RaFe: Ranking Feedback Improves Query Rewriting for RAG
2405.14431
0
0
👀
Abstract
As Large Language Models (LLMs) and Retrieval Augmentation Generation (RAG) techniques have evolved, query rewriting has been widely incorporated into the RAG system for downstream tasks like open-domain QA. Many works have attempted to utilize small models with reinforcement learning rather than costly LLMs to improve query rewriting. However, current methods require annotations (e.g., labeled relevant documents or downstream answers) or predesigned rewards for feedback, which lack generalization, and fail to utilize signals tailored for query rewriting. In this paper, we propose ours, a framework for training query rewriting models free of annotations. By leveraging a publicly available reranker, ours~provides feedback aligned well with the rewriting objectives. Experimental results demonstrate that ours~can obtain better performance than baselines.
Create account to get full access
Overview
- Large Language Models (LLMs) and Retrieval Augmentation Generation (RAG) techniques have been widely used for open-domain Question Answering (QA) tasks.
- Many researchers have explored using smaller models with reinforcement learning instead of costly LLMs to improve query rewriting in RAG systems.
- Current methods require annotations or pre-designed rewards, which lack generalization and fail to utilize signals tailored for query rewriting.
Plain English Explanation
Large language models (LLMs) and retrieval-augmented generation (RAG) techniques have become popular for open-domain question answering. Researchers have tried using smaller models with reinforcement learning instead of expensive LLMs to improve how these systems rewrite queries. However, existing methods require specialized annotations or pre-defined rewards, which limits their flexibility and doesn't take full advantage of the signals that are most relevant for improving query rewriting.
Technical Explanation
The paper proposes a framework called "ours" for training query rewriting models without the need for annotations. By leveraging a publicly available reranker, "ours" provides feedback that is well-aligned with the objectives of query rewriting. The experimental results demonstrate that "ours" can outperform baseline methods.
Critical Analysis
The paper addresses an important challenge in improving retrieval-augmented language models for question answering tasks. While the proposed "ours" framework is a step forward, it would be helpful to understand the specific limitations of the current methods that require annotations or pre-designed rewards, and how "ours" addresses those limitations. Additionally, the paper could explore potential drawbacks or edge cases of the "ours" approach, as well as areas for further research to continue advancing query rewriting techniques.
Conclusion
This paper presents a novel framework called "ours" for training query rewriting models without the need for annotations. By leveraging a public reranker, "ours" provides feedback that is well-aligned with the objectives of query rewriting, allowing it to outperform baseline methods. The research contributes to the ongoing efforts to improve retrieval-augmented language models for open-domain question answering tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
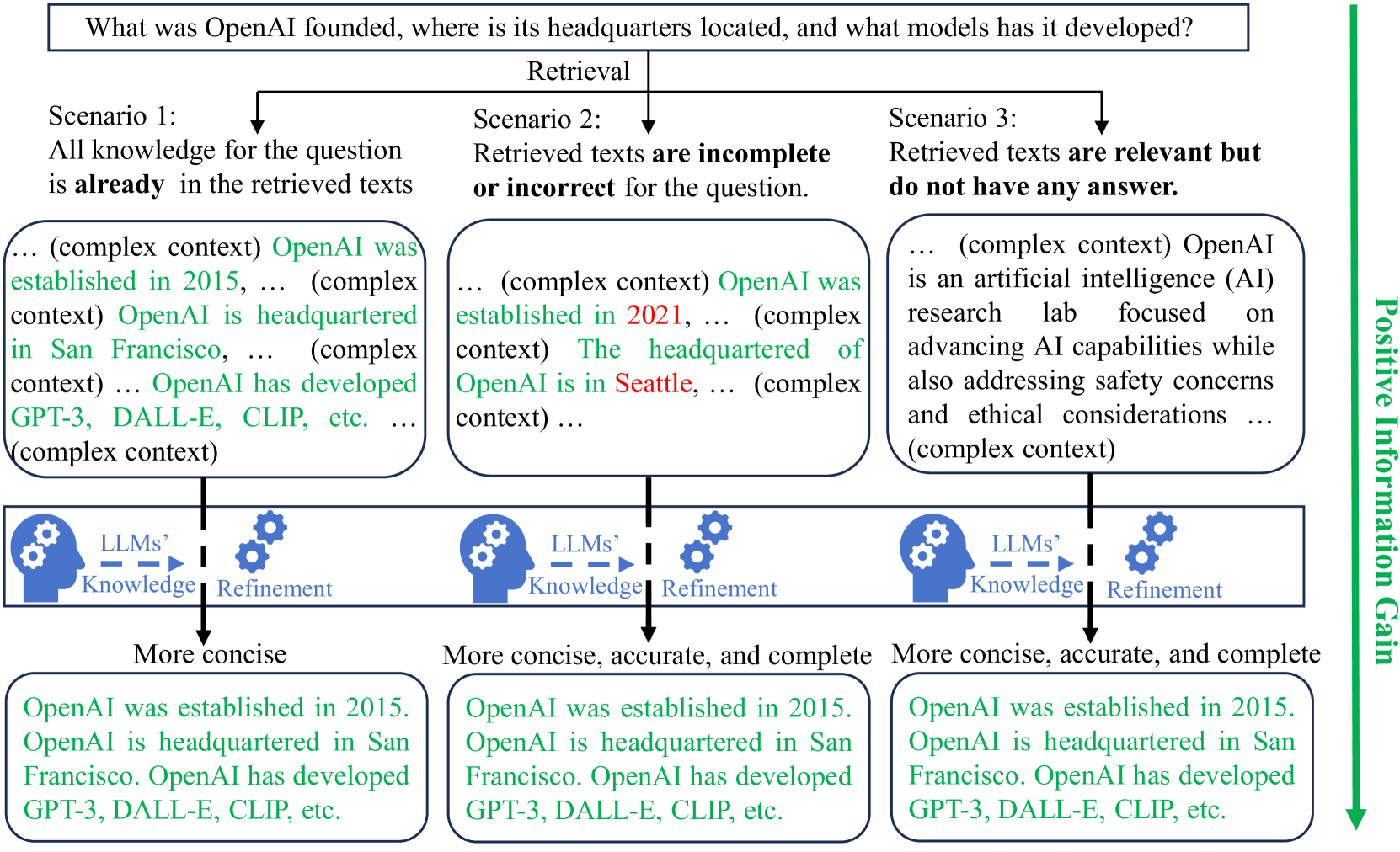
Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation
Shicheng Xu, Liang Pang, Mo Yu, Fandong Meng, Huawei Shen, Xueqi Cheng, Jie Zhou
0
0
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating additional information from retrieval. However, studies have shown that LLMs still face challenges in effectively using the retrieved information, even ignoring it or being misled by it. The key reason is that the training of LLMs does not clearly make LLMs learn how to utilize input retrieved texts with varied quality. In this paper, we propose a novel perspective that considers the role of LLMs in RAG as ``Information Refiner'', which means that regardless of correctness, completeness, or usefulness of retrieved texts, LLMs can consistently integrate knowledge within the retrieved texts and model parameters to generate the texts that are more concise, accurate, and complete than the retrieved texts. To this end, we propose an information refinement training method named InFO-RAG that optimizes LLMs for RAG in an unsupervised manner. InFO-RAG is low-cost and general across various tasks. Extensive experiments on zero-shot prediction of 11 datasets in diverse tasks including Question Answering, Slot-Filling, Language Modeling, Dialogue, and Code Generation show that InFO-RAG improves the performance of LLaMA2 by an average of 9.39% relative points. InFO-RAG also shows advantages in in-context learning and robustness of RAG.
6/13/2024

Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
Xun Liang, Simin Niu, Zhiyu li, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi
0
0
Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
5/28/2024
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Katherine Jijo, Eden Chung, Natan Vidra
0
0
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
4/12/2024
Towards a Search Engine for Machines: Unified Ranking for Multiple Retrieval-Augmented Large Language Models
Alireza Salemi, Hamed Zamani
0
0
This paper introduces uRAG--a framework with a unified retrieval engine that serves multiple downstream retrieval-augmented generation (RAG) systems. Each RAG system consumes the retrieval results for a unique purpose, such as open-domain question answering, fact verification, entity linking, and relation extraction. We introduce a generic training guideline that standardizes the communication between the search engine and the downstream RAG systems that engage in optimizing the retrieval model. This lays the groundwork for us to build a large-scale experimentation ecosystem consisting of 18 RAG systems that engage in training and 18 unknown RAG systems that use the uRAG as the new users of the search engine. Using this experimentation ecosystem, we answer a number of fundamental research questions that improve our understanding of promises and challenges in developing search engines for machines.
5/2/2024