuro-symbolic concept learners in the naturally supervised setting. Our approach is based on two core insights: the first is that language constraints (e.g., a word's relation to another) can serve as effective regularization for structured representations in neuro-symbolic models; the second is that we can query large language models to distill such constraints from language properties. We show that LARC improves performance of prior works in naturally supervised 3D visual grounding, and demonstrates a wide range of 3D visual reasoning capabilities-from zero-shot composition, to data efficiency and transferability. Our method represents a promising step towards regularizing structured visual reasoning frameworks with language-based priors, for learning in settings without dense supervision.
5/1/2024
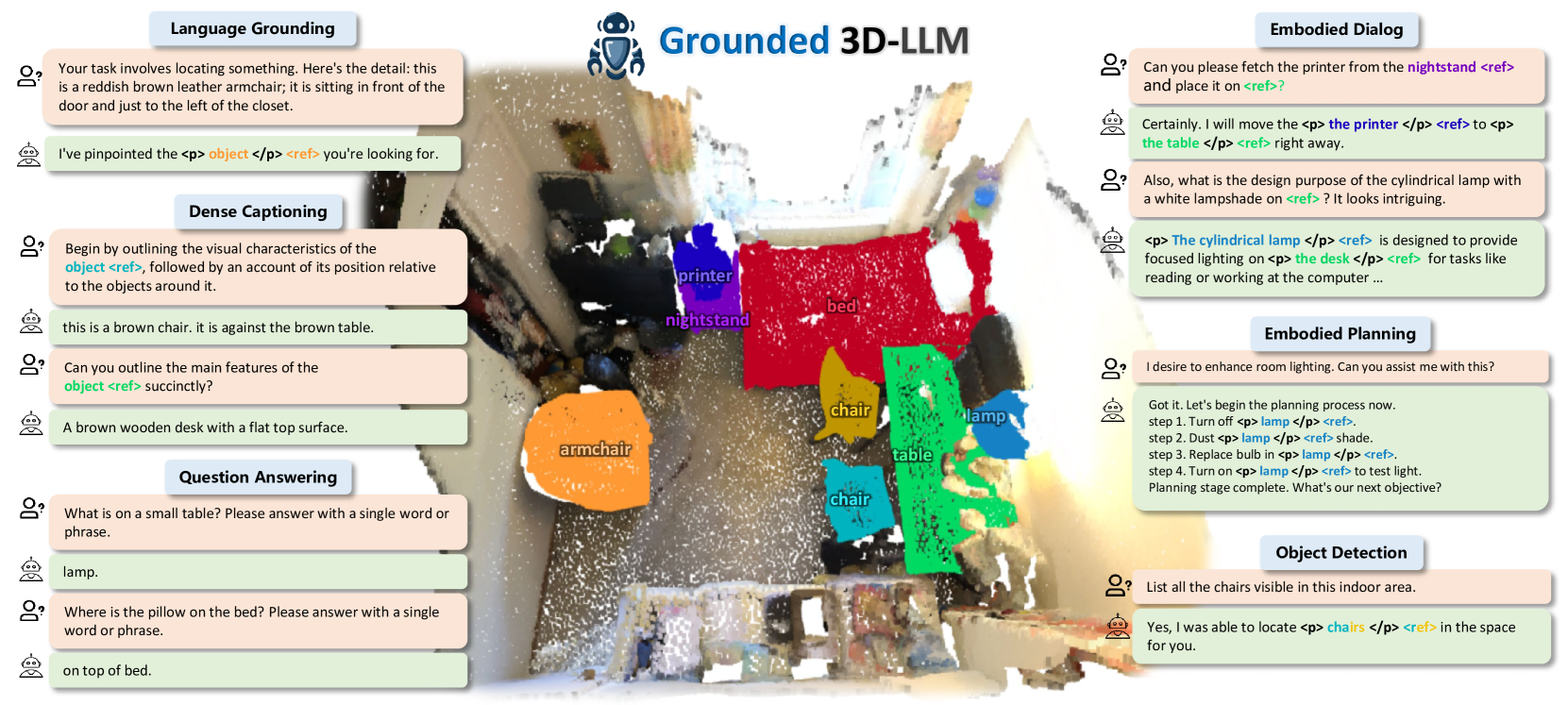
New!Grounded 3D-LLM with Referent Tokens
Yilun Chen, Shuai Yang, Haifeng Huang, Tai Wang, Ruiyuan Lyu, Runsen Xu, Dahua Lin, Jiangmiao Pang
0
0
Prior studies on 3D scene understanding have primarily developed specialized models for specific tasks or required task-specific fine-tuning. In this study, we propose Grounded 3D-LLM, which explores the potential of 3D large multi-modal models (3D LMMs) to consolidate various 3D vision tasks within a unified generative framework. The model uses scene referent tokens as special noun phrases to reference 3D scenes, enabling the handling of sequences that interleave 3D and textual data. It offers a natural approach for translating 3D vision tasks into language formats using task-specific instruction templates. To facilitate the use of referent tokens in subsequent language modeling, we have curated large-scale grounded language datasets that offer finer scene-text correspondence at the phrase level by bootstrapping existing object labels. Subsequently, we introduced Contrastive LAnguage-Scene Pre-training (CLASP) to effectively leverage this data, thereby integrating 3D vision with language models. Our comprehensive evaluation covers open-ended tasks like dense captioning and 3D QA, alongside close-ended tasks such as object detection and language grounding. Experiments across multiple 3D benchmarks reveal the leading performance and the broad applicability of Grounded 3D-LLM. Code and datasets will be released on the project page: https://groundedscenellm.github.io/grounded_3d-llm.github.io.
5/20/2024
💬
GROUNDHOG: Grounding Large Language Models to Holistic Segmentation
Yichi Zhang, Ziqiao Ma, Xiaofeng Gao, Suhaila Shakiah, Qiaozi Gao, Joyce Chai
0
0
Most multimodal large language models (MLLMs) learn language-to-object grounding through causal language modeling where grounded objects are captured by bounding boxes as sequences of location tokens. This paradigm lacks pixel-level representations that are important for fine-grained visual understanding and diagnosis. In this work, we introduce GROUNDHOG, an MLLM developed by grounding Large Language Models to holistic segmentation. GROUNDHOG incorporates a masked feature extractor and converts extracted features into visual entity tokens for the MLLM backbone, which then connects groundable phrases to unified grounding masks by retrieving and merging the entity masks. To train GROUNDHOG, we carefully curated M3G2, a grounded visual instruction tuning dataset with Multi-Modal Multi-Grained Grounding, by harvesting a collection of segmentation-grounded datasets with rich annotations. Our experimental results show that GROUNDHOG achieves superior performance on various language grounding tasks without task-specific fine-tuning, and significantly reduces object hallucination. GROUNDHOG also demonstrates better grounding towards complex forms of visual input and provides easy-to-understand diagnosis in failure cases.
4/17/2024
❗
GPT-4V-AD: Exploring Grounding Potential of VQA-oriented GPT-4V for Zero-shot Anomaly Detection
Jiangning Zhang, Haoyang He, Xuhai Chen, Zhucun Xue, Yabiao Wang, Chengjie Wang, Lei Xie, Yong Liu
0
0
Large Multimodal Model (LMM) GPT-4V(ision) endows GPT-4 with visual grounding capabilities, making it possible to handle certain tasks through the Visual Question Answering (VQA) paradigm. This paper explores the potential of VQA-oriented GPT-4V in the recently popular visual Anomaly Detection (AD) and is the first to conduct qualitative and quantitative evaluations on the popular MVTec AD and VisA datasets. Considering that this task requires both image-/pixel-level evaluations, the proposed GPT-4V-AD framework contains three components: textbf{textit{1)}} Granular Region Division, textbf{textit{2)}} Prompt Designing, textbf{textit{3)}} Text2Segmentation for easy quantitative evaluation, and have made some different attempts for comparative analysis. The results show that GPT-4V can achieve certain results in the zero-shot AD task through a VQA paradigm, such as achieving image-level 77.1/88.0 and pixel-level 68.0/76.6 AU-ROCs on MVTec AD and VisA datasets, respectively. However, its performance still has a certain gap compared to the state-of-the-art zero-shot method, eg, WinCLIP and CLIP-AD, and further researches are needed. This study provides a baseline reference for the research of VQA-oriented LMM in the zero-shot AD task, and we also post several possible future works. Code is available at url{https://github.com/zhangzjn/GPT-4V-AD}.
4/17/2024