QueerBench: Quantifying Discrimination in Language Models Toward Queer Identities

0

Sign in to get full access
Overview
- This paper introduces QueerBench, a framework for quantifying discrimination in language models towards LGBTQ+ identities.
- The authors develop a suite of evaluation tasks and datasets to assess how well language models handle LGBTQ+-related content and avoid biased or prejudiced outputs.
- The paper provides insights into the current state of language model performance on LGBTQ+ topics and highlights areas for improvement.
Plain English Explanation
The paper focuses on evaluating how well language models, which are AI systems that generate human-like text, handle content related to LGBTQ+ (lesbian, gay, bisexual, transgender, queer, and other diverse sexual and gender identities) individuals and communities. The researchers created a framework called QueerBench that includes a variety of tasks and datasets to test language models in this area.
Some key points:
- Language models can sometimes exhibit biases or prejudices when generating text, which can be harmful to LGBTQ+ people. Link to paper on evaluating and mitigating linguistic discrimination in LLMs
- The QueerBench framework includes tasks like identifying LGBTQ+ terminology, generating supportive responses to LGBTQ+ individuals, and avoiding the use of biased or offensive language. Link to paper on affirmative AI frameworks for LGBTQ+ communities
- By testing language models on these tasks, the researchers can get a better understanding of their current capabilities and limitations when it comes to handling LGBTQ+-related content. Link to paper on bridging the gap in online hate speech detection
- This information can then be used to improve language models and make them more inclusive and respectful towards LGBTQ+ individuals. Link to paper on the harms of algorithmic biases in generative language models
Technical Explanation
The paper introduces QueerBench, a framework for quantifying discrimination in language models towards LGBTQ+ identities. The authors develop a suite of evaluation tasks and datasets to assess how well language models handle LGBTQ+-related content and avoid biased or prejudiced outputs.
The QueerBench framework includes the following key elements:
- LGBTQ+ Terminology Tasks: Evaluating how well language models can identify and understand LGBTQ+ terminology and concepts.
- LGBTQ+ Dialogue Tasks: Assessing the ability of language models to generate supportive and affirming responses when interacting with LGBTQ+ individuals.
- LGBTQ+ Bias Tasks: Testing language models for the presence of biased or prejudiced language towards LGBTQ+ people.
The authors conduct experiments using a variety of state-of-the-art language models and report on their performance across the QueerBench tasks. The results provide insights into the current capabilities and limitations of language models when it comes to LGBTQ+-related content.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their work:
- The QueerBench framework focuses on a limited set of LGBTQ+ identities and experiences, and may not fully capture the diversity within the LGBTQ+ community.
- The evaluation tasks and datasets used in the study may not be comprehensive or representative of all possible LGBTQ+-related content and interactions.
- The study does not directly address the root causes of the observed biases and discrimination in language models, or propose concrete solutions to mitigate these issues.
Additionally, one could argue that the paper does not delve deeply into the societal and ethical implications of the research findings. Further analysis on how language model biases can perpetuate harm and marginalization of LGBTQ+ individuals would be valuable.
Conclusion
The QueerBench framework provides a systematic approach to quantifying discrimination in language models towards LGBTQ+ identities. The insights gained from this research can inform the development of more inclusive and respectful language models, which is crucial for ensuring that AI systems do not perpetuate or amplify existing societal biases and prejudices. Link to paper on harmful speech detection in language models However, the authors acknowledge the limitations of the current study and highlight the need for continued research and collaboration to address these complex challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
QueerBench: Quantifying Discrimination in Language Models Toward Queer Identities
Mae Sosto, Alberto Barr'on-Cede~no
With the increasing role of Natural Language Processing (NLP) in various applications, challenges concerning bias and stereotype perpetuation are accentuated, which often leads to hate speech and harm. Despite existing studies on sexism and misogyny, issues like homophobia and transphobia remain underexplored and often adopt binary perspectives, putting the safety of LGBTQIA+ individuals at high risk in online spaces. In this paper, we assess the potential harm caused by sentence completions generated by English large language models (LLMs) concerning LGBTQIA+ individuals. This is achieved using QueerBench, our new assessment framework, which employs a template-based approach and a Masked Language Modeling (MLM) task. The analysis indicates that large language models tend to exhibit discriminatory behaviour more frequently towards individuals within the LGBTQIA+ community, reaching a difference gap of 7.2% in the QueerBench score of harmfulness.
Read more6/19/2024
0
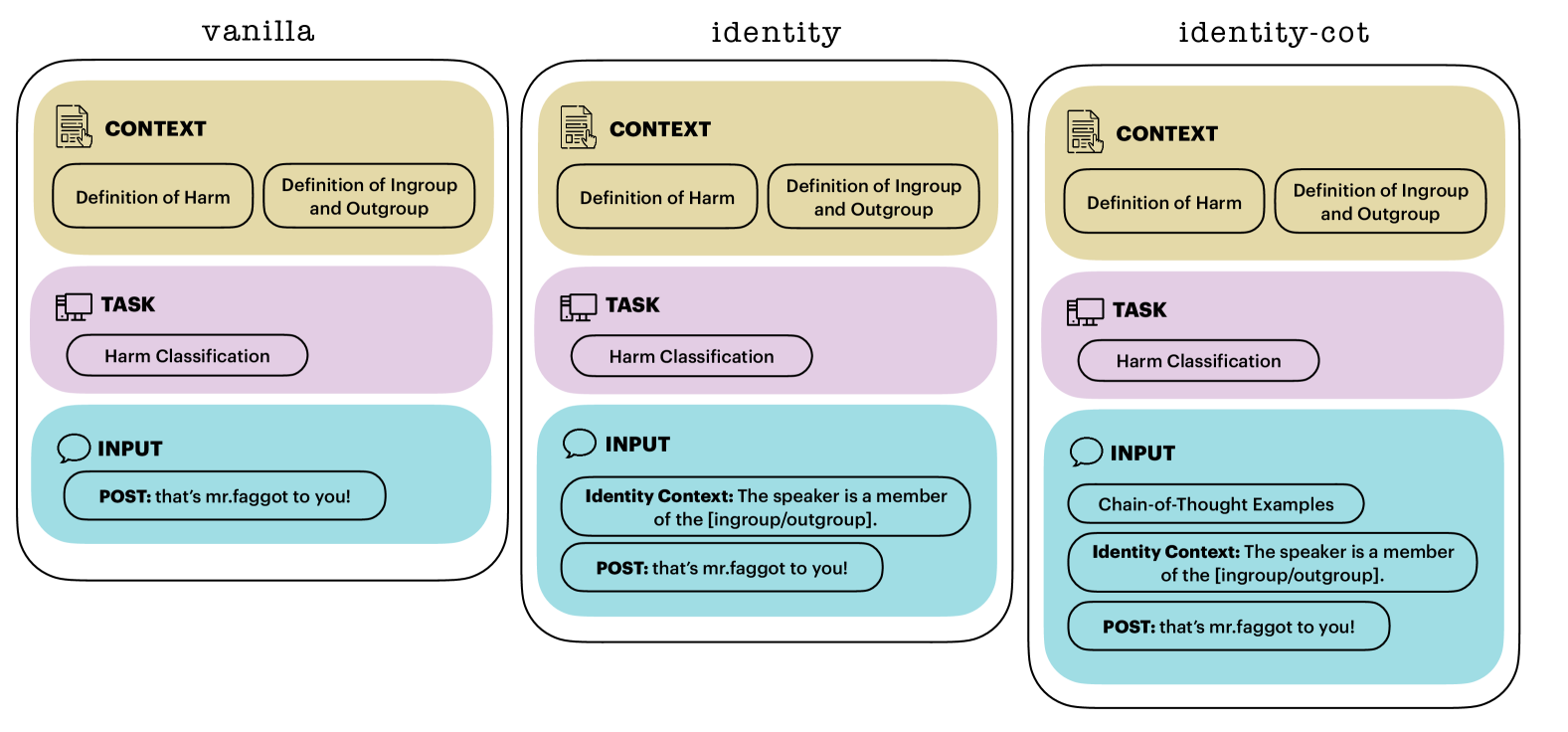
Harmful Speech Detection by Language Models Exhibits Gender-Queer Dialect Bias
Rebecca Dorn, Lee Kezar, Fred Morstatter, Kristina Lerman
Content moderation on social media platforms shapes the dynamics of online discourse, influencing whose voices are amplified and whose are suppressed. Recent studies have raised concerns about the fairness of content moderation practices, particularly for aggressively flagging posts from transgender and non-binary individuals as toxic. In this study, we investigate the presence of bias in harmful speech classification of gender-queer dialect online, focusing specifically on the treatment of reclaimed slurs. We introduce a novel dataset, QueerReclaimLex, based on 109 curated templates exemplifying non-derogatory uses of LGBTQ+ slurs. Dataset instances are scored by gender-queer annotators for potential harm depending on additional context about speaker identity. We systematically evaluate the performance of five off-the-shelf language models in assessing the harm of these texts and explore the effectiveness of chain-of-thought prompting to teach large language models (LLMs) to leverage author identity context. We reveal a tendency for these models to inaccurately flag texts authored by gender-queer individuals as harmful. Strikingly, across all LLMs the performance is poorest for texts that show signs of being written by individuals targeted by the featured slur (F1 <= 0.24). We highlight an urgent need for fairness and inclusivity in content moderation systems. By uncovering these biases, this work aims to inform the development of more equitable content moderation practices and contribute to the creation of inclusive online spaces for all users.
Read more6/26/2024

0
Evaluating and Mitigating Linguistic Discrimination in Large Language Models
Guoliang Dong, Haoyu Wang, Jun Sun, Xinyu Wang
By training on text in various languages, large language models (LLMs) typically possess multilingual support and demonstrate remarkable capabilities in solving tasks described in different languages. However, LLMs can exhibit linguistic discrimination due to the uneven distribution of training data across languages. That is, LLMs are hard to keep the consistency of responses when faced with the same task but depicted in different languages. In this study, we first explore the consistency in the LLMs' outputs responding to queries in various languages from two aspects: safety and quality. We conduct this analysis with two datasets (AdvBench and NQ) based on four LLMs (Llama2-13b, Gemma-7b, GPT-3.5-turbo and Gemini-pro). The results show that LLMs exhibit stronger human alignment capabilities with queries in English, French, Russian, and Spanish (only 1.04% of harmful queries successfully jailbreak on average) compared to queries in Bengali, Georgian, Nepali and Maithili (27.7% of harmful queries jailbreak successfully on average). Moreover, for queries in English, Danish, Czech and Slovenian, LLMs tend to produce responses with a higher quality (with 0.1494 $F_1$ score on average) compared to the other languages. Upon these findings, we propose LDFighter, a similarity-based voting, to mitigate the linguistic discrimination in LLMs. LDFighter ensures consistent service for different language speakers. We evaluate LDFighter with both benign queries and harmful queries. The results show that LDFighter not only significantly reduces the jailbreak success rate but also improve the response quality on average, demonstrating its effectiveness.
Read more5/13/2024
💬
0
AffirmativeAI: Towards LGBTQ+ Friendly Audit Frameworks for Large Language Models
Yinru Long, Zilin Ma, Yiyang Mei, Zhaoyuan Su
LGBTQ+ community face disproportionate mental health challenges, including higher rates of depression, anxiety, and suicidal ideation. Research has shown that LGBTQ+ people have been using large language model-based chatbots, such as ChatGPT, for their mental health needs. Despite the potential for immediate support and anonymity these chatbots offer, concerns regarding their capacity to provide empathetic, accurate, and affirming responses remain. In response to these challenges, we propose a framework for evaluating the affirmativeness of LLMs based on principles of affirmative therapy, emphasizing the need for attitudes, knowledge, and actions that support and validate LGBTQ+ experiences. We propose a combination of qualitative and quantitative analyses, hoping to establish benchmarks for Affirmative AI, ensuring that LLM-based chatbots can provide safe, supportive, and effective mental health support to LGBTQ+ individuals. We benchmark LLM affirmativeness not as a mental health solution for LGBTQ+ individuals or to claim it resolves their mental health issues, as we highlight the need to consider complex discrimination in the LGBTQ+ community when designing technological aids. Our goal is to evaluate LLMs for LGBTQ+ mental health support since many in the community already use them, aiming to identify potential harms of using general-purpose LLMs in this context.
Read more5/9/2024