Quasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search for Vision Transformers

0

Sign in to get full access
Overview
- The research paper presents Quasar-ViT, a hardware-oriented quantization-aware architecture search method for Vision Transformers (ViTs).
- Quasar-ViT aims to find efficient ViT architectures that can be effectively quantized for hardware acceleration.
- The key contributions include a quantization-aware search strategy, a hardware-oriented reward function, and insights on designing quantizable ViT models.
Plain English Explanation
The paper focuses on making Vision Transformers (ViTs) more efficient and suitable for hardware acceleration. ViTs are a type of machine learning model that has shown promising results in computer vision tasks, but they can be computationally intensive and difficult to run on hardware like smartphones or embedded devices.
To address this, the researchers developed a method called Quasar-ViT. The main idea is to automatically search for ViT architectures that are optimized for hardware acceleration through quantization - a technique that reduces the precision of the model's numerical parameters to make it smaller and faster to run.
The key innovations of Quasar-ViT include:
- A search strategy that considers how well the ViT architecture can be quantized during the search process, rather than just optimizing for model accuracy.
- A reward function that evaluates the efficiency of the ViT architecture on target hardware, rather than just its overall performance.
- Insights on how to design ViT models that are more amenable to quantization and hardware acceleration, such as using certain types of attention layers and activation functions.
By incorporating hardware considerations into the architecture search, Quasar-ViT is able to find ViT models that are both accurate and efficient to run on real-world hardware. This could make ViTs more practical for deployment on devices with limited computing resources, such as smartphones or drones.
Technical Explanation
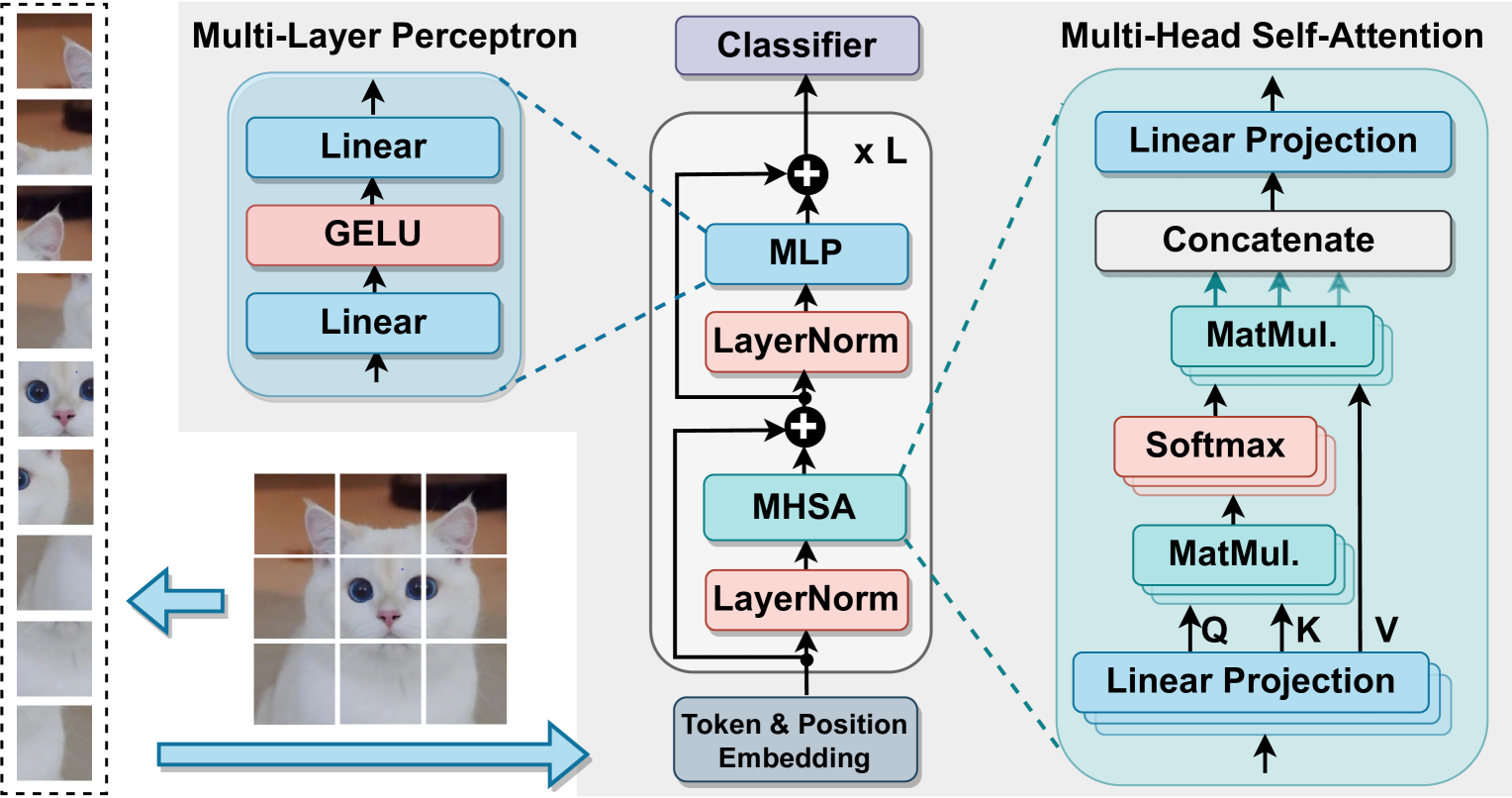
The paper introduces Quasar-ViT, a novel hardware-oriented quantization-aware architecture search method for Vision Transformers (ViTs). The key innovations include:
-
Quantization-Aware Search Strategy: Rather than just optimizing for model accuracy, Quasar-ViT's search strategy considers how well the ViT architecture can be quantized during the search process. This helps find models that are not only accurate, but also efficiently quantizable for hardware acceleration.
-
Hardware-Oriented Reward Function: Quasar-ViT uses a reward function that evaluates the efficiency of the ViT architecture on target hardware, such as latency and energy consumption, in addition to model accuracy. This hardware-oriented optimization helps identify ViT models that are well-suited for real-world deployment.
-
Quantizable ViT Design Insights: Through extensive experiments, the researchers provide insights on how to design ViT models that are more amenable to quantization and hardware acceleration. This includes using certain types of attention layers, activation functions, and other architectural choices.
The paper evaluates Quasar-ViT on several computer vision benchmarks, demonstrating that it can find ViT models that are both accurate and efficient to run on hardware, outperforming existing methods. This is an important step towards making ViTs more practical for deployment on resource-constrained devices such as smartphones, drones, and embedded systems.
Critical Analysis
The paper makes a compelling case for the importance of hardware-oriented quantization-aware architecture search for Vision Transformers. By considering quantization and hardware efficiency during the search process, Quasar-ViT is able to find ViT models that are well-suited for real-world deployment.
However, the paper does not address some potential limitations and areas for further research:
-
Generalization to Other Hardware: The evaluation is primarily focused on a specific hardware target (NVIDIA Jetson Nano). It would be valuable to understand how well the Quasar-ViT models generalize to other hardware platforms, such as mobile CPUs or specialized AI accelerators.
-
Architectural Flexibility: While the paper provides insights on quantizable ViT design, the search space may still be somewhat constrained. Exploring more flexible ViT architectures, or allowing the search to modify the attention layers and other components, could lead to even more efficient models.
-
Comparison to Manual Design: It would be interesting to compare the Quasar-ViT models to ViTs that have been manually designed and quantized by experts. This could provide further insights into the strengths and limitations of the automated search approach.
-
Scalability to Larger Models: The experiments in the paper focus on relatively small ViT models. Evaluating the scalability of Quasar-ViT to larger, more complex ViT architectures would be an important next step.
Overall, the Quasar-ViT method represents a valuable contribution to the field of efficient and hardware-accelerated Vision Transformers. The insights and techniques presented in the paper could help make ViTs more practical for a wide range of real-world applications.
Conclusion
The Quasar-ViT paper presents a novel hardware-oriented quantization-aware architecture search method for Vision Transformers. By considering quantization and hardware efficiency during the search process, Quasar-ViT is able to find ViT models that are both accurate and efficient to run on real-world hardware, such as embedded devices and mobile platforms.
The key innovations of Quasar-ViT include a quantization-aware search strategy, a hardware-oriented reward function, and insights on designing quantizable ViT models. This work represents an important step towards making Vision Transformers more practical and deployable in resource-constrained environments, which could have significant implications for a wide range of computer vision applications.
While the paper demonstrates the effectiveness of Quasar-ViT, there are also opportunities for further research, such as exploring generalization to other hardware platforms, increasing architectural flexibility, and scaling to larger ViT models. Overall, this research contributes valuable tools and insights to the ongoing efforts to make advanced machine learning models more efficient and accessible for real-world use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Quasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search for Vision Transformers
Zhengang Li, Alec Lu, Yanyue Xie, Zhenglun Kong, Mengshu Sun, Hao Tang, Zhong Jia Xue, Peiyan Dong, Caiwen Ding, Yanzhi Wang, Xue Lin, Zhenman Fang
Vision transformers (ViTs) have demonstrated their superior accuracy for computer vision tasks compared to convolutional neural networks (CNNs). However, ViT models are often computation-intensive for efficient deployment on resource-limited edge devices. This work proposes Quasar-ViT, a hardware-oriented quantization-aware architecture search framework for ViTs, to design efficient ViT models for hardware implementation while preserving the accuracy. First, Quasar-ViT trains a supernet using our row-wise flexible mixed-precision quantization scheme, mixed-precision weight entanglement, and supernet layer scaling techniques. Then, it applies an efficient hardware-oriented search algorithm, integrated with hardware latency and resource modeling, to determine a series of optimal subnets from supernet under different inference latency targets. Finally, we propose a series of model-adaptive designs on the FPGA platform to support the architecture search and mitigate the gap between the theoretical computation reduction and the practical inference speedup. Our searched models achieve 101.5, 159.6, and 251.6 frames-per-second (FPS) inference speed on the AMD/Xilinx ZCU102 FPGA with 80.4%, 78.6%, and 74.9% top-1 accuracy, respectively, for the ImageNet dataset, consistently outperforming prior works.
Read more7/26/2024
📈
0
Model Quantization and Hardware Acceleration for Vision Transformers: A Comprehensive Survey
Dayou Du, Gu Gong, Xiaowen Chu
Vision Transformers (ViTs) have recently garnered considerable attention, emerging as a promising alternative to convolutional neural networks (CNNs) in several vision-related applications. However, their large model sizes and high computational and memory demands hinder deployment, especially on resource-constrained devices. This underscores the necessity of algorithm-hardware co-design specific to ViTs, aiming to optimize their performance by tailoring both the algorithmic structure and the underlying hardware accelerator to each other's strengths. Model quantization, by converting high-precision numbers to lower-precision, reduces the computational demands and memory needs of ViTs, allowing the creation of hardware specifically optimized for these quantized algorithms, boosting efficiency. This article provides a comprehensive survey of ViTs quantization and its hardware acceleration. We first delve into the unique architectural attributes of ViTs and their runtime characteristics. Subsequently, we examine the fundamental principles of model quantization, followed by a comparative analysis of the state-of-the-art quantization techniques for ViTs. Additionally, we explore the hardware acceleration of quantized ViTs, highlighting the importance of hardware-friendly algorithm design. In conclusion, this article will discuss ongoing challenges and future research paths. We consistently maintain the related open-source materials at https://github.com/DD-DuDa/awesome-vit-quantization-acceleration.
Read more5/2/2024
0
Trio-ViT: Post-Training Quantization and Acceleration for Softmax-Free Efficient Vision Transformer
Huihong Shi, Haikuo Shao, Wendong Mao, Zhongfeng Wang
Motivated by the huge success of Transformers in the field of natural language processing (NLP), Vision Transformers (ViTs) have been rapidly developed and achieved remarkable performance in various computer vision tasks. However, their huge model sizes and intensive computations hinder ViTs' deployment on embedded devices, calling for effective model compression methods, such as quantization. Unfortunately, due to the existence of hardware-unfriendly and quantization-sensitive non-linear operations, particularly {Softmax}, it is non-trivial to completely quantize all operations in ViTs, yielding either significant accuracy drops or non-negligible hardware costs. In response to challenges associated with textit{standard ViTs}, we focus our attention towards the quantization and acceleration for textit{efficient ViTs}, which not only eliminate the troublesome Softmax but also integrate linear attention with low computational complexity, and propose emph{Trio-ViT} accordingly. Specifically, at the algorithm level, we develop a {tailored post-training quantization engine} taking the unique activation distributions of Softmax-free efficient ViTs into full consideration, aiming to boost quantization accuracy. Furthermore, at the hardware level, we build an accelerator dedicated to the specific Convolution-Transformer hybrid architecture of efficient ViTs, thereby enhancing hardware efficiency. Extensive experimental results consistently prove the effectiveness of our Trio-ViT framework. {Particularly, we can gain up to $uparrow$$mathbf{7.2}times$ and $uparrow$$mathbf{14.6}times$ FPS under comparable accuracy over state-of-the-art ViT accelerators, as well as $uparrow$$mathbf{5.9}times$ and $uparrow$$mathbf{2.0}times$ DSP efficiency.} Codes will be released publicly upon acceptance.
Read more5/8/2024
👀
0
Q-HyViT: Post-Training Quantization of Hybrid Vision Transformers with Bridge Block Reconstruction for IoT Systems
Jemin Lee, Yongin Kwon, Sihyeong Park, Misun Yu, Jeman Park, Hwanjun Song
Recently, vision transformers (ViTs) have superseded convolutional neural networks in numerous applications, including classification, detection, and segmentation. However, the high computational requirements of ViTs hinder their widespread implementation. To address this issue, researchers have proposed efficient hybrid transformer architectures that combine convolutional and transformer layers with optimized attention computation of linear complexity. Additionally, post-training quantization has been proposed as a means of mitigating computational demands. For mobile devices, achieving optimal acceleration for ViTs necessitates the strategic integration of quantization techniques and efficient hybrid transformer structures. However, no prior investigation has applied quantization to efficient hybrid transformers. In this paper, we discover that applying existing post-training quantization (PTQ) methods for ViTs to efficient hybrid transformers leads to a drastic accuracy drop, attributed to the four following challenges: (i) highly dynamic ranges, (ii) zero-point overflow, (iii) diverse normalization, and (iv) limited model parameters ($<$5M). To overcome these challenges, we propose a new post-training quantization method, which is the first to quantize efficient hybrid ViTs (MobileViTv1, MobileViTv2, Mobile-Former, EfficientFormerV1, EfficientFormerV2). We achieve a significant improvement of 17.73% for 8-bit and 29.75% for 6-bit on average, respectively, compared with existing PTQ methods (EasyQuant, FQ-ViT, PTQ4ViT, and RepQ-ViT)}. We plan to release our code at https://gitlab.com/ones-ai/q-hyvit.
Read more5/20/2024