RetICL: Sequential Retrieval of In-Context Examples with Reinforcement Learning
2305.14502
0
0
📶
Abstract
Recent developments in large pre-trained language models have enabled unprecedented performance on a variety of downstream tasks. Achieving best performance with these models often leverages in-context learning, where a model performs a (possibly new) task given one or more examples. However, recent work has shown that the choice of examples can have a large impact on task performance and that finding an optimal set of examples is non-trivial. While there are many existing methods for selecting in-context examples, they generally score examples independently, ignoring the dependency between them and the order in which they are provided to the model. In this work, we propose Retrieval for In-Context Learning (RetICL), a learnable method for modeling and optimally selecting examples sequentially for in-context learning. We frame the problem of sequential example selection as a Markov decision process and train an example retriever using reinforcement learning. We evaluate RetICL on math word problem solving and scientific question answering tasks and show that it consistently outperforms or matches heuristic and learnable baselines. We also use case studies to show that RetICL implicitly learns representations of problem solving strategies.
Create account to get full access
Overview
- Recent advancements in large language models have enabled impressive performance on various tasks.
- In-context learning, where a model performs a task given one or more examples, is often used to achieve these best results.
- However, the choice of examples can significantly impact task performance, and finding an optimal set of examples is challenging.
- Existing methods for selecting in-context examples generally score them independently, ignoring the dependencies between them and the order in which they are provided.
Plain English Explanation
Large language models, such as GPT-3, have made significant progress in recent years, allowing them to perform remarkably well on a wide range of tasks. One technique that is often used to get the best results from these models is called in-context learning. In this approach, the model is given one or more examples of how to complete a task, and then it uses that information to perform the task itself.
However, the researchers have found that the specific examples provided to the model can have a big impact on its performance. Finding the best set of examples is not a simple task, as the examples can influence each other and the order in which they are presented also matters. Most existing methods for selecting examples treat them independently, without considering these important relationships.
In this paper, the researchers propose a new approach called Retrieval for In-Context Learning (RetICL), which uses reinforcement learning to learn how to select the best sequence of examples for a given task. By modeling the problem as a Markov decision process, RetICL can learn to optimize the selection of examples in a way that takes into account their interdependencies and the order in which they are presented.
The researchers evaluate RetICL on two tasks: solving math word problems and answering scientific questions. They show that RetICL consistently outperforms or matches other baseline methods for selecting in-context examples. Additionally, they use case studies to demonstrate that RetICL implicitly learns representations of problem-solving strategies, which can provide valuable insights into how the model is approaching the tasks.
Technical Explanation
The researchers propose a new method called Retrieval for In-Context Learning (RetICL), which uses reinforcement learning to learn how to sequentially select the best set of in-context examples for a given task. They frame the problem of example selection as a Markov decision process, where the agent (the example retriever) must choose the next example to provide to the language model based on the current state of the task and the previous examples.
The RetICL model consists of two key components: a task encoder, which encodes the current state of the task, and an example retriever, which uses the task encoding to select the next example to provide to the language model. The example retriever is trained using reinforcement learning, with the goal of maximizing the language model's performance on the target task.
The researchers evaluate RetICL on two tasks: math word problem solving and scientific question answering. They compare the performance of RetICL to several baseline methods for example selection, including heuristic approaches and other learnable methods. The results show that RetICL consistently outperforms or matches the performance of these baselines, demonstrating the effectiveness of its sequential example selection approach.
Additionally, the researchers use case studies to analyze the behavior of RetICL and show that it implicitly learns representations of problem-solving strategies. By examining the examples selected by RetICL, they can gain insights into how the language model is approaching the tasks and the underlying reasoning processes it is employing.
Critical Analysis
The researchers have presented a novel and promising approach to the problem of in-context learning with large language models. By explicitly modeling the interdependencies between examples and the order in which they are presented, RetICL represents a significant advance over existing methods for example selection.
However, the paper does not address several important limitations and potential issues with the proposed approach. For instance, the evaluation is limited to only two tasks, and it is unclear how well RetICL would generalize to a wider range of tasks or domains. Additionally, the computational overhead of the reinforcement learning-based training process may make RetICL impractical for real-world deployment in some scenarios.
Furthermore, the researchers do not provide a detailed analysis of the learned representations and problem-solving strategies, which could be a valuable contribution to the understanding of how large language models approach such tasks. More in-depth exploration of these aspects could yield important insights for the field.
Overall, the work presented in this paper is a significant step forward in the quest to optimize in-context learning with large language models. However, further research and validation will be necessary to fully understand the strengths, limitations, and potential real-world applications of the RetICL approach.
Conclusion
The paper introduces a novel method called Retrieval for In-Context Learning (RetICL), which uses reinforcement learning to learn how to sequentially select the best set of in-context examples for a given task. This approach addresses a key limitation of existing methods by explicitly modeling the interdependencies between examples and the order in which they are presented.
The researchers demonstrate that RetICL consistently outperforms or matches the performance of other baseline methods on two tasks: math word problem solving and scientific question answering. Additionally, they use case studies to show that RetICL implicitly learns representations of problem-solving strategies, which could provide valuable insights into the decision-making processes of large language models.
While the paper represents an important advance in the field of in-context learning, it also highlights the need for further research to address the limitations of the proposed approach, such as its generalizability and computational efficiency. By continuing to explore and refine methods like RetICL, researchers can help unlock the full potential of large language models and enable their widespread deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning to Retrieve Iteratively for In-Context Learning
Yunmo Chen, Tongfei Chen, Harsh Jhamtani, Patrick Xia, Richard Shin, Jason Eisner, Benjamin Van Durme
0
0
We introduce iterative retrieval, a novel framework that empowers retrievers to make iterative decisions through policy optimization. Finding an optimal portfolio of retrieved items is a combinatorial optimization problem, generally considered NP-hard. This approach provides a learned approximation to such a solution, meeting specific task requirements under a given family of large language models (LLMs). We propose a training procedure based on reinforcement learning, incorporating feedback from LLMs. We instantiate an iterative retriever for composing in-context learning (ICL) exemplars and apply it to various semantic parsing tasks that demand synthesized programs as outputs. By adding only 4M additional parameters for state encoding, we convert an off-the-shelf dense retriever into a stateful iterative retriever, outperforming previous methods in selecting ICL exemplars on semantic parsing datasets such as CalFlow, TreeDST, and MTOP. Additionally, the trained iterative retriever generalizes across different inference LLMs beyond the one used during training.
6/24/2024
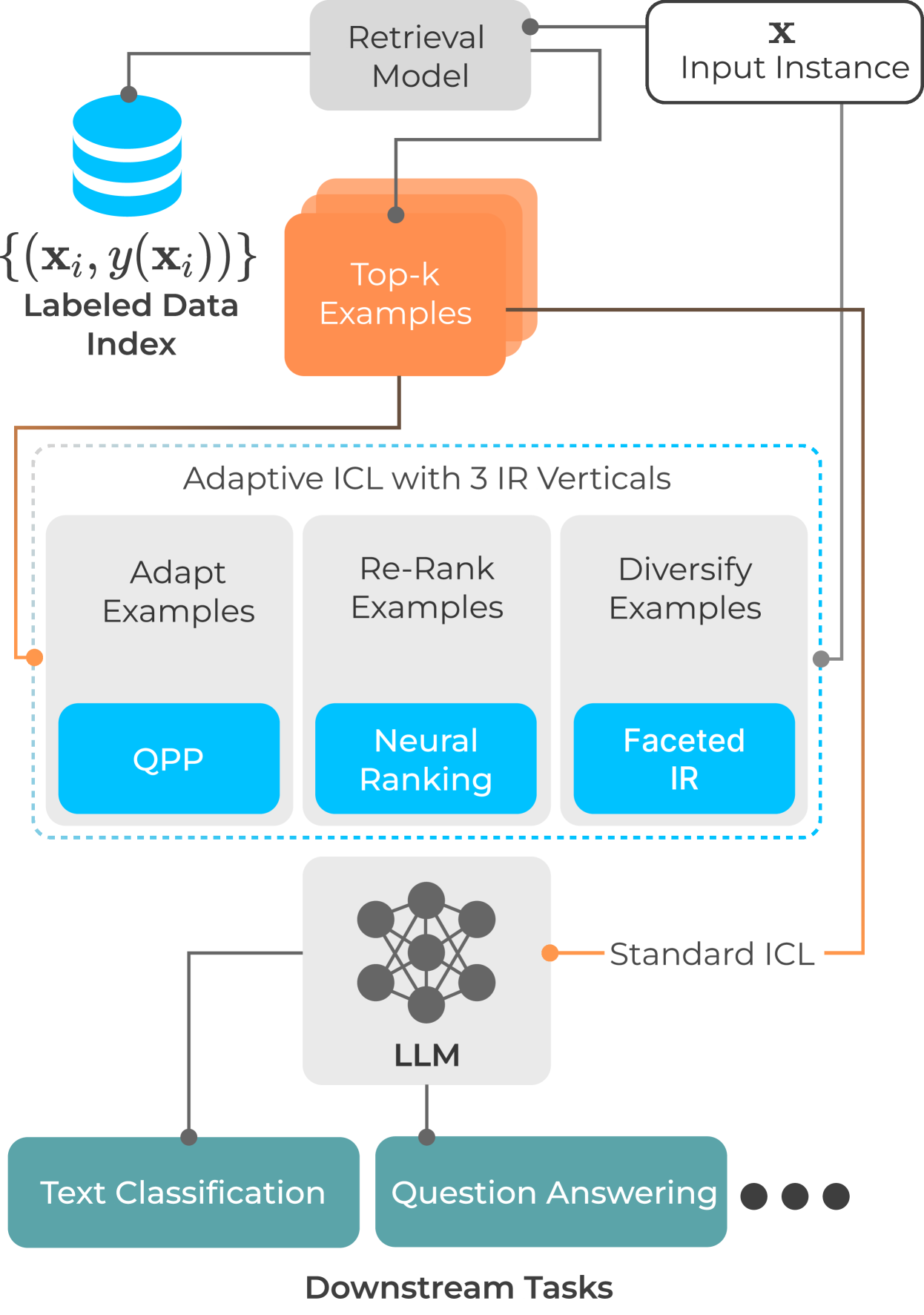
In-Context Learning or: How I learned to stop worrying and love Applied Information Retrieval
Andrew Parry, Debasis Ganguly, Manish Chandra
0
0
With the increasing ability of large language models (LLMs), in-context learning (ICL) has evolved as a new paradigm for natural language processing (NLP), where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
5/3/2024

Evaluating the Adversarial Robustness of Retrieval-Based In-Context Learning for Large Language Models
Simon Chi Lok Yu, Jie He, Pasquale Minervini, Jeff Z. Pan
0
0
With the emergence of large language models, such as LLaMA and OpenAI GPT-3, In-Context Learning (ICL) gained significant attention due to its effectiveness and efficiency. However, ICL is very sensitive to the choice, order, and verbaliser used to encode the demonstrations in the prompt. Retrieval-Augmented ICL methods try to address this problem by leveraging retrievers to extract semantically related examples as demonstrations. While this approach yields more accurate results, its robustness against various types of adversarial attacks, including perturbations on test samples, demonstrations, and retrieved data, remains under-explored. Our study reveals that retrieval-augmented models can enhance robustness against test sample attacks, outperforming vanilla ICL with a 4.87% reduction in Attack Success Rate (ASR); however, they exhibit overconfidence in the demonstrations, leading to a 2% increase in ASR for demonstration attacks. Adversarial training can help improve the robustness of ICL methods to adversarial attacks; however, such a training scheme can be too costly in the context of LLMs. As an alternative, we introduce an effective training-free adversarial defence method, DARD, which enriches the example pool with those attacked samples. We show that DARD yields improvements in performance and robustness, achieving a 15% reduction in ASR over the baselines. Code and data are released to encourage further research: https://github.com/simonucl/adv-retreival-icl
5/28/2024
⛏️
In-Context Learning with Iterative Demonstration Selection
Chengwei Qin, Aston Zhang, Chen Chen, Anirudh Dagar, Wenming Ye
0
0
Spurred by advancements in scale, large language models (LLMs) have demonstrated strong few-shot learning ability via in-context learning (ICL). However, the performance of ICL has been shown to be highly sensitive to the selection of few-shot demonstrations. Selecting the most suitable examples as context remains an ongoing challenge and an open problem. Existing literature has highlighted the importance of selecting examples that are diverse or semantically similar to the test sample while ignoring the fact that the optimal selection dimension, i.e., diversity or similarity, is task-specific. Based on how the test sample is answered, we propose Iterative Demonstration Selection (IDS) to leverage the merits of both dimensions. Using zero-shot chain-of-thought reasoning (Zero-shot-CoT), IDS iteratively selects examples that are diverse but still strongly correlated with the test sample as ICL demonstrations. Specifically, IDS applies Zero-shot-CoT to the test sample before demonstration selection. The output reasoning path is then used to choose demonstrations that are prepended to the test sample for inference. The generated answer is followed by its corresponding reasoning path for extracting a new set of demonstrations in the next iteration. After several iterations, IDS adopts majority voting to obtain the final result. Through extensive experiments on tasks including reasoning, question answering, and topic classification, we demonstrate that IDS can consistently outperform existing ICL demonstration selection methods.
6/26/2024