Re2LLM: Reflective Reinforcement Large Language Model for Session-based Recommendation
2403.16427
0
0

Abstract
Large Language Models (LLMs) are emerging as promising approaches to enhance session-based recommendation (SBR), where both prompt-based and fine-tuning-based methods have been widely investigated to align LLMs with SBR. However, the former methods struggle with optimal prompts to elicit the correct reasoning of LLMs due to the lack of task-specific feedback, leading to unsatisfactory recommendations. Although the latter methods attempt to fine-tune LLMs with domain-specific knowledge, they face limitations such as high computational costs and reliance on open-source backbones. To address such issues, we propose a Reflective Reinforcement Large Language Model (Re2LLM) for SBR, guiding LLMs to focus on specialized knowledge essential for more accurate recommendations effectively and efficiently. In particular, we first design the Reflective Exploration Module to effectively extract knowledge that is readily understandable and digestible by LLMs. To be specific, we direct LLMs to examine recommendation errors through self-reflection and construct a knowledge base (KB) comprising hints capable of rectifying these errors. To efficiently elicit the correct reasoning of LLMs, we further devise the Reinforcement Utilization Module to train a lightweight retrieval agent. It learns to select hints from the constructed KB based on the task-specific feedback, where the hints can serve as guidance to help correct LLMs reasoning for better recommendations. Extensive experiments on multiple real-world datasets demonstrate that our method consistently outperforms state-of-the-art methods.
Create account to get full access
Overview
- Proposes a "Reflective Reinforcement Large Language Model" (Re2LLM) for session-based recommendation
- Uses self-reflection to improve recommendation performance
- Aims to address limitations of existing session-based recommender systems
Plain English Explanation
This paper introduces a new approach to session-based recommendation called "Reflective Reinforcement Large Language Model" (Re2LLM). Session-based recommendation is the challenge of providing personalized product or content recommendations to users based on their current browsing session, without relying on long-term user profiles or historical data.
The key innovation of Re2LLM is the incorporation of self-reflection. The model is designed to not only make recommendations, but also to evaluate its own recommendations and learn from the feedback. This self-reflection allows the model to continuously improve its performance over time, addressing some of the limitations of traditional session-based recommender systems.
The paper argues that existing session-based recommenders often struggle to capture the nuanced and dynamic preferences of users within a given browsing session. By enabling the model to reflect on its own choices and adapt accordingly, Re2LLM aims to provide more personalized and relevant recommendations that better match the user's evolving interests and intent.
Technical Explanation
The Re2LLM architecture builds upon large language models (LLMs), which have shown remarkable success in various natural language processing tasks. The researchers hypothesize that the innate ability of LLMs to understand and generate human-like text can be leveraged for session-based recommendation.
The core components of Re2LLM include:
- Session Encoder: Encodes the user's current browsing session into a contextual representation.
- Recommendation Generator: Uses the session context to generate personalized item recommendations.
- Reflection Module: Evaluates the generated recommendations and provides feedback to the model, enabling self-improvement.
During the recommendation process, the session encoder first captures the user's current browsing context. The recommendation generator then uses this information to propose relevant items. The reflection module then assesses the quality of the recommendations, providing a signal that the model can use to fine-tune its behavior and generate better recommendations in the future.
The authors conducted experiments on several benchmark session-based recommendation datasets, demonstrating that Re2LLM outperforms traditional session-based recommender systems in terms of both recommendation accuracy and diversity.
Critical Analysis
While the Re2LLM approach shows promise, the paper acknowledges several limitations and avenues for further research:
- The reflection module is fairly simplistic, relying on a binary feedback signal. More nuanced feedback mechanisms could potentially lead to even greater performance improvements.
- The experiments were conducted on relatively small-scale datasets, and it remains to be seen how well the model would scale to larger, real-world recommendation scenarios.
- The paper does not explore the potential privacy and ethical implications of using a large language model for personal recommendation, which is an important consideration for such systems.
Additionally, one could argue that the self-reflection mechanism, while innovative, adds significant complexity to the model. It remains to be seen whether the performance gains justify the increased computational and architectural complexity required to implement the reflection module.
Conclusion
The Re2LLM paper presents an intriguing approach to session-based recommendation that leverages the power of large language models and incorporates self-reflection to improve personalization. By enabling the model to learn from its own recommendations, the authors aim to address some of the key limitations of traditional session-based recommender systems.
While the results are promising, the research also highlights the need for further exploration of more sophisticated feedback mechanisms, scalability, and potential ethical considerations. As large language models continue to advance, the incorporation of self-reflection and other meta-cognitive capabilities may become an increasingly important frontier in the field of personalized recommendation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
Jianghao Lin, Rong Shan, Chenxu Zhu, Kounianhua Du, Bo Chen, Shigang Quan, Ruiming Tang, Yong Yu, Weinan Zhang
0
0
With large language models (LLMs) achieving remarkable breakthroughs in natural language processing (NLP) domains, LLM-enhanced recommender systems have received much attention and have been actively explored currently. In this paper, we focus on adapting and empowering a pure large language model for zero-shot and few-shot recommendation tasks. First and foremost, we identify and formulate the lifelong sequential behavior incomprehension problem for LLMs in recommendation domains, i.e., LLMs fail to extract useful information from a textual context of long user behavior sequence, even if the length of context is far from reaching the context limitation of LLMs. To address such an issue and improve the recommendation performance of LLMs, we propose a novel framework, namely Retrieval-enhanced Large Language models (ReLLa) for recommendation tasks in both zero-shot and few-shot settings. For zero-shot recommendation, we perform semantic user behavior retrieval (SUBR) to improve the data quality of testing samples, which greatly reduces the difficulty for LLMs to extract the essential knowledge from user behavior sequences. As for few-shot recommendation, we further design retrieval-enhanced instruction tuning (ReiT) by adopting SUBR as a data augmentation technique for training samples. Specifically, we develop a mixed training dataset consisting of both the original data samples and their retrieval-enhanced counterparts. We conduct extensive experiments on three real-world public datasets to demonstrate the superiority of ReLLa compared with existing baseline models, as well as its capability for lifelong sequential behavior comprehension. To be highlighted, with only less than 10% training samples, few-shot ReLLa can outperform traditional CTR models that are trained on the entire training set (e.g., DCNv2, DIN, SIM). The code is available url{https://github.com/LaVieEnRose365/ReLLa}.
6/26/2024
💬
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
0
0
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
6/19/2024
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024
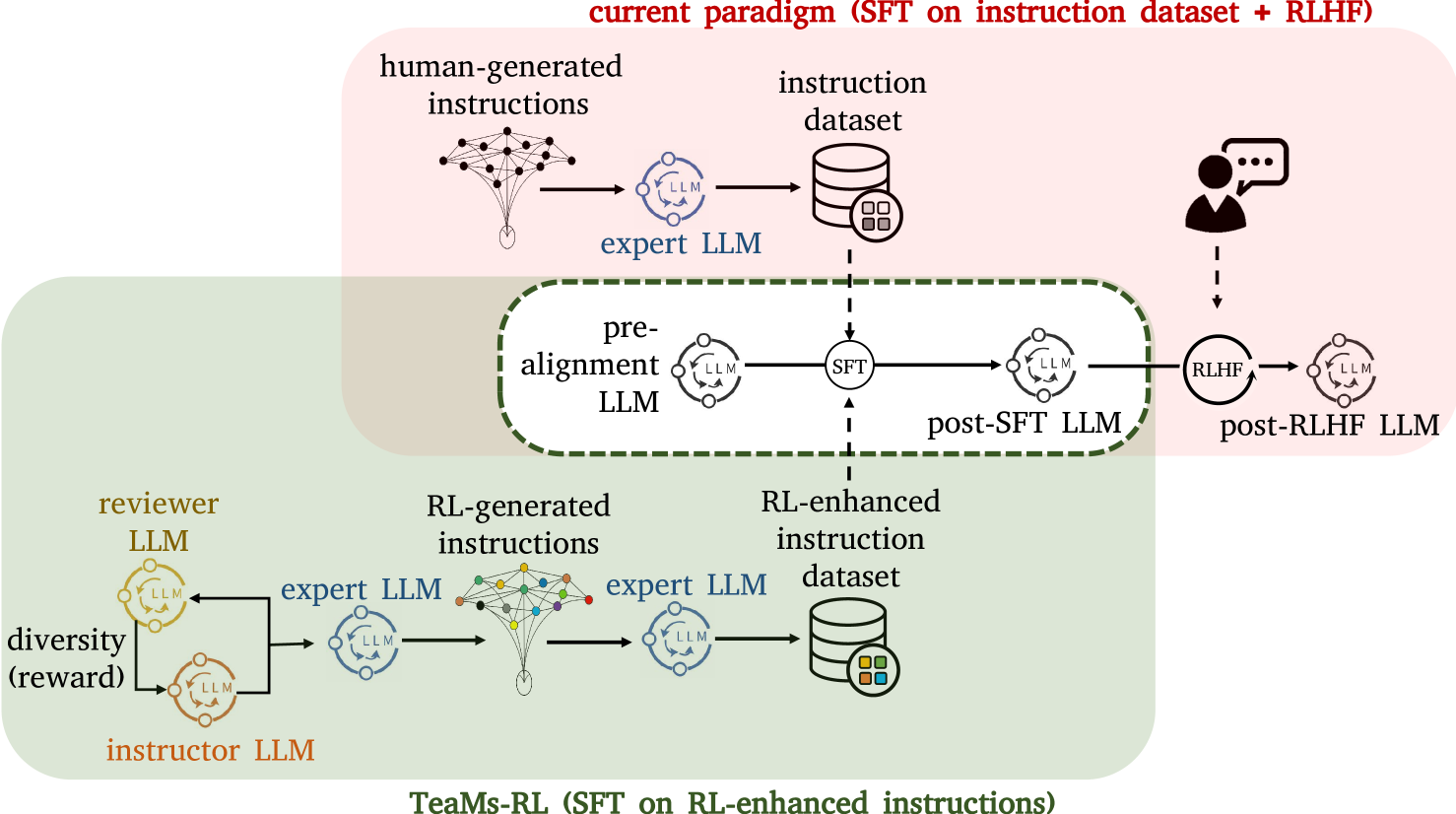
TeaMs-RL: Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning
Shangding Gu, Alois Knoll, Ming Jin
0
0
The development of Large Language Models (LLMs) often confronts challenges stemming from the heavy reliance on human annotators in the reinforcement learning with human feedback (RLHF) framework, or the frequent and costly external queries tied to the self-instruct paradigm. In this work, we pivot to Reinforcement Learning (RL) -- but with a twist. Diverging from the typical RLHF, which refines LLMs following instruction data training, we use RL to directly generate the foundational instruction dataset that alone suffices for fine-tuning. Our method, TeaMs-RL, uses a suite of textual operations and rules, prioritizing the diversification of training datasets. It facilitates the generation of high-quality data without excessive reliance on external advanced models, paving the way for a single fine-tuning step and negating the need for subsequent RLHF stages. Our findings highlight key advantages of our approach: reduced need for human involvement and fewer model queries (only $5.73%$ of WizardLM's total), along with enhanced capabilities of LLMs in crafting and comprehending complex instructions compared to strong baselines, and substantially improved model privacy protection.
5/7/2024