Quantum Multi-Agent Reinforcement Learning for Cooperative Mobile Access in Space-Air-Ground Integrated Networks
2406.16994
0
0
Abstract
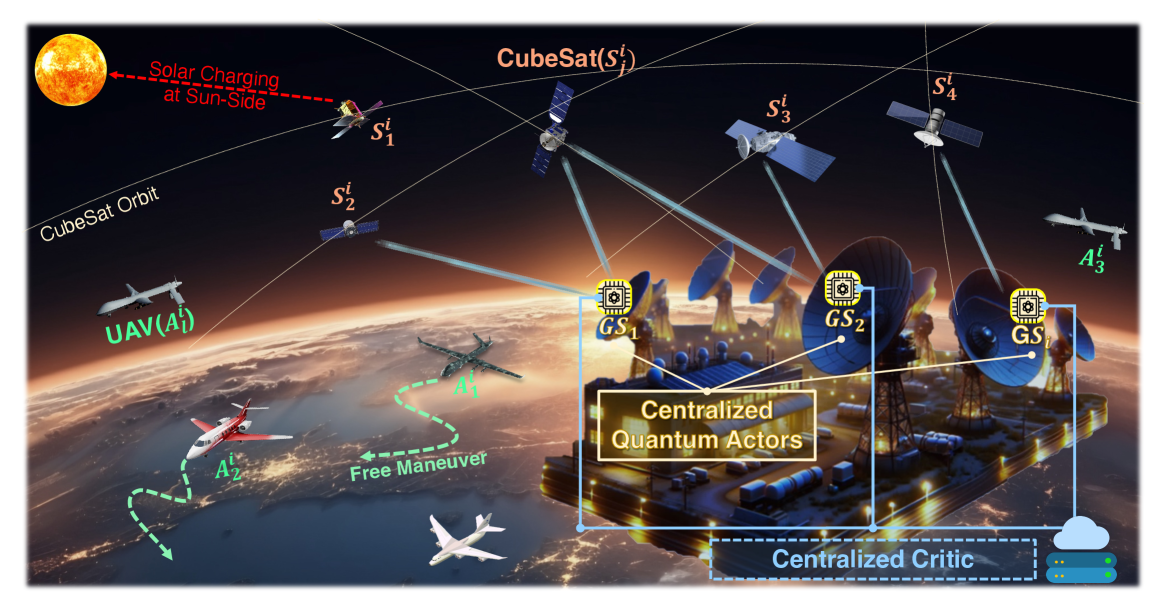
Achieving global space-air-ground integrated network (SAGIN) access only with CubeSats presents significant challenges such as the access sustainability limitations in specific regions (e.g., polar regions) and the energy efficiency limitations in CubeSats. To tackle these problems, high-altitude long-endurance unmanned aerial vehicles (HALE-UAVs) can complement these CubeSat shortcomings for providing cooperatively global access sustainability and energy efficiency. However, as the number of CubeSats and HALE-UAVs, increases, the scheduling dimension of each ground station (GS) increases. As a result, each GS can fall into the curse of dimensionality, and this challenge becomes one major hurdle for efficient global access. Therefore, this paper provides a quantum multi-agent reinforcement Learning (QMARL)-based method for scheduling between GSs and CubeSats/HALE-UAVs in order to improve global access availability and energy efficiency. The main reason why the QMARL-based scheduler can be beneficial is that the algorithm facilitates a logarithmic-scale reduction in scheduling action dimensions, which is one critical feature as the number of CubeSats and HALE-UAVs expands. Additionally, individual GSs have different traffic demands depending on their locations and characteristics, thus it is essential to provide differentiated access services. The superiority of the proposed scheduler is validated through data-intensive experiments in realistic CubeSat/HALE-UAV settings.
Create account to get full access
Overview
- Quantum Multi-Agent Reinforcement Learning (QMARL) for cooperative mobile access in Space-Air-Ground Integrated Networks (SAGIN)
- Leverages Quantum Neural Networks (QNNs) to enable efficient communication and coordination among agents (e.g., cube satellites, high-altitude long-endurance unmanned aerial vehicles)
- Aims to optimize network connectivity and resource allocation in dynamic, complex SAGIN environments
Plain English Explanation
The paper presents a novel approach called Quantum Multi-Agent Reinforcement Learning (QMARL) to address the challenges of providing reliable and efficient mobile access in complex Space-Air-Ground Integrated Networks (SAGIN). SAGIN environments involve a diverse range of interconnected devices, such as cube satellites and high-altitude long-endurance unmanned aerial vehicles (HALE-UAVs), that need to coordinate their actions to maintain network connectivity and optimize resource allocation.
The researchers leverage the unique properties of Quantum Neural Networks (QNNs) to enable efficient communication and coordination among the agents in the SAGIN. By harnessing the principles of quantum mechanics, such as superposition and entanglement, the QMARL approach can facilitate more effective decision-making and task allocation, ultimately improving the overall performance and resilience of the integrated network.
Technical Explanation
The paper proposes a QMARL framework for cooperative mobile access in SAGIN environments. The key components of the framework include:
-
Quantum Neural Network (QNN) Architecture: The agents in the SAGIN (e.g., cube satellites, HALE-UAVs) are equipped with QNNs that enable them to learn and make decisions in a quantum-inspired manner. The QNN architecture leverages quantum computing principles, such as superposition and entanglement, to enhance the agents' ability to perceive and respond to the dynamic network conditions.
-
Quantum Multi-Agent Reinforcement Learning (QMARL) Algorithm: The researchers develop a QMARL algorithm that allows the agents to cooperatively learn and optimize their actions through the use of quantum-inspired reward functions and update rules. This enables the agents to make more informed decisions and coordinate their efforts to achieve the overall network objectives, such as maximizing connectivity and minimizing resource utilization.
-
Decentralized Decision-Making: The QMARL framework employs a decentralized approach, where each agent makes autonomous decisions based on its local observations and interactions with other agents. This distributed decision-making strategy enhances the scalability and resilience of the SAGIN, as it reduces the reliance on a central controller and allows the network to adapt to changes more effectively.
The researchers evaluate the performance of the QMARL framework through simulation experiments, comparing it to traditional multi-agent reinforcement learning approaches. The results demonstrate the advantages of the QMARL approach in terms of improving network connectivity, resource allocation, and energy efficiency in SAGIN environments.
Critical Analysis
The paper presents a promising approach to addressing the challenges of mobile access in complex SAGIN environments. The use of QMARL leverages the unique properties of quantum computing to enhance the decision-making capabilities of the agents, which is a novel and innovative idea.
However, the authors acknowledge several limitations and areas for further research. For instance, the scalability of the QMARL framework as the number of agents and the complexity of the SAGIN increase needs to be further investigated. Additionally, the practicality of implementing QNN-based agents in real-world SAGIN deployments may be hindered by the current technological limitations and the availability of quantum hardware.
Moreover, the paper does not provide a comprehensive analysis of the potential security and privacy implications of the QMARL approach. As with any distributed decision-making system, there may be concerns regarding the vulnerability of the network to malicious attacks or the privacy of the data exchanged among the agents.
Further research is needed to address these limitations and explore the broader implications of the QMARL framework for the design and optimization of future SAGIN systems. Nonetheless, the approach presented in this paper represents an important step forward in the field of quantum-inspired multi-agent coordination and resource management.
Conclusion
The paper introduces a novel Quantum Multi-Agent Reinforcement Learning (QMARL) framework to address the challenges of cooperative mobile access in Space-Air-Ground Integrated Networks (SAGIN). By leveraging the unique properties of Quantum Neural Networks (QNNs), the QMARL approach enables efficient communication, coordination, and decision-making among the diverse agents (e.g., cube satellites, HALE-UAVs) in SAGIN environments.
The QMARL framework's decentralized, quantum-inspired approach has the potential to enhance the connectivity, resource allocation, and energy efficiency of SAGIN systems. While the paper identifies some limitations and areas for further research, the overall approach represents a significant advancement in the field of quantum-inspired multi-agent coordination and resource management, with promising implications for the future development of resilient and adaptive SAGIN architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

eQMARL: Entangled Quantum Multi-Agent Reinforcement Learning for Distributed Cooperation over Quantum Channels
Alexander DeRieux, Walid Saad
0
0
Collaboration is a key challenge in distributed multi-agent reinforcement learning (MARL) environments. Learning frameworks for these decentralized systems must weigh the benefits of explicit player coordination against the communication overhead and computational cost of sharing local observations and environmental data. Quantum computing has sparked a potential synergy between quantum entanglement and cooperation in multi-agent environments, which could enable more efficient distributed collaboration with minimal information sharing. This relationship is largely unexplored, however, as current state-of-the-art quantum MARL (QMARL) implementations rely on classical information sharing rather than entanglement over a quantum channel as a coordination medium. In contrast, in this paper, a novel framework dubbed entangled QMARL (eQMARL) is proposed. The proposed eQMARL is a distributed actor-critic framework that facilitates cooperation over a quantum channel and eliminates local observation sharing via a quantum entangled split critic. Introducing a quantum critic uniquely spread across the agents allows coupling of local observation encoders through entangled input qubits over a quantum channel, which requires no explicit sharing of local observations and reduces classical communication overhead. Further, agent policies are tuned through joint observation-value function estimation via joint quantum measurements, thereby reducing the centralized computational burden. Experimental results show that eQMARL with ${Psi}^{+}$ entanglement converges to a cooperative strategy up to $17.8%$ faster and with a higher overall score compared to split classical and fully centralized classical and quantum baselines. The results also show that eQMARL achieves this performance with a constant factor of $25$-times fewer centralized parameters compared to the split classical baseline.
5/29/2024
🏅
Multi-Agent Reinforcement Learning for Offloading Cellular Communications with Cooperating UAVs
Abhishek Mondal, Deepak Mishra, Ganesh Prasad, George C. Alexandropoulos, Azzam Alnahari, Riku Jantti
0
0
Effective solutions for intelligent data collection in terrestrial cellular networks are crucial, especially in the context of Internet of Things applications. The limited spectrum and coverage area of terrestrial base stations pose challenges in meeting the escalating data rate demands of network users. Unmanned aerial vehicles, known for their high agility, mobility, and flexibility, present an alternative means to offload data traffic from terrestrial BSs, serving as additional access points. This paper introduces a novel approach to efficiently maximize the utilization of multiple UAVs for data traffic offloading from terrestrial BSs. Specifically, the focus is on maximizing user association with UAVs by jointly optimizing UAV trajectories and users association indicators under quality of service constraints. Since, the formulated UAVs control problem is nonconvex and combinatorial, this study leverages the multi agent reinforcement learning framework. In this framework, each UAV acts as an independent agent, aiming to maintain inter UAV cooperative behavior. The proposed approach utilizes the finite state Markov decision process to account for UAVs velocity constraints and the relationship between their trajectories and state space. A low complexity distributed state action reward state action algorithm is presented to determine UAVs optimal sequential decision making policies over training episodes. The extensive simulation results validate the proposed analysis and offer valuable insights into the optimal UAV trajectories. The derived trajectories demonstrate superior average UAV association performance compared to benchmark techniques such as Q learning and particle swarm optimization.
6/4/2024

Optimizing Search and Rescue UAV Connectivity in Challenging Terrain through Multi Q-Learning
Mohammed M. H. Qazzaz, Syed A. R. Zaidi, Desmond C. McLernon, Abdelaziz Salama, Aubida A. Al-Hameed
0
0
Using Unmanned Aerial Vehicles (UAVs) in Search and rescue operations (SAR) to navigate challenging terrain while maintaining reliable communication with the cellular network is a promising approach. This paper suggests a novel technique employing a reinforcement learning multi Q-learning algorithm to optimize UAV connectivity in such scenarios. We introduce a Strategic Planning Agent for efficient path planning and collision awareness and a Real-time Adaptive Agent to maintain optimal connection with the cellular base station. The agents trained in a simulated environment using multi Q-learning, encouraging them to learn from experience and adjust their decision-making to diverse terrain complexities and communication scenarios. Evaluation results reveal the significance of the approach, highlighting successful navigation in environments with varying obstacle densities and the ability to perform optimal connectivity using different frequency bands. This work paves the way for enhanced UAV autonomy and enhanced communication reliability in search and rescue operations.
5/17/2024

Cached Model-as-a-Resource: Provisioning Large Language Model Agents for Edge Intelligence in Space-air-ground Integrated Networks
Minrui Xu, Dusit Niyato, Hongliang Zhang, Jiawen Kang, Zehui Xiong, Shiwen Mao, Zhu Han
0
0
Edge intelligence in space-air-ground integrated networks (SAGINs) can enable worldwide network coverage beyond geographical limitations for users to access ubiquitous and low-latency intelligence services. Facing global coverage and complex environments in SAGINs, edge intelligence can provision approximate large language models (LLMs) agents for users via edge servers at ground base stations (BSs) or cloud data centers relayed by satellites. As LLMs with billions of parameters are pre-trained on vast datasets, LLM agents have few-shot learning capabilities, e.g., chain-of-thought (CoT) prompting for complex tasks, which raises a new trade-off between resource consumption and performance in SAGINs. In this paper, we propose a joint caching and inference framework for edge intelligence to provision sustainable and ubiquitous LLM agents in SAGINs. We introduce cached model-as-a-resource for offering LLMs with limited context windows and propose a novel optimization framework, i.e., joint model caching and inference, to utilize cached model resources for provisioning LLM agent services along with communication, computing, and storage resources. We design age of thought (AoT) considering the CoT prompting of LLMs, and propose a least AoT cached model replacement algorithm for optimizing the provisioning cost. We propose a deep Q-network-based modified second-bid (DQMSB) auction to incentivize network operators, which can enhance allocation efficiency by 23% while guaranteeing strategy-proofness and free from adverse selection.
6/3/2024