Zero-Shot Medical Phrase Grounding with Off-the-shelf Diffusion Models
2404.12920
0
0
Abstract
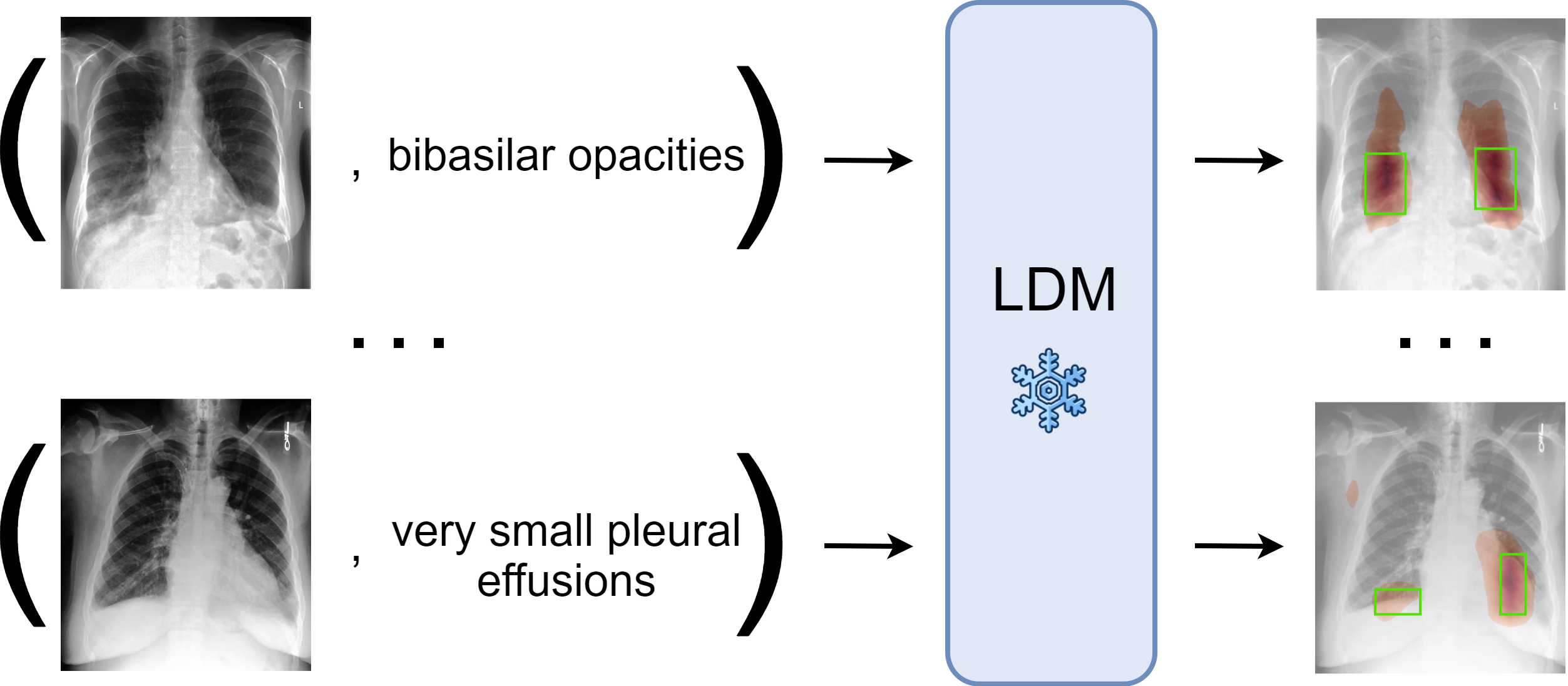
Localizing the exact pathological regions in a given medical scan is an important imaging problem that requires a large amount of bounding box ground truth annotations to be accurately solved. However, there exist alternative, potentially weaker, forms of supervision, such as accompanying free-text reports, which are readily available. The task of performing localization with textual guidance is commonly referred to as phrase grounding. In this work, we use a publicly available Foundation Model, namely the Latent Diffusion Model, to solve this challenging task. This choice is supported by the fact that the Latent Diffusion Model, despite being generative in nature, contains mechanisms (cross-attention) that implicitly align visual and textual features, thus leading to intermediate representations that are suitable for the task at hand. In addition, we aim to perform this task in a zero-shot manner, i.e., without any further training on target data, meaning that the model's weights remain frozen. To this end, we devise strategies to select features and also refine them via post-processing without extra learnable parameters. We compare our proposed method with state-of-the-art approaches which explicitly enforce image-text alignment in a joint embedding space via contrastive learning. Results on a popular chest X-ray benchmark indicate that our method is competitive wih SOTA on different types of pathology, and even outperforms them on average in terms of two metrics (mean IoU and AUC-ROC). Source code will be released upon acceptance.
Create account to get full access
Overview
- This paper explores the use of off-the-shelf diffusion models for zero-shot medical phrase grounding - the ability to ground medical phrases to their corresponding visual concepts without any task-specific training.
- The researchers leverage the impressive generative capabilities of diffusion models to perform this task, which can have important applications in medical image understanding and retrieval.
- The paper presents a simple yet effective approach that demonstrates the potential of diffusion models for this problem, offering insights and opening up new research directions.
Plain English Explanation
The paper discusses a technique called "zero-shot medical phrase grounding" using off-the-shelf diffusion models. Diffusion models are a type of AI system that can generate highly realistic images. The researchers show how these models can be used to match medical phrases (like "fractured femur") to the corresponding visual concepts, without any specialized training for this task.
This is a valuable ability because it can help with tasks like medical image understanding and retrieval. For example, if a doctor types in "fractured femur," the system could automatically find and display relevant medical images. The paper presents a simple but effective approach to this problem, demonstrating the potential of diffusion models beyond just image generation.
Technical Explanation
The paper proposes a zero-shot approach to medical phrase grounding using off-the-shelf diffusion models. Given a medical phrase, the method generates an image representation using the diffusion model, and then compares this to visual representations of medical concepts to find the best match.
Specifically, the researchers use a pre-trained diffusion model to generate an image from the text prompt, and then employ CLIP, a multi-modal AI system, to encode both the generated image and a set of target visual concepts. The cosine similarity between the image and concept embeddings is used to find the closest match, effectively grounding the input phrase to the corresponding visual representation.
The paper evaluates this approach on a medical image dataset, FreeSeg, and demonstrates promising results, outperforming several baselines. This suggests that off-the-shelf diffusion models can be effectively leveraged for zero-shot medical phrase grounding, opening up new possibilities for medical image understanding and retrieval.
Critical Analysis
The paper presents a compelling proof-of-concept for using diffusion models in a zero-shot medical phrase grounding task. However, the authors acknowledge that the approach has several limitations:
-
The performance, while promising, is still not at the level required for practical deployment in real-world medical settings. Further research and refinements would be needed to improve the accuracy and robustness of the method.
-
The paper only evaluates the approach on a single dataset, FreeSeg, which may not be representative of the full diversity of medical images and phrases encountered in clinical practice. More extensive testing on a wider range of datasets would be valuable.
-
The approach relies on the availability of pre-trained diffusion and CLIP models, which may not always be accessible or optimized for medical applications. Exploring ways to fine-tune or adapt these models to the medical domain could be an important area for future research.
Overall, the paper demonstrates an interesting and promising direction, but further work is needed to fully realize the potential of this approach for real-world medical image understanding and retrieval tasks.
Conclusion
This paper explores the use of off-the-shelf diffusion models for the task of zero-shot medical phrase grounding, which involves matching medical phrases to their corresponding visual concepts without any task-specific training. The researchers present a simple yet effective approach that leverages the impressive generative capabilities of diffusion models, coupled with a multi-modal encoding system, to perform this task.
The results are promising, suggesting that diffusion models can be a valuable tool for medical image understanding and retrieval. While the current performance is not yet at the level required for practical deployment, the paper opens up new research directions and demonstrates the potential of this approach. Further refinements, dataset expansions, and model adaptations could lead to significant improvements and meaningful real-world applications in the medical domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Data Alignment for Zero-Shot Concept Generation in Dermatology AI
Soham Gadgil, Mahtab Bigverdi
0
0
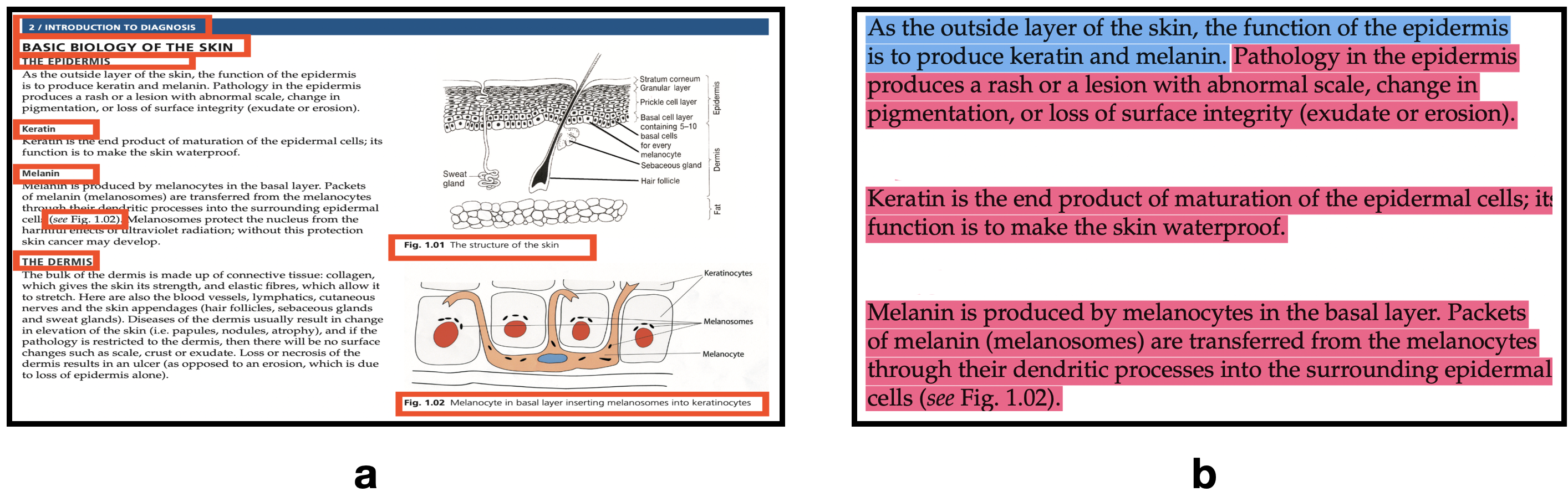
AI in dermatology is evolving at a rapid pace but the major limitation to training trustworthy classifiers is the scarcity of data with ground-truth concept level labels, which are meta-labels semantically meaningful to humans. Foundation models like CLIP providing zero-shot capabilities can help alleviate this challenge by leveraging vast amounts of image-caption pairs available on the internet. CLIP can be fine-tuned using domain specific image-caption pairs to improve classification performance. However, CLIP's pre-training data is not well-aligned with the medical jargon that clinicians use to perform diagnoses. The development of large language models (LLMs) in recent years has led to the possibility of leveraging the expressive nature of these models to generate rich text. Our goal is to use these models to generate caption text that aligns well with both the clinical lexicon and with the natural human language used in CLIP's pre-training data. Starting with captions used for images in PubMed articles, we extend them by passing the raw captions through an LLM fine-tuned on the field's several textbooks. We find that using captions generated by an expressive fine-tuned LLM like GPT-3.5 improves downstream zero-shot concept classification performance.
4/22/2024
MedRG: Medical Report Grounding with Multi-modal Large Language Model
Ke Zou, Yang Bai, Zhihao Chen, Yang Zhou, Yidi Chen, Kai Ren, Meng Wang, Xuedong Yuan, Xiaojing Shen, Huazhu Fu
0
0
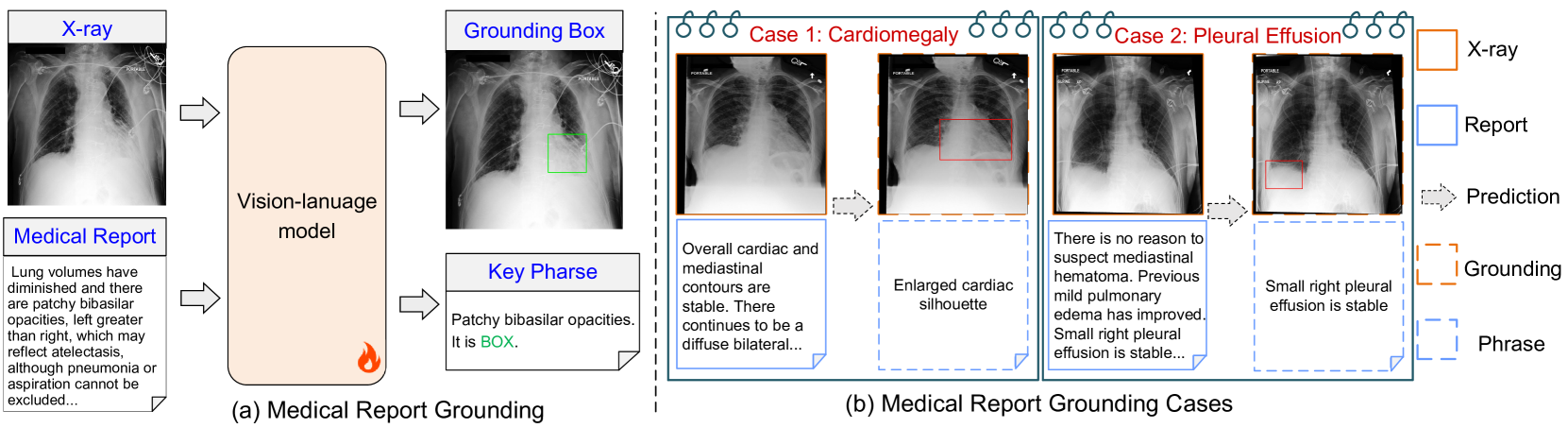
Medical Report Grounding is pivotal in identifying the most relevant regions in medical images based on a given phrase query, a critical aspect in medical image analysis and radiological diagnosis. However, prevailing visual grounding approaches necessitate the manual extraction of key phrases from medical reports, imposing substantial burdens on both system efficiency and physicians. In this paper, we introduce a novel framework, Medical Report Grounding (MedRG), an end-to-end solution for utilizing a multi-modal Large Language Model to predict key phrase by incorporating a unique token, BOX, into the vocabulary to serve as an embedding for unlocking detection capabilities. Subsequently, the vision encoder-decoder jointly decodes the hidden embedding and the input medical image, generating the corresponding grounding box. The experimental results validate the effectiveness of MedRG, surpassing the performance of the existing state-of-the-art medical phrase grounding methods. This study represents a pioneering exploration of the medical report grounding task, marking the first-ever endeavor in this domain.
4/11/2024

Diffusion based Zero-shot Medical Image-to-Image Translation for Cross Modality Segmentation
Zihao Wang, Yingyu Yang, Yuzhou Chen, Tingting Yuan, Maxime Sermesant, Herve Delingette, Ona Wu
0
0
Cross-modality image segmentation aims to segment the target modalities using a method designed in the source modality. Deep generative models can translate the target modality images into the source modality, thus enabling cross-modality segmentation. However, a vast body of existing cross-modality image translation methods relies on supervised learning. In this work, we aim to address the challenge of zero-shot learning-based image translation tasks (extreme scenarios in the target modality is unseen in the training phase). To leverage generative learning for zero-shot cross-modality image segmentation, we propose a novel unsupervised image translation method. The framework learns to translate the unseen source image to the target modality for image segmentation by leveraging the inherent statistical consistency between different modalities for diffusion guidance. Our framework captures identical cross-modality features in the statistical domain, offering diffusion guidance without relying on direct mappings between the source and target domains. This advantage allows our method to adapt to changing source domains without the need for retraining, making it highly practical when sufficient labeled source domain data is not available. The proposed framework is validated in zero-shot cross-modality image segmentation tasks through empirical comparisons with influential generative models, including adversarial-based and diffusion-based models.
4/11/2024

Zero-shot Referring Expression Comprehension via Structural Similarity Between Images and Captions
Zeyu Han, Fangrui Zhu, Qianru Lao, Huaizu Jiang
0
0
Zero-shot referring expression comprehension aims at localizing bounding boxes in an image corresponding to provided textual prompts, which requires: (i) a fine-grained disentanglement of complex visual scene and textual context, and (ii) a capacity to understand relationships among disentangled entities. Unfortunately, existing large vision-language alignment (VLA) models, e.g., CLIP, struggle with both aspects so cannot be directly used for this task. To mitigate this gap, we leverage large foundation models to disentangle both images and texts into triplets in the format of (subject, predicate, object). After that, grounding is accomplished by calculating the structural similarity matrix between visual and textual triplets with a VLA model, and subsequently propagate it to an instance-level similarity matrix. Furthermore, to equip VLA models with the ability of relationship understanding, we design a triplet-matching objective to fine-tune the VLA models on a collection of curated dataset containing abundant entity relationships. Experiments demonstrate that our visual grounding performance increase of up to 19.5% over the SOTA zero-shot model on RefCOCO/+/g. On the more challenging Who's Waldo dataset, our zero-shot approach achieves comparable accuracy to the fully supervised model. Code is available at https://github.com/Show-han/Zeroshot_REC.
4/10/2024