A Survey on Large Language Models for Recommendation
2305.19860
2
0
💬
Abstract
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
Create account to get full access
Overview
- This paper presents a comprehensive survey on the use of Large Language Models (LLMs) in the field of Recommendation Systems (RS).
- The authors categorize LLM-based recommendation systems into two main paradigms: Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec).
- The paper provides insights into the methodologies, techniques, and performance of existing LLM-based recommendation systems within each paradigm.
- The authors also identify key challenges and valuable findings to inspire researchers and practitioners in the field.
Plain English Explanation
Large Language Models (LLMs) are powerful AI tools that have been trained on vast amounts of data to understand and generate human language. These models have recently gained significant attention in the field of Recommendation Systems (RS), which aim to suggest relevant items (e.g., products, movies, or articles) to users based on their preferences and behaviors.
The key idea is to harness the capabilities of LLMs to enhance the quality of recommendations. LLMs can learn high-quality representations of textual features, such as item descriptions or user reviews, and leverage their extensive knowledge of the world to establish better connections between items and users.
The paper categorizes LLM-based recommendation systems into two main groups: Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec). The former uses LLMs to directly predict user preferences, while the latter employs LLMs to generate new recommendation candidates.
The paper provides a detailed review and analysis of existing systems within each paradigm, highlighting their methodologies, techniques, and performance. This information can help researchers and practitioners understand the current state of the field and identify promising directions for future work.
Technical Explanation
The paper begins by introducing the concept of LLMs and their potential to enhance Recommendation Systems (RS) through techniques like fine-tuning and prompt tuning.
The authors then present a taxonomy that categorizes LLM-based recommendation systems into two main paradigms:
- Discriminative LLM for Recommendation (DLLM4Rec): These models use LLMs to directly predict user preferences, often by fine-tuning the LLM on recommendation-specific data.
- Generative LLM for Recommendation (GLLM4Rec): These models employ LLMs to generate new recommendation candidates, such as by prompting the LLM to describe ideal items for a user.
The paper systematically reviews and analyzes the existing literature within each paradigm, providing insights into the methodologies, techniques, and performance of these systems. For example, the authors discuss how DLLM4Rec models leverage the rich semantic representations learned by LLMs to improve recommendation accuracy, while GLLM4Rec models can generate personalized recommendations by conditioning the LLM on user preferences.
The technical details covered in the paper include model architectures, training approaches, and evaluation metrics. The authors also highlight key challenges and valuable findings, such as the need for more efficient LLM models and the potential for LLMs to enhance the diversity and novelty of recommendations.
Critical Analysis
The paper provides a comprehensive and well-structured overview of the current state of LLM-based recommendation systems, which is a rapidly evolving field. The authors have done a commendable job in categorizing the existing approaches and systematically reviewing the literature within each paradigm.
One potential limitation of the paper is that it primarily focuses on the technical aspects of LLM-based recommendation systems, without delving deeply into the real-world implications and potential ethical concerns. For example, the paper does not discuss the potential biases that may be encoded in LLMs and how that could affect the fairness and inclusiveness of recommendation systems.
Additionally, the paper does not provide a critical assessment of the limitations and challenges faced by the current approaches. While the authors do highlight some key challenges, a more thorough discussion of the shortcomings and areas for further research would have been valuable.
Overall, this paper serves as an excellent resource for researchers and practitioners interested in understanding the role of LLMs in the recommendation systems domain. However, future work may benefit from a more holistic perspective that considers the broader societal implications of these technologies.
Conclusion
This survey paper provides a comprehensive overview of the use of Large Language Models (LLMs) in the field of Recommendation Systems (RS). The authors present a taxonomy that categorizes LLM-based recommendation systems into two main paradigms: Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec).
The paper offers a detailed review and analysis of existing systems within each paradigm, highlighting their methodologies, techniques, and performance. This information can help researchers and practitioners understand the current state of the field and identify promising directions for future work, such as the need for more efficient LLM models and the potential for LLMs to enhance the diversity and novelty of recommendations.
Overall, this survey paper provides a valuable resource for the research community, showcasing the significant potential of LLMs in improving the quality and effectiveness of recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
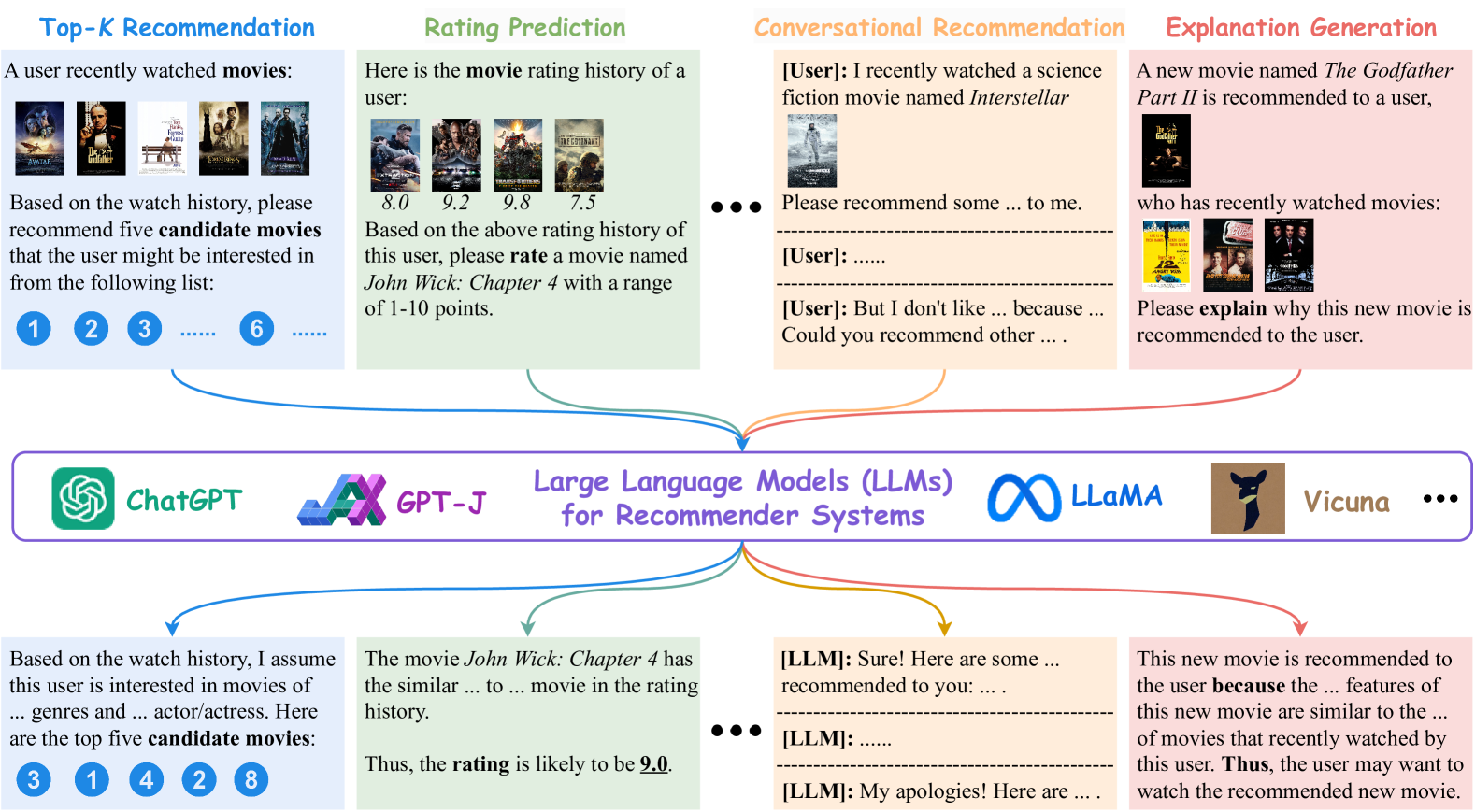
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024
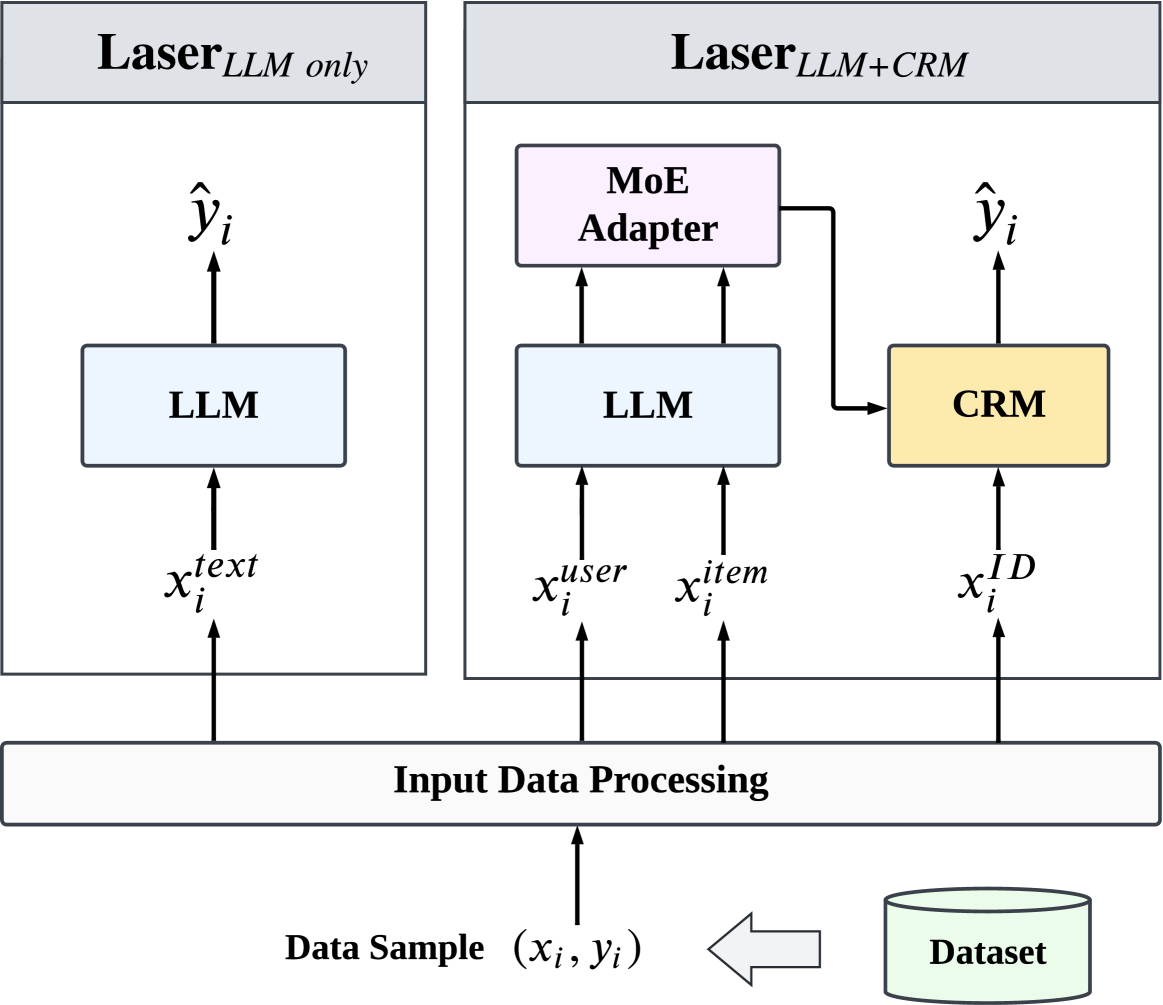
Large Language Models Make Sample-Efficient Recommender Systems
Jianghao Lin, Xinyi Dai, Rong Shan, Bo Chen, Ruiming Tang, Yong Yu, Weinan Zhang
0
0
Large language models (LLMs) have achieved remarkable progress in the field of natural language processing (NLP), demonstrating remarkable abilities in producing text that resembles human language for various tasks. This opens up new opportunities for employing them in recommender systems (RSs). In this paper, we specifically examine the sample efficiency of LLM-enhanced recommender systems, which pertains to the model's capacity to attain superior performance with a limited quantity of training data. Conventional recommendation models (CRMs) often need a large amount of training data because of the sparsity of features and interactions. Hence, we propose and verify our core viewpoint: Large Language Models Make Sample-Efficient Recommender Systems. We propose a simple yet effective framework (i.e., Laser) to validate the viewpoint from two aspects: (1) LLMs themselves are sample-efficient recommenders; and (2) LLMs, as feature generators and encoders, make CRMs more sample-efficient. Extensive experiments on two public datasets show that Laser requires only a small fraction of training samples to match or even surpass CRMs that are trained on the entire training set, demonstrating superior sample efficiency.
6/5/2024
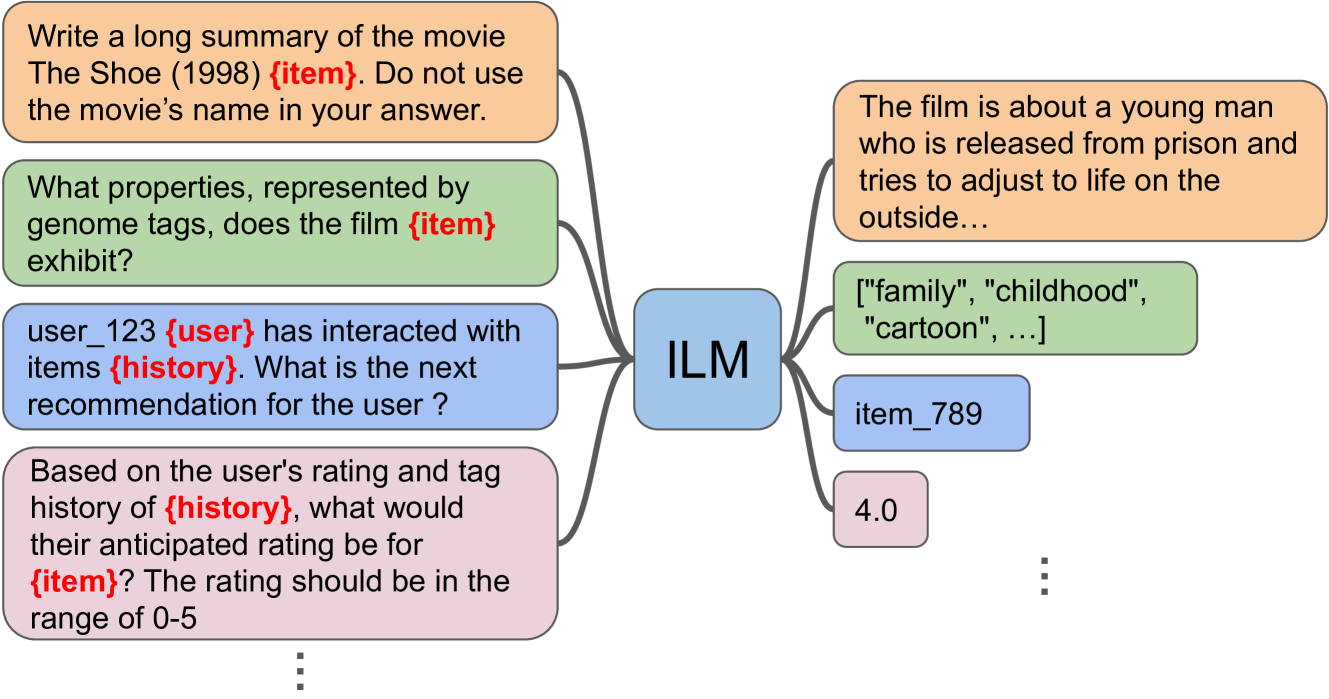
Item-Language Model for Conversational Recommendation
Li Yang, Anushya Subbiah, Hardik Patel, Judith Yue Li, Yanwei Song, Reza Mirghaderi, Vikram Aggarwal
0
0
Large-language Models (LLMs) have been extremely successful at tasks like complex dialogue understanding, reasoning and coding due to their emergent abilities. These emergent abilities have been extended with multi-modality to include image, audio, and video capabilities. Recommender systems, on the other hand, have been critical for information seeking and item discovery needs. Recently, there have been attempts to apply LLMs for recommendations. One difficulty of current attempts is that the underlying LLM is usually not trained on the recommender system data, which largely contains user interaction signals and is often not publicly available. Another difficulty is user interaction signals often have a different pattern from natural language text, and it is currently unclear if the LLM training setup can learn more non-trivial knowledge from interaction signals compared with traditional recommender system methods. Finally, it is difficult to train multiple LLMs for different use-cases, and to retain the original language and reasoning abilities when learning from recommender system data. To address these three limitations, we propose an Item-Language Model (ILM), which is composed of an item encoder to produce text-aligned item representations that encode user interaction signals, and a frozen LLM that can understand those item representations with preserved pretrained knowledge. We conduct extensive experiments which demonstrate both the importance of the language-alignment and of user interaction knowledge in the item encoder.
6/6/2024
💬
Efficient Large Language Models: A Survey
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang
0
0
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding and language generation, and thus have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. We will actively maintain the repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
5/24/2024