RDumb: A simple approach that questions our progress in continual test-time adaptation

0
🖼️
Sign in to get full access
Overview
- The paper examines "Test-Time Adaptation" (TTA), which allows pre-trained models to be updated and adapted to changing data distributions at deployment time.
- Previous work tested TTA algorithms for individual, fixed distribution shifts, but this paper investigates methods for continual adaptation over long timescales.
- The authors propose a new benchmark called "Continually Changing Corruptions" (CCC) to measure the long-term performance of TTA techniques.
- The results show that most state-of-the-art TTA methods eventually collapse and perform worse than a non-adapting model, even those specifically designed to be robust against performance collapse.
- The authors introduce a simple baseline called "RDumb" that periodically resets the model to its pre-trained state, and this performs better or on par with the previously proposed state-of-the-art methods.
Plain English Explanation
Machine learning models are often trained on specific datasets, but in the real world, the data they encounter can change over time. Test-Time Adaptation (TTA) is a technique that allows these pre-trained models to be updated and adapted to these changing data distributions when they are actually being used, rather than just during the initial training phase.
Previous research on TTA has looked at how these algorithms perform when faced with individual, one-time changes in the data. However, in the real world, data can continue to shift and evolve over long periods. This paper explores how well TTA techniques can handle this kind of ongoing, continual change in the data.
To test this, the researchers created a new benchmark called "Continually Changing Corruptions" (CCC). This benchmark simulates a scenario where the input data to the model is constantly being corrupted or altered in different ways over time.
When the researchers applied various state-of-the-art TTA methods to this benchmark, they found that most of them eventually stopped working well and actually performed worse than a model that didn't adapt at all. This was true even for methods that were specifically designed to be resistant to this kind of performance collapse.
As an alternative, the researchers introduced a very simple approach called "RDumb" that just periodically resets the model back to its original, pre-trained state. Surprisingly, this simple reset strategy performed as well as or better than the more complex, cutting-edge TTA methods on all the benchmarks tested.
Technical Explanation
The paper examines the performance of Test-Time Adaptation (TTA) techniques in the context of continually changing data distributions. Previous work on TTA has primarily focused on individual, fixed distribution shifts, but the authors argue that real-world deployment scenarios often involve more complex, ongoing changes in the data.
To study this, the authors propose a new benchmark called Continually Changing Corruptions (CCC). CCC simulates a scenario where the input data is subject to a sequence of different corruptions or perturbations over time, allowing the researchers to measure the asymptotic performance of TTA methods as the distribution continues to shift.
The authors evaluate several state-of-the-art TTA approaches on the CCC benchmark, including methods like Adaptive BatchNorm, Gradient Matching, and Meta-Curvature. Surprisingly, they find that all but one of these methods eventually collapse, performing worse than a non-adapting baseline model. This is true even for techniques that were specifically designed to be robust against performance degradation.
As an alternative, the authors introduce a simple baseline called "RDumb" that periodically resets the model back to its original pre-trained state. Remarkably, this simple reset strategy matches or outperforms the more complex, cutting-edge TTA methods across all the benchmarks tested.
Critical Analysis
The key finding of this paper - that most existing TTA methods ultimately fail in the face of continually changing data distributions - raises serious concerns about the practical viability of these approaches. The authors provide a thorough empirical evaluation using their CCC benchmark, which appears to be a well-designed test of adaptation capabilities.
That said, the paper does not delve deeply into the underlying reasons for the performance collapse of the TTA methods. More analysis of the failure modes and shortcomings of these approaches could help guide future research in this area.
Additionally, while the RDumb baseline is an intriguing simple solution, the authors don't explore its limitations or the scenarios where it may break down. Further investigation is needed to understand the strengths and weaknesses of this reset-based strategy compared to more sophisticated adaptation techniques.
Finally, the paper focuses solely on image classification tasks, so it's unclear how well these findings would generalize to other domains or problem settings. Extending the analysis to different types of machine learning models and applications could strengthen the claims and provide a more complete picture of the challenges facing continual adaptation.
Conclusion
This paper makes a significant contribution by exposing critical issues with current Test-Time Adaptation techniques. The authors demonstrate that state-of-the-art TTA methods struggle to maintain performance in the face of continually changing data distributions, often performing worse than a non-adapting baseline model.
The introduction of the simple RDumb reset strategy as a strong-performing alternative is an interesting finding that challenges the complexity of many existing TTA approaches. This work suggests that the field of continual adaptation may need to rethink its assumptions and explore fundamentally new techniques to address the challenges of real-world deployment scenarios.
Overall, this paper highlights the need for more robust and reliable adaptation mechanisms to support the deployment of machine learning models in dynamic, evolving environments. The insights and benchmarks provided here can help guide future research in this critical area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
RDumb: A simple approach that questions our progress in continual test-time adaptation
Ori Press, Steffen Schneider, Matthias Kummerer, Matthias Bethge
Test-Time Adaptation (TTA) allows to update pre-trained models to changing data distributions at deployment time. While early work tested these algorithms for individual fixed distribution shifts, recent work proposed and applied methods for continual adaptation over long timescales. To examine the reported progress in the field, we propose the Continually Changing Corruptions (CCC) benchmark to measure asymptotic performance of TTA techniques. We find that eventually all but one state-of-the-art methods collapse and perform worse than a non-adapting model, including models specifically proposed to be robust to performance collapse. In addition, we introduce a simple baseline, RDumb, that periodically resets the model to its pretrained state. RDumb performs better or on par with the previously proposed state-of-the-art in all considered benchmarks. Our results show that previous TTA approaches are neither effective at regularizing adaptation to avoid collapse nor able to outperform a simplistic resetting strategy.
Read more4/4/2024
0
UniTTA: Unified Benchmark and Versatile Framework Towards Realistic Test-Time Adaptation
Chaoqun Du, Yulin Wang, Jiayi Guo, Yizeng Han, Jie Zhou, Gao Huang
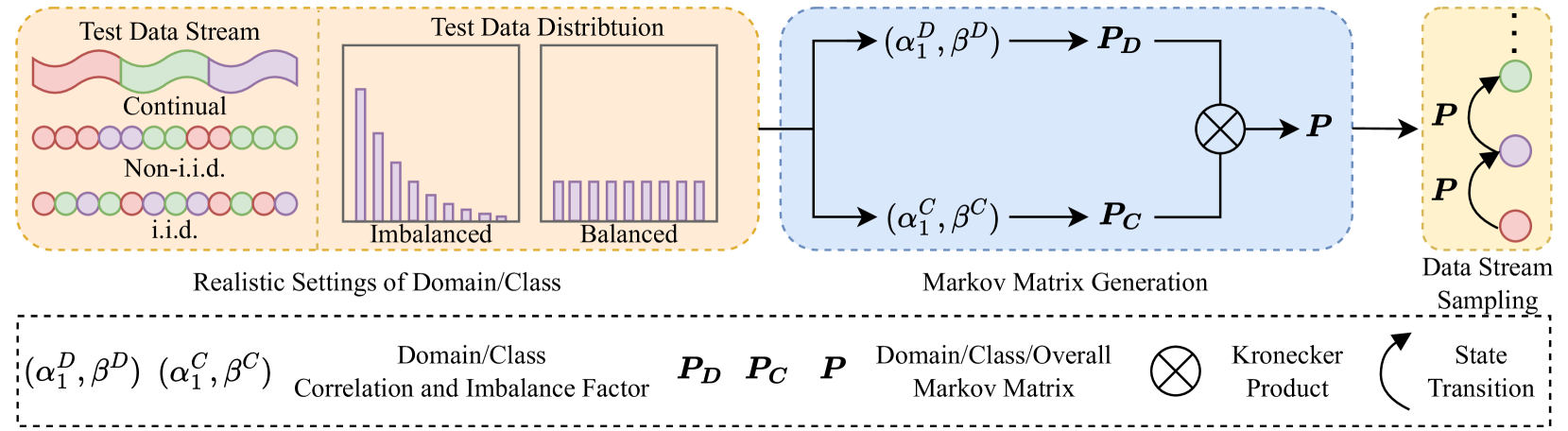
Test-Time Adaptation (TTA) aims to adapt pre-trained models to the target domain during testing. In reality, this adaptability can be influenced by multiple factors. Researchers have identified various challenging scenarios and developed diverse methods to address these challenges, such as dealing with continual domain shifts, mixed domains, and temporally correlated or imbalanced class distributions. Despite these efforts, a unified and comprehensive benchmark has yet to be established. To this end, we propose a Unified Test-Time Adaptation (UniTTA) benchmark, which is comprehensive and widely applicable. Each scenario within the benchmark is fully described by a Markov state transition matrix for sampling from the original dataset. The UniTTA benchmark considers both domain and class as two independent dimensions of data and addresses various combinations of imbalance/balance and i.i.d./non-i.i.d./continual conditions, covering a total of ( (2 times 3)^2 = 36 ) scenarios. It establishes a comprehensive evaluation benchmark for realistic TTA and provides a guideline for practitioners to select the most suitable TTA method. Alongside this benchmark, we propose a versatile UniTTA framework, which includes a Balanced Domain Normalization (BDN) layer and a COrrelated Feature Adaptation (COFA) method--designed to mitigate distribution gaps in domain and class, respectively. Extensive experiments demonstrate that our UniTTA framework excels within the UniTTA benchmark and achieves state-of-the-art performance on average. Our code is available at url{https://github.com/LeapLabTHU/UniTTA}.
Read more7/30/2024
0
Dynamic Domains, Dynamic Solutions: DPCore for Continual Test-Time Adaptation
Yunbei Zhang, Akshay Mehra, Jihun Hamm
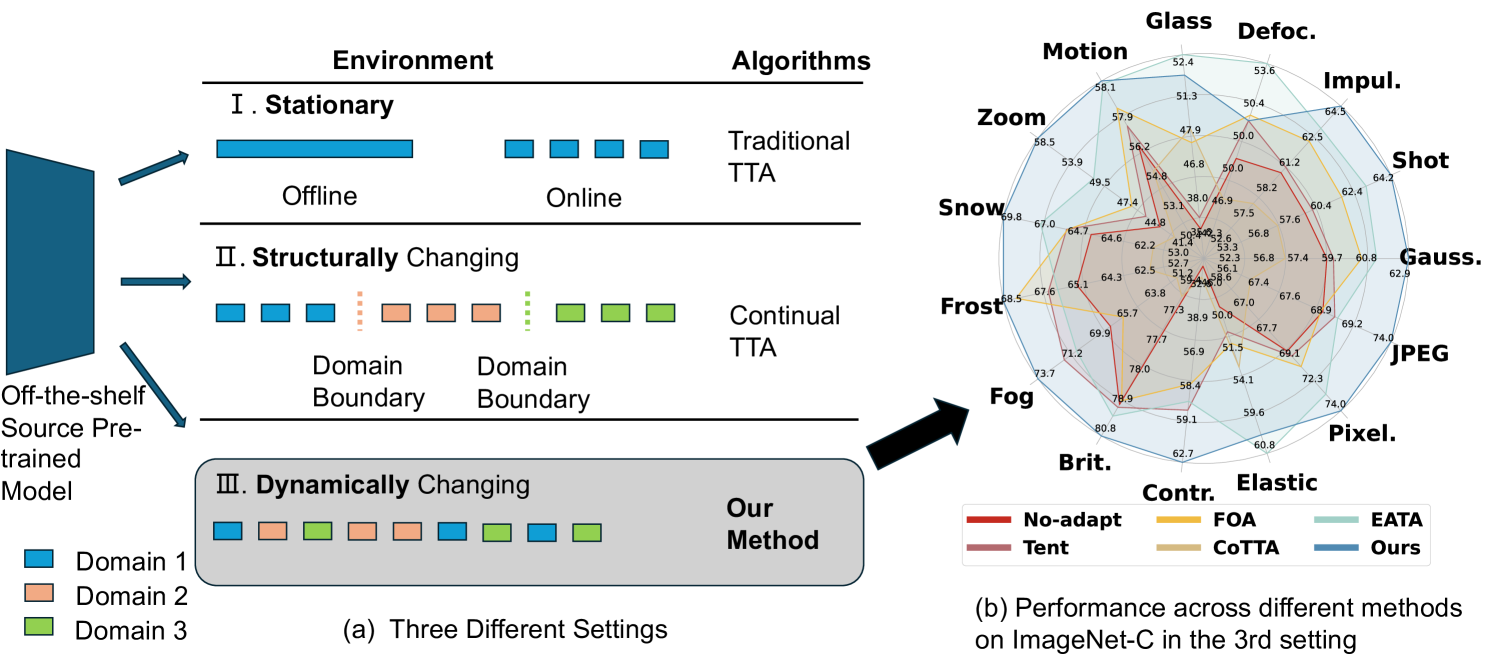
Continual Test-Time Adaptation (CTTA) seeks to adapt a source pre-trained model to continually changing, unlabeled target domains. Existing TTA methods are typically designed for environments where domain changes occur sequentially and can struggle in more dynamic scenarios, as illustrated in Figure ref{fig:settings}. Inspired by the principles of online K-Means, we introduce a novel approach to CTTA through visual prompting. We propose a emph{Dynamic Prompt Coreset} that not only preserves knowledge from previously visited domains but also accommodates learning from new potential domains. This is complemented by a distance-based emph{Weight Updating Mechanism} that ensures the coreset remains current and relevant. Our approach employs a fixed model architecture alongside the coreset and an innovative updating system to effectively mitigate challenges such as catastrophic forgetting and error accumulation. Extensive testing on four widely-used benchmarks demonstrates that our method consistently outperforms state-of-the-art alternatives in both classification and segmentation CTTA tasks across the structured and dynamic CTTA settings, with $99%$ fewer trainable parameters.
Read more8/27/2024
0
PALM: Pushing Adaptive Learning Rate Mechanisms for Continual Test-Time Adaptation
Sarthak Kumar Maharana, Baoming Zhang, Yunhui Guo
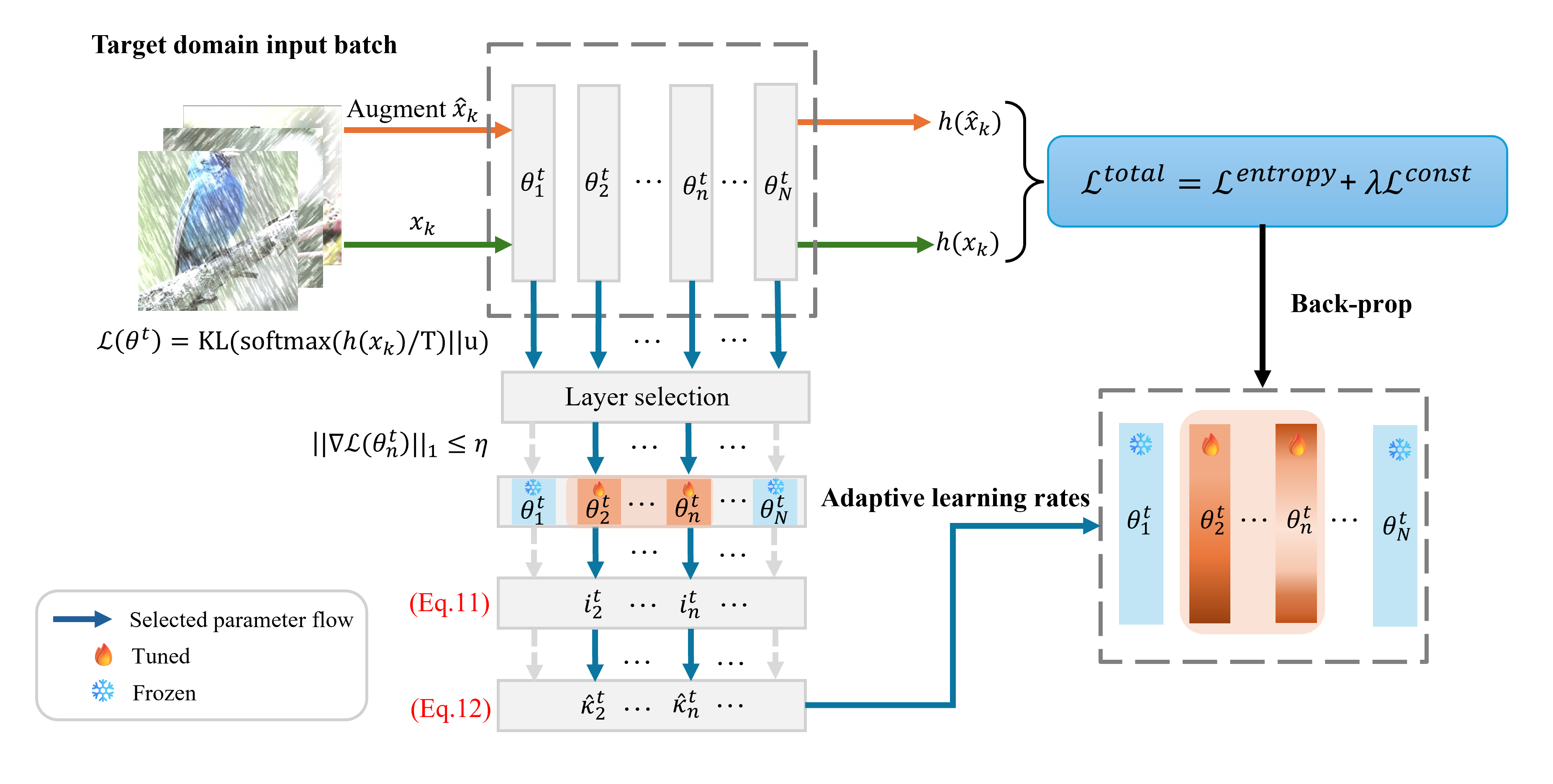
Real-world vision models in dynamic environments face rapid shifts in domain distributions, leading to decreased recognition performance. Using unlabeled test data, continual test-time adaptation (CTTA) directly adjusts a pre-trained source discriminative model to these changing domains. A highly effective CTTA method involves applying layer-wise adaptive learning rates for selectively adapting pre-trained layers. However, it suffers from the poor estimation of domain shift and the inaccuracies arising from the pseudo-labels. This work aims to overcome these limitations by identifying layers for adaptation via quantifying model prediction uncertainty without relying on pseudo-labels. We utilize the magnitude of gradients as a metric, calculated by backpropagating the KL divergence between the softmax output and a uniform distribution, to select layers for further adaptation. Subsequently, for the parameters exclusively belonging to these selected layers, with the remaining ones frozen, we evaluate their sensitivity to approximate the domain shift and adjust their learning rates accordingly. We conduct extensive image classification experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C, demonstrating the superior efficacy of our method compared to prior approaches.
Read more8/27/2024