Towards a Search Engine for Machines: Unified Ranking for Multiple Retrieval-Augmented Large Language Models
2405.00175
0
0
Abstract
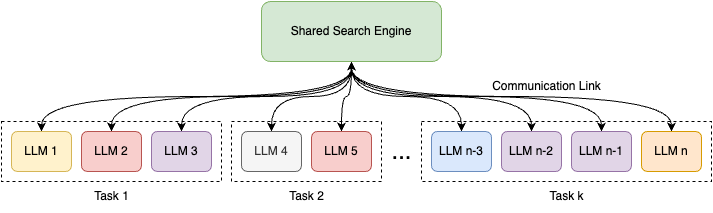
This paper introduces uRAG--a framework with a unified retrieval engine that serves multiple downstream retrieval-augmented generation (RAG) systems. Each RAG system consumes the retrieval results for a unique purpose, such as open-domain question answering, fact verification, entity linking, and relation extraction. We introduce a generic training guideline that standardizes the communication between the search engine and the downstream RAG systems that engage in optimizing the retrieval model. This lays the groundwork for us to build a large-scale experimentation ecosystem consisting of 18 RAG systems that engage in training and 18 unknown RAG systems that use the uRAG as the new users of the search engine. Using this experimentation ecosystem, we answer a number of fundamental research questions that improve our understanding of promises and challenges in developing search engines for machines.
Create account to get full access
Overview
- This paper proposes a unified ranking model for multiple retrieval-augmented large language models, which aims to enable an effective "search engine for machines" by improving the retrieval quality and downstream performance of these models.
- The key ideas include using a single neural ranking model to score and rank the output of different retrieval-augmented language models, and introducing a novel retrieval-augmented generation (RAG) model that leverages multiple knowledge sources.
- The proposed approach is evaluated on various benchmarks, demonstrating improvements over existing retrieval-augmented language models.
Plain English Explanation
The paper presents a new way to combine and rank the outputs of different large language models that use information retrieval to enhance their capabilities. The goal is to create a kind of "search engine for machines" that can effectively find and use relevant information to improve the performance of these models on various tasks.
The core idea is to use a single neural network to score and rank the outputs of multiple retrieval-augmented language models. This allows the system to learn how to best combine and select the most relevant information from different sources, rather than relying on individual models that may have limitations.
Additionally, the researchers introduce a new retrieval-augmented generation (RAG) model that can leverage multiple knowledge sources, further expanding the range of information it can access and utilize. This RAG model is evaluated alongside other retrieval-augmented approaches, demonstrating improved performance on a variety of benchmarks.
By developing this unified ranking and retrieval-augmented modeling approach, the researchers aim to lay the groundwork for more effective and versatile "search engines for machines" that can support a wide range of applications and tasks.
Technical Explanation
The paper proposes a "unified ranking" model for combining the outputs of multiple retrieval-augmented large language models. This model uses a single neural network to score and rank the responses generated by different retrieval-augmented models, rather than relying on individual model-specific ranking approaches.
The key components of the proposed system include:
-
Retrieval-Augmented Generation (RAG) Model: The researchers introduce a new RAG model that can leverage multiple knowledge sources, such as Wikipedia and other external corpora, to enhance its language generation capabilities. This expands on prior work on RAG models that typically relied on a single knowledge source.
-
Unified Ranking Model: This is a neural network that takes the outputs of multiple retrieval-augmented models (including the new RAG model) and learns to score and rank them, determining the most relevant and appropriate response for a given input.
-
Evaluation: The system is evaluated on various benchmarks, including question answering, open-ended dialogue, and text generation tasks. The results demonstrate that the unified ranking approach outperforms individual retrieval-augmented models, as well as other state-of-the-art methods.
The paper also discusses the potential of this unified ranking approach to enable a more effective "search engine for machines," where the system can intelligently combine and leverage information from different sources to support a wide range of applications and tasks.
Critical Analysis
The paper presents a compelling approach to improving the performance of retrieval-augmented language models by leveraging a unified ranking model. However, there are a few potential limitations and areas for further research:
-
Knowledge Source Diversity: While the new RAG model can leverage multiple knowledge sources, the paper does not explore the impact of using a more diverse set of sources beyond the standard Wikipedia corpus. Investigating the effects of incorporating different types of knowledge, such as domain-specific databases or real-time information, could further enhance the system's capabilities.
-
Interpretability and Explainability: The unified ranking model is a neural network, which can be a "black box" in terms of understanding how it makes decisions. Exploring methods to improve the interpretability and explainability of the model's reasoning could be valuable, especially in sensitive applications where transparency is important.
-
Computational Efficiency: The paper does not provide a detailed analysis of the computational cost and scalability of the unified ranking approach. As these models become more complex, it will be important to ensure they can be deployed efficiently in real-world settings.
-
Generalization and Robustness: While the evaluation demonstrates improved performance on various benchmarks, further research is needed to assess the model's ability to generalize to novel domains and its robustness to perturbations or distributional shifts in the input data.
Overall, the paper presents a promising step towards more effective "search engines for machines," but continued research and development will be necessary to address these potential limitations and further advance the capabilities of retrieval-augmented language models.
Conclusion
This paper proposes a unified ranking approach for combining the outputs of multiple retrieval-augmented large language models, with the goal of creating a more effective "search engine for machines." The key contributions include a novel retrieval-augmented generation (RAG) model that leverages multiple knowledge sources and a neural ranking model that can score and select the most relevant responses from different retrieval-augmented models.
The evaluation results demonstrate the benefits of this unified ranking approach, showing improvements over individual retrieval-augmented models and other state-of-the-art methods. This work lays the groundwork for more advanced "search engines for machines" that can effectively leverage diverse information sources to support a wide range of applications and tasks.
While the paper presents a promising step forward, further research is needed to address potential limitations, such as the diversity of knowledge sources, model interpretability, computational efficiency, and robustness. Continued advancements in these areas could lead to increasingly capable and versatile "search engines for machines" that can support a wide range of intelligent systems and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
New!Retrieval-augmented generation in multilingual settings
Nadezhda Chirkova, David Rau, Herv'e D'ejean, Thibault Formal, St'ephane Clinchant, Vassilina Nikoulina
0
0
Retrieval-augmented generation (RAG) has recently emerged as a promising solution for incorporating up-to-date or domain-specific knowledge into large language models (LLMs) and improving LLM factuality, but is predominantly studied in English-only settings. In this work, we consider RAG in the multilingual setting (mRAG), i.e. with user queries and the datastore in 13 languages, and investigate which components and with which adjustments are needed to build a well-performing mRAG pipeline, that can be used as a strong baseline in future works. Our findings highlight that despite the availability of high-quality off-the-shelf multilingual retrievers and generators, task-specific prompt engineering is needed to enable generation in user languages. Moreover, current evaluation metrics need adjustments for multilingual setting, to account for variations in spelling named entities. The main limitations to be addressed in future works include frequent code-switching in non-Latin alphabet languages, occasional fluency errors, wrong reading of the provided documents, or irrelevant retrieval. We release the code for the resulting mRAG baseline pipeline at https://github.com/naver/bergen.
7/2/2024
🧪
A Multi-Source Retrieval Question Answering Framework Based on RAG
Ridong Wu, Shuhong Chen, Xiangbiao Su, Yuankai Zhu, Yifei Liao, Jianming Wu
0
0
With the rapid development of large-scale language models, Retrieval-Augmented Generation (RAG) has been widely adopted. However, existing RAG paradigms are inevitably influenced by erroneous retrieval information, thereby reducing the reliability and correctness of generated results. Therefore, to improve the relevance of retrieval information, this study proposes a method that replaces traditional retrievers with GPT-3.5, leveraging its vast corpus knowledge to generate retrieval information. We also propose a web retrieval based method to implement fine-grained knowledge retrieval, Utilizing the powerful reasoning capability of GPT-3.5 to realize semantic partitioning of problem.In order to mitigate the illusion of GPT retrieval and reduce noise in Web retrieval,we proposes a multi-source retrieval framework, named MSRAG, which combines GPT retrieval with web retrieval. Experiments on multiple knowledge-intensive QA datasets demonstrate that the proposed framework in this study performs better than existing RAG framework in enhancing the overall efficiency and accuracy of QA systems.
5/30/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
6/18/2024
🛸
Evaluating Retrieval Quality in Retrieval-Augmented Generation
Alireza Salemi, Hamed Zamani
0
0
Evaluating retrieval-augmented generation (RAG) presents challenges, particularly for retrieval models within these systems. Traditional end-to-end evaluation methods are computationally expensive. Furthermore, evaluation of the retrieval model's performance based on query-document relevance labels shows a small correlation with the RAG system's downstream performance. We propose a novel evaluation approach, eRAG, where each document in the retrieval list is individually utilized by the large language model within the RAG system. The output generated for each document is then evaluated based on the downstream task ground truth labels. In this manner, the downstream performance for each document serves as its relevance label. We employ various downstream task metrics to obtain document-level annotations and aggregate them using set-based or ranking metrics. Extensive experiments on a wide range of datasets demonstrate that eRAG achieves a higher correlation with downstream RAG performance compared to baseline methods, with improvements in Kendall's $tau$ correlation ranging from 0.168 to 0.494. Additionally, eRAG offers significant computational advantages, improving runtime and consuming up to 50 times less GPU memory than end-to-end evaluation.
4/23/2024