Realigned Softmax Warping for Deep Metric Learning

0

Sign in to get full access
Overview
- Deep metric learning is a technique used to train neural networks to learn effective feature representations for various tasks like image retrieval, face recognition, and clustering.
- The core idea is to learn an embedding space where similar items are close together and dissimilar items are far apart.
- This paper proposes a new loss function called "Realigned Softmax Warping" (RSW) that aims to improve the performance of deep metric learning.
Plain English Explanation
Deep metric learning is a way to train neural networks to learn useful features for tasks like finding similar images or recognizing faces. The key is to create an embedding space where similar things are close together and different things are far apart.
The paper introduces a new loss function called "Realigned Softmax Warping" (RSW) that aims to improve on existing deep metric learning methods. The [plain English] idea behind RSW is to rearrange the softmax function in a smart way to better separate similar and dissimilar items in the embedding space. This helps the network learn more meaningful features.
Technical Explanation
The paper proposes a new deep metric learning loss function called "Realigned Softmax Warping" (RSW). RSW builds on the popular softmax-based contrastive loss, but introduces several key modifications:
-
Realignment: RSW realigns the softmax logits to better separate similar and dissimilar pairs in the embedding space. This is done by introducing a learnable parameter that shifts the logits.
-
Warping: RSW applies a smooth warping function to the realigned softmax logits. This further enhances the separation between similar and dissimilar pairs.
-
Dual Formulation: RSW is formulated in both Euclidean and cosine distance forms, allowing the network to learn the most appropriate distance metric.
The authors show through extensive experiments on standard benchmarks that RSW outperforms previous state-of-the-art deep metric learning approaches. The improvements are especially significant for challenging scenarios with large intra-class variations or hard negative samples.
Critical Analysis
The paper provides a solid technical contribution to the field of deep metric learning. The key idea of realigning and warping the softmax logits is novel and well-motivated. The experimental results demonstrate the effectiveness of the proposed RSW loss across multiple datasets and tasks.
However, the paper does not discuss potential limitations or caveats of the RSW approach. For example, it is unclear how RSW would scale to extremely large-scale datasets or how sensitive the method is to hyperparameter tuning. Additionally, the paper does not explore potential applications beyond the standard image retrieval and classification benchmarks.
Further research could investigate the theoretical properties of the RSW loss, such as its optimization landscape and generalization behavior. Exploring the connections to other metric learning losses and the relationship to representation learning more broadly could also yield interesting insights.
Conclusion
This paper introduces a new deep metric learning loss function called "Realigned Softmax Warping" (RSW) that outperforms previous state-of-the-art approaches on standard benchmarks. The key innovation is a method to realign and warp the softmax logits, which helps the network learn more effective feature representations for tasks like image retrieval and face recognition.
While the technical contributions are solid, the paper could benefit from a more comprehensive discussion of the method's limitations and potential future research directions. Overall, the RSW loss represents an interesting and promising development in the field of deep metric learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Realigned Softmax Warping for Deep Metric Learning
Michael G. DeMoor, John J. Prevost
Deep Metric Learning (DML) loss functions traditionally aim to control the forces of separability and compactness within an embedding space so that the same class data points are pulled together and different class ones are pushed apart. Within the context of DML, a softmax operation will typically normalize distances into a probability for optimization, thus coupling all the push/pull forces together. This paper proposes a potential new class of loss functions that operate within a euclidean domain and aim to take full advantage of the coupled forces governing embedding space formation under a softmax. These forces of compactness and separability can be boosted or mitigated within controlled locations at will by using a warping function. In this work, we provide a simple example of a warping function and use it to achieve competitive, state-of-the-art results on various metric learning benchmarks.
Read more9/4/2024

0
Potential Field Based Deep Metric Learning
Shubhang Bhatnagar, Narendra Ahuja
Deep metric learning (DML) involves training a network to learn a semantically meaningful representation space. Many current approaches mine n-tuples of examples and model interactions within each tuplets. We present a novel, compositional DML model, inspired by electrostatic fields in physics that, instead of in tuples, represents the influence of each example (embedding) by a continuous potential field, and superposes the fields to obtain their combined global potential field. We use attractive/repulsive potential fields to represent interactions among embeddings from images of the same/different classes. Contrary to typical learning methods, where mutual influence of samples is proportional to their distance, we enforce reduction in such influence with distance, leading to a decaying field. We show that such decay helps improve performance on real world datasets with large intra-class variations and label noise. Like other proxy-based methods, we also use proxies to succinctly represent sub-populations of examples. We evaluate our method on three standard DML benchmarks- Cars-196, CUB-200-2011, and SOP datasets where it outperforms state-of-the-art baselines.
Read more5/30/2024
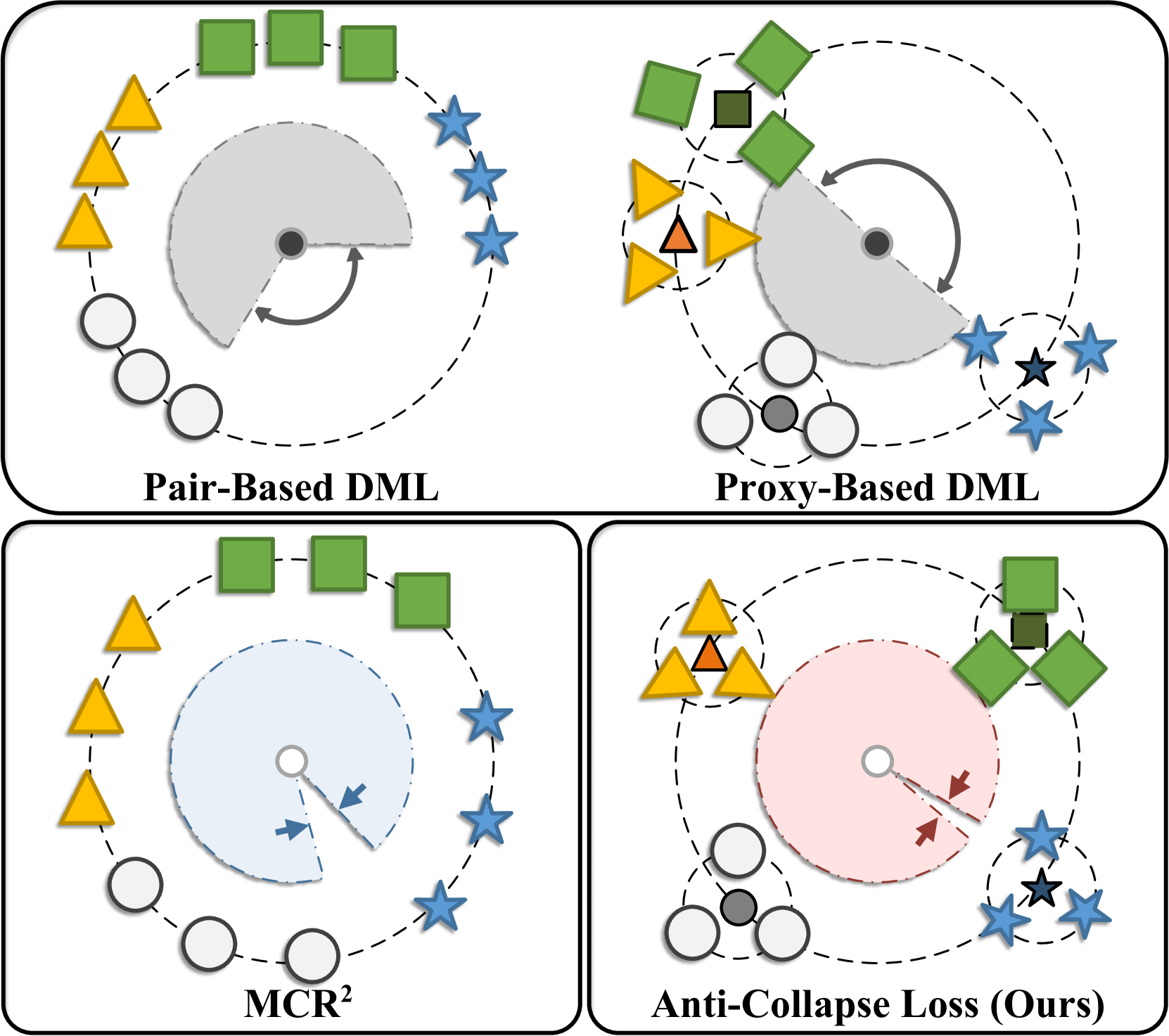
0
Anti-Collapse Loss for Deep Metric Learning Based on Coding Rate Metric
Xiruo Jiang, Yazhou Yao, Xili Dai, Fumin Shen, Xian-Sheng Hua, Heng-Tao Shen
Deep metric learning (DML) aims to learn a discriminative high-dimensional embedding space for downstream tasks like classification, clustering, and retrieval. Prior literature predominantly focuses on pair-based and proxy-based methods to maximize inter-class discrepancy and minimize intra-class diversity. However, these methods tend to suffer from the collapse of the embedding space due to their over-reliance on label information. This leads to sub-optimal feature representation and inferior model performance. To maintain the structure of embedding space and avoid feature collapse, we propose a novel loss function called Anti-Collapse Loss. Specifically, our proposed loss primarily draws inspiration from the principle of Maximal Coding Rate Reduction. It promotes the sparseness of feature clusters in the embedding space to prevent collapse by maximizing the average coding rate of sample features or class proxies. Moreover, we integrate our proposed loss with pair-based and proxy-based methods, resulting in notable performance improvement. Comprehensive experiments on benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art methods. Extensive ablation studies verify the effectiveness of our method in preventing embedding space collapse and promoting generalization performance.
Read more7/4/2024

0
Large Margin Discriminative Loss for Classification
Hai-Vy Nguyen, Fabrice Gamboa, Sixin Zhang, Reda Chhaibi, Serge Gratton, Thierry Giaccone
In this paper, we introduce a novel discriminative loss function with large margin in the context of Deep Learning. This loss boosts the discriminative power of neural nets, represented by intra-class compactness and inter-class separability. On the one hand, the class compactness is ensured by close distance of samples of the same class to each other. On the other hand, the inter-class separability is boosted by a margin loss that ensures the minimum distance of each class to its closest boundary. All the terms in our loss have an explicit meaning, giving a direct view of the feature space obtained. We analyze mathematically the relation between compactness and margin term, giving a guideline about the impact of the hyper-parameters on the learned features. Moreover, we also analyze properties of the gradient of the loss with respect to the parameters of the neural net. Based on this, we design a strategy called partial momentum updating that enjoys simultaneously stability and consistency in training. Furthermore, we also investigate generalization errors to have better theoretical insights. Our loss function systematically boosts the test accuracy of models compared to the standard softmax loss in our experiments.
Read more5/30/2024