Recall, Retrieve and Reason: Towards Better In-Context Relation Extraction
2404.17809
0
0

Abstract
Relation extraction (RE) aims to identify relations between entities mentioned in texts. Although large language models (LLMs) have demonstrated impressive in-context learning (ICL) abilities in various tasks, they still suffer from poor performances compared to most supervised fine-tuned RE methods. Utilizing ICL for RE with LLMs encounters two challenges: (1) retrieving good demonstrations from training examples, and (2) enabling LLMs exhibit strong ICL abilities in RE. On the one hand, retrieving good demonstrations is a non-trivial process in RE, which easily results in low relevance regarding entities and relations. On the other hand, ICL with an LLM achieves poor performance in RE while RE is different from language modeling in nature or the LLM is not large enough. In this work, we propose a novel recall-retrieve-reason RE framework that synergizes LLMs with retrieval corpora (training examples) to enable relevant retrieving and reliable in-context reasoning. Specifically, we distill the consistently ontological knowledge from training datasets to let LLMs generate relevant entity pairs grounded by retrieval corpora as valid queries. These entity pairs are then used to retrieve relevant training examples from the retrieval corpora as demonstrations for LLMs to conduct better ICL via instruction tuning. Extensive experiments on different LLMs and RE datasets demonstrate that our method generates relevant and valid entity pairs and boosts ICL abilities of LLMs, achieving competitive or new state-of-the-art performance on sentence-level RE compared to previous supervised fine-tuning methods and ICL-based methods.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper "Recall, Retrieve and Reason: Towards Better In-Context Relation Extraction" explores ways to improve the performance of large language models in extracting relevant information from text.
- The key ideas include using retrieval-augmented generation to enhance the model's understanding, and sequential retrieval and context learning to better leverage contextual information.
- The research also investigates how information re-organization and meta-context learning can boost the model's reasoning capabilities.
Plain English Explanation
The paper focuses on improving the ability of large language models to extract useful information from text. Large language models are powerful AI systems that can understand and generate human-like text, but they sometimes struggle to fully comprehend the context and relationships within a given passage.
The researchers explore several techniques to address this challenge. One key idea is using "retrieval-augmented generation," which means the model not only generates text but also retrieves relevant information from a database to enhance its understanding. The paper also discusses "sequential retrieval and context learning," where the model learns to better leverage the surrounding context when analyzing a piece of text.
Additionally, the researchers investigate how "information re-organization" and "meta-context learning" can help the model reason more effectively about the relationships and implications within the text. These approaches aim to improve the model's ability to make connections, draw inferences, and extract meaningful insights that go beyond simply identifying superficial patterns.
The goal of this research is to create more capable and versatile language models that can better understand and reason about the rich context and nuanced relationships present in natural language. This could lead to significant improvements in a wide range of applications, from information retrieval and question-answering to text summarization and automated analysis.
Technical Explanation
The paper proposes several key technical innovations to enhance the performance of large language models in relation extraction tasks.
First, the researchers introduce a "retrieval-augmented generation" approach, where the model not only generates text but also retrieves relevant information from a knowledge base to inform its outputs. This helps the model better understand the context and relationships within the input text.
Second, the paper explores "sequential retrieval and context learning," a technique that trains the model to learn effective strategies for leveraging the surrounding context when analyzing a piece of text. This allows the model to make more informed and contextually-aware decisions during the relation extraction process.
Additionally, the researchers investigate "information re-organization," a method of restructuring the input text to improve the model's reasoning capabilities. By reorganizing the information in a way that highlights key relationships and connections, the model can more effectively identify and extract relevant entities and their interactions.
Finally, the paper discusses "meta-context learning," a technique that enables the model to learn how to better utilize contextual information across multiple tasks and domains. This meta-learning approach helps the model develop more general and adaptable reasoning skills, rather than relying on task-specific heuristics.
Through a series of experiments, the researchers demonstrate that these techniques can lead to significant performance improvements on a range of relation extraction benchmarks, outperforming strong baseline models. The insights from this work have the potential to drive further advancements in natural language understanding and reasoning capabilities of large language models.
Critical Analysis
The paper presents a compelling and well-designed set of techniques for enhancing the in-context relation extraction capabilities of large language models. The researchers have clearly put a lot of thought and effort into addressing the shortcomings of existing approaches and developing innovative solutions.
One potential limitation of the research is the reliance on external knowledge bases and databases to support the retrieval-augmented generation process. While this approach has shown promising results, it may be challenging to scale and maintain these knowledge resources, particularly in domains with rapidly evolving information. The authors acknowledge this issue and suggest exploring alternative approaches, such as leveraging large language models themselves as knowledge sources.
Additionally, the paper focuses primarily on evaluating the proposed methods on standard benchmarks and datasets. While these provide a useful basis for comparison, it would be valuable to see how the techniques perform in more real-world, open-ended scenarios where the context and relationships may be more complex and ambiguous.
To further strengthen the impact of this research, it would be beneficial to explore the generalizability of the proposed methods. Investigating their applicability to a broader range of natural language processing tasks, such as question-answering, summarization, or dialogue systems, could help demonstrate the broader significance and versatility of the techniques.
Overall, the "Recall, Retrieve and Reason" paper represents a significant contribution to the field of natural language understanding and reasoning. The innovative approaches outlined in the study hold the potential to drive meaningful improvements in the capabilities of large language models, with a wide range of practical applications and societal benefits.
Conclusion
The "Recall, Retrieve and Reason" paper presents a compelling set of techniques for enhancing the in-context relation extraction capabilities of large language models. The key ideas, including retrieval-augmented generation, sequential retrieval and context learning, information re-organization, and meta-context learning, demonstrate the potential to significantly improve the models' ability to understand and reason about the rich context and nuanced relationships present in natural language.
The researchers have designed a well-structured study and provide empirical evidence of the effectiveness of their proposed methods on standard benchmarks. While the reliance on external knowledge sources and the focus on specific evaluation tasks present some limitations, the overall contribution of this work is substantial and holds promise for driving further advancements in natural language understanding and reasoning.
By addressing the shortcomings of existing approaches and introducing innovative solutions, the "Recall, Retrieve and Reason" paper represents an important step forward in the ongoing quest to develop more capable and versatile language models. The insights and techniques outlined in this study could have far-reaching implications, potentially leading to significant improvements in a wide range of real-world applications that rely on natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
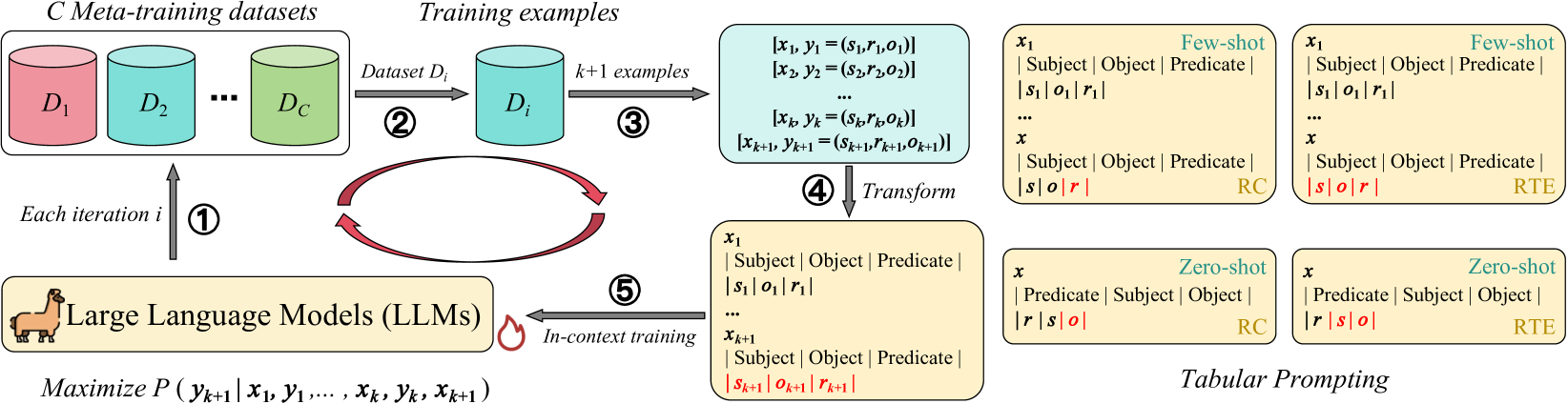
Meta In-Context Learning Makes Large Language Models Better Zero and Few-Shot Relation Extractors
Guozheng Li, Peng Wang, Jiajun Liu, Yikai Guo, Ke Ji, Ziyu Shang, Zijie Xu
0
0
Relation extraction (RE) is an important task that aims to identify the relationships between entities in texts. While large language models (LLMs) have revealed remarkable in-context learning (ICL) capability for general zero and few-shot learning, recent studies indicate that current LLMs still struggle with zero and few-shot RE. Previous studies are mainly dedicated to design prompt formats and select good examples for improving ICL-based RE. Although both factors are vital for ICL, if one can fundamentally boost the ICL capability of LLMs in RE, the zero and few-shot RE performance via ICL would be significantly improved. To this end, we introduce textsc{Micre} (textbf{M}eta textbf{I}n-textbf{C}ontext learning of LLMs for textbf{R}elation textbf{E}xtraction), a new meta-training framework for zero and few-shot RE where an LLM is tuned to do ICL on a diverse collection of RE datasets (i.e., learning to learn in context for RE). Through meta-training, the model becomes more effectively to learn a new RE task in context by conditioning on a few training examples with no parameter updates or task-specific templates at inference time, enabling better zero and few-shot task generalization. We experiment textsc{Micre} on various LLMs with different model scales and 12 public RE datasets, and then evaluate it on unseen RE benchmarks under zero and few-shot settings. textsc{Micre} delivers comparable or superior performance compared to a range of baselines including supervised fine-tuning and typical in-context learning methods. We find that the gains are particular significant for larger model scales, and using a diverse set of the meta-training RE datasets is key to improvements. Empirically, we show that textsc{Micre} can transfer the relation semantic knowledge via relation label name during inference on target RE datasets.
4/30/2024

Retrieval-Augmented Generation-based Relation Extraction
Sefika Efeoglu, Adrian Paschke
0
0
Information Extraction (IE) is a transformative process that converts unstructured text data into a structured format by employing entity and relation extraction (RE) methodologies. The identification of the relation between a pair of entities plays a crucial role within this framework. Despite the existence of various techniques for relation extraction, their efficacy heavily relies on access to labeled data and substantial computational resources. In addressing these challenges, Large Language Models (LLMs) emerge as promising solutions; however, they might return hallucinating responses due to their own training data. To overcome these limitations, Retrieved-Augmented Generation-based Relation Extraction (RAG4RE) in this work is proposed, offering a pathway to enhance the performance of relation extraction tasks. This work evaluated the effectiveness of our RAG4RE approach utilizing different LLMs. Through the utilization of established benchmarks, such as TACRED, TACREV, Re-TACRED, and SemEval RE datasets, our aim is to comprehensively evaluate the efficacy of our RAG4RE approach. In particularly, we leverage prominent LLMs including Flan T5, Llama2, and Mistral in our investigation. The results of our study demonstrate that our RAG4RE approach surpasses performance of traditional RE approaches based solely on LLMs, particularly evident in the TACRED dataset and its variations. Furthermore, our approach exhibits remarkable performance compared to previous RE methodologies across both TACRED and TACREV datasets, underscoring its efficacy and potential for advancing RE tasks in natural language processing.
4/23/2024
📶
RetICL: Sequential Retrieval of In-Context Examples with Reinforcement Learning
Alexander Scarlatos, Andrew Lan
0
0
Recent developments in large pre-trained language models have enabled unprecedented performance on a variety of downstream tasks. Achieving best performance with these models often leverages in-context learning, where a model performs a (possibly new) task given one or more examples. However, recent work has shown that the choice of examples can have a large impact on task performance and that finding an optimal set of examples is non-trivial. While there are many existing methods for selecting in-context examples, they generally score examples independently, ignoring the dependency between them and the order in which they are provided to the model. In this work, we propose Retrieval for In-Context Learning (RetICL), a learnable method for modeling and optimally selecting examples sequentially for in-context learning. We frame the problem of sequential example selection as a Markov decision process and train an example retriever using reinforcement learning. We evaluate RetICL on math word problem solving and scientific question answering tasks and show that it consistently outperforms or matches heuristic and learnable baselines. We also use case studies to show that RetICL implicitly learns representations of problem solving strategies.
4/17/2024
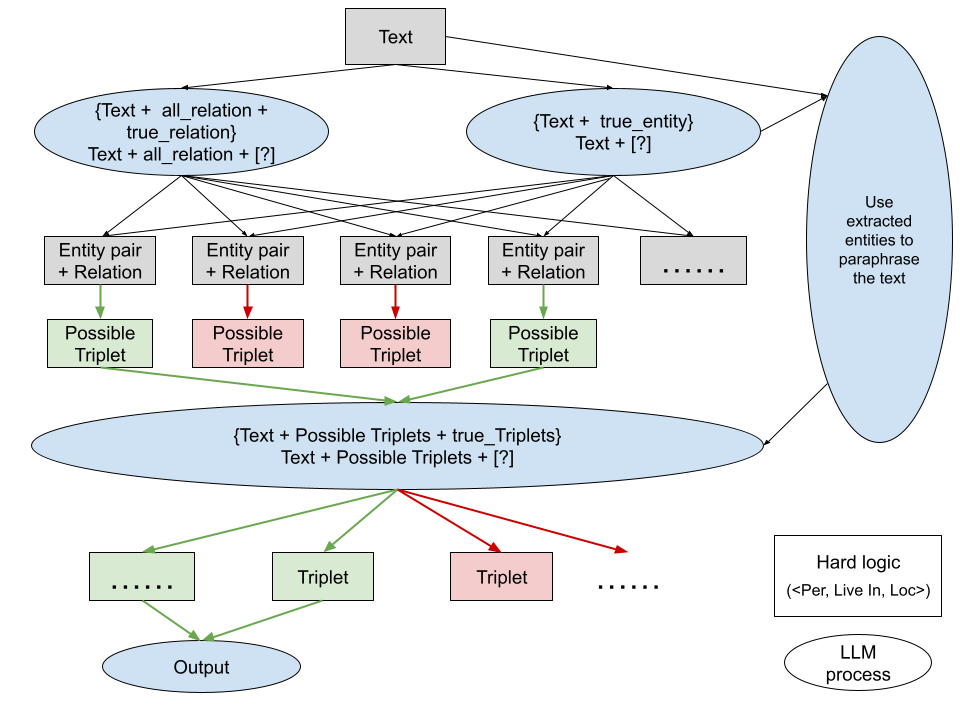
Graphical Reasoning: LLM-based Semi-Open Relation Extraction
Yicheng Tao, Yiqun Wang, Longju Bai
0
0
This paper presents a comprehensive exploration of relation extraction utilizing advanced language models, specifically Chain of Thought (CoT) and Graphical Reasoning (GRE) techniques. We demonstrate how leveraging in-context learning with GPT-3.5 can significantly enhance the extraction process, particularly through detailed example-based reasoning. Additionally, we introduce a novel graphical reasoning approach that dissects relation extraction into sequential sub-tasks, improving precision and adaptability in processing complex relational data. Our experiments, conducted on multiple datasets, including manually annotated data, show considerable improvements in performance metrics, underscoring the effectiveness of our methodologies.
5/2/2024