RC-Mixup: A Data Augmentation Strategy against Noisy Data for Regression Tasks

0
Sign in to get full access
Overview
- Introduces a new data augmentation technique called RC-Mixup to improve the performance of regression models on noisy datasets
- Proposes using a combination of Mixup and random convolution to create augmented samples that are more robust to noise
- Evaluates the method on various regression benchmarks and shows it outperforms existing data augmentation techniques
Plain English Explanation
RC-Mixup is a new way to improve the training of regression models when the data is noisy or has errors. Regression models are used to predict continuous values, like house prices or stock prices, based on input features.
The key idea behind RC-Mixup is to artificially create new training examples by combining ("mixing up") existing ones in a smart way. This helps the model learn to be more robust to the noise or errors in the original data. The technique uses a combination of two techniques:
-
Mixup: This involves taking two existing training examples and interpolating between them to create a new example. This helps the model learn smoother, more generalizable relationships.
-
Random Convolution: This applies a random mathematical transformation to the input features to create a new, perturbed example. This makes the model more resilient to small changes in the input.
By using both of these techniques together, RC-Mixup is able to generate augmented training examples that are more diverse and robust to noise compared to existing data augmentation methods like Mixup or CutMix.
The authors evaluate RC-Mixup on several standard regression benchmarks and show that it consistently outperforms these other techniques, especially when the training data is noisy. This suggests RC-Mixup could be a useful tool for improving the performance of regression models in real-world scenarios where data quality is a concern.
Technical Explanation
The key technical contribution of the RC-Mixup paper is the introduction of a new data augmentation strategy for regression tasks. Mixup is a popular data augmentation technique that works by linearly interpolating between pairs of input examples and their corresponding targets. However, Mixup alone may not be sufficient to handle noisy regression data.
The RC-Mixup method builds on Mixup by additionally applying a random convolution transformation to the input features before the mixing step. This random convolution introduces controlled perturbations to the inputs, making the model more robust to small changes in the data. The authors show that this combination of Mixup and random convolution is more effective at improving model performance on noisy regression benchmarks compared to using Mixup alone or other augmentation techniques like CutMix or DiffuseMix.
The paper includes extensive experiments on several regression datasets, including standard benchmarks like Boston Housing and Concrete Compressive Strength, as well as a real-world dataset for predicting building energy consumption. The results demonstrate that RC-Mixup consistently outperforms other data augmentation methods, especially when the training data is corrupted with varying levels of noise.
Critical Analysis
The RC-Mixup paper presents a promising new data augmentation technique for improving the robustness of regression models to noisy training data. The authors provide a clear and well-motivated rationale for the method, grounded in the limitations of existing approaches like standard Mixup.
One potential area for further research is exploring the optimal hyperparameters and configurations for the random convolution component of RC-Mixup. The authors note that the specific choices for the type and strength of the convolution transformation can have a significant impact on performance. Investigating more advanced techniques for adaptively selecting these hyperparameters could further enhance the method's effectiveness.
Additionally, while the experiments cover a diverse range of regression benchmarks, it would be valuable to evaluate RC-Mixup on an even broader set of real-world regression problems, including those with more complex data distributions and noise characteristics. This could provide additional insights into the strengths and limitations of the technique.
Overall, the RC-Mixup paper makes a compelling case for the benefits of combining Mixup with random convolution as a data augmentation strategy for regression tasks. The results suggest this approach could be a useful tool for practitioners working with noisy or imperfect training data, and the authors have made the code publicly available to encourage further exploration and refinement of the method.
Conclusion
The RC-Mixup paper introduces a new data augmentation technique that combines Mixup and random convolution to improve the performance of regression models on noisy datasets. By generating augmented training examples that are more robust to input perturbations, RC-Mixup is shown to outperform existing data augmentation methods across a range of regression benchmarks.
This research highlights the importance of developing specialized techniques to address the unique challenges of regression tasks, particularly when dealing with real-world data that may be imperfect or contaminated with noise. The RC-Mixup approach represents a promising step forward in this direction, and the authors' open-source implementation provides a valuable resource for the machine learning community to build upon.
As AI models become increasingly deployed in high-stakes applications, improving their robustness to noisy or imperfect data will be crucial. Techniques like RC-Mixup that enhance model performance in the face of data quality issues could have significant practical implications, enabling more reliable and trustworthy regression models across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RC-Mixup: A Data Augmentation Strategy against Noisy Data for Regression Tasks
Seong-Hyeon Hwang, Minsu Kim, Steven Euijong Whang
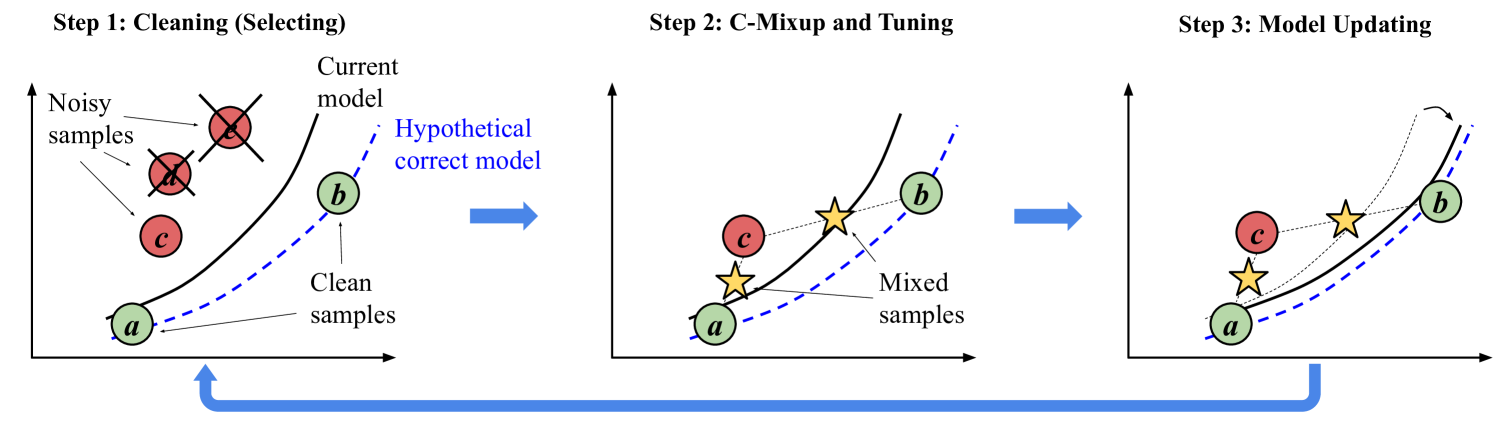
We study the problem of robust data augmentation for regression tasks in the presence of noisy data. Data augmentation is essential for generalizing deep learning models, but most of the techniques like the popular Mixup are primarily designed for classification tasks on image data. Recently, there are also Mixup techniques that are specialized to regression tasks like C-Mixup. In comparison to Mixup, which takes linear interpolations of pairs of samples, C-Mixup is more selective in which samples to mix based on their label distances for better regression performance. However, C-Mixup does not distinguish noisy versus clean samples, which can be problematic when mixing and lead to suboptimal model performance. At the same time, robust training has been heavily studied where the goal is to train accurate models against noisy data through multiple rounds of model training. We thus propose our data augmentation strategy RC-Mixup, which tightly integrates C-Mixup with multi-round robust training methods for a synergistic effect. In particular, C-Mixup improves robust training in identifying clean data, while robust training provides cleaner data to C-Mixup for it to perform better. A key advantage of RC-Mixup is that it is data-centric where the robust model training algorithm itself does not need to be modified, but can simply benefit from data mixing. We show in our experiments that RC-Mixup significantly outperforms C-Mixup and robust training baselines on noisy data benchmarks and can be integrated with various robust training methods.
Read more8/19/2024

0
A Survey on Mixup Augmentations and Beyond
Xin Jin, Hongyu Zhu, Siyuan Li, Zedong Wang, Zicheng Liu, Chang Yu, Huafeng Qin, Stan Z. Li
As Deep Neural Networks have achieved thrilling breakthroughs in the past decade, data augmentations have garnered increasing attention as regularization techniques when massive labeled data are unavailable. Among existing augmentations, Mixup and relevant data-mixing methods that convexly combine selected samples and the corresponding labels are widely adopted because they yield high performances by generating data-dependent virtual data while easily migrating to various domains. This survey presents a comprehensive review of foundational mixup methods and their applications. We first elaborate on the training pipeline with mixup augmentations as a unified framework containing modules. A reformulated framework could contain various mixup methods and give intuitive operational procedures. Then, we systematically investigate the applications of mixup augmentations on vision downstream tasks, various data modalities, and some analysis & theorems of mixup. Meanwhile, we conclude the current status and limitations of mixup research and point out further work for effective and efficient mixup augmentations. This survey can provide researchers with the current state of the art in mixup methods and provide some insights and guidance roles in the mixup arena. An online project with this survey is available at url{https://github.com/Westlake-AI/Awesome-Mixup}.
Read more9/10/2024

0
Mixup Augmentation with Multiple Interpolations
Lifeng Shen, Jincheng Yu, Hansi Yang, James T. Kwok
Mixup and its variants form a popular class of data augmentation techniques.Using a random sample pair, it generates a new sample by linear interpolation of the inputs and labels. However, generating only one single interpolation may limit its augmentation ability. In this paper, we propose a simple yet effective extension called multi-mix, which generates multiple interpolations from a sample pair. With an ordered sequence of generated samples, multi-mix can better guide the training process than standard mixup. Moreover, theoretically, this can also reduce the stochastic gradient variance. Extensive experiments on a number of synthetic and large-scale data sets demonstrate that multi-mix outperforms various mixup variants and non-mixup-based baselines in terms of generalization, robustness, and calibration.
Read more6/4/2024
📊
0
Tailoring Mixup to Data for Calibration
Quentin Bouniot, Pavlo Mozharovskyi, Florence d'Alch'e-Buc
Among all data augmentation techniques proposed so far, linear interpolation of training samples, also called Mixup, has found to be effective for a large panel of applications. Along with improved performance, Mixup is also a good technique for improving calibration and predictive uncertainty. However, mixing data carelessly can lead to manifold intrusion, i.e., conflicts between the synthetic labels assigned and the true label distributions, which can deteriorate calibration. In this work, we argue that the likelihood of manifold intrusion increases with the distance between data to mix. To this end, we propose to dynamically change the underlying distributions of interpolation coefficients depending on the similarity between samples to mix, and define a flexible framework to do so without losing in diversity. We provide extensive experiments for classification and regression tasks, showing that our proposed method improves performance and calibration of models, while being much more efficient. The code for our work is available at https://github.com/qbouniot/sim_kernel_mixup.
Read more6/12/2024