Reconstruction of partially occluded objects with a physics-driven self-training neural network

0

Sign in to get full access
Overview
- This paper presents a physics-driven self-training neural network for reconstructing partially occluded objects.
- The method uses physical simulations to create a large dataset of partially occluded objects, which is then used to train the neural network.
- The network learns to predict the complete shape of an object from its partially occluded observation, leveraging the underlying physics of the scene.
Plain English Explanation
The paper describes a new way to reconstruct the complete 3D shape of an object, even if parts of it are hidden or blocked from view. This is a common problem in many real-world applications, such as autonomous vehicles needing to understand the full shape of nearby objects.
The key innovation is using [object Object]. The researchers first create a large dataset of partially occluded objects by simulating physical scenarios where objects are blocked by other objects. They then use this dataset to train a neural network to predict the complete 3D shape of an object, even when only a partial view is available.
The neural network learns to leverage the underlying physics of the scene - for example, understanding that a partially hidden object must have a certain shape and structure based on the visible portions. This allows it to "fill in the gaps" and reconstruct the full 3D shape, something that would be very difficult for a human to do.
Technical Explanation
The paper introduces a [object Object] for reconstructing partially occluded 3D objects. The key steps are:
-
Dataset Generation: The researchers use physics simulations to create a large dataset of partially occluded 3D objects. This involves simulating various physical scenarios where objects are blocked by other objects in the scene.
-
Network Architecture: The neural network architecture consists of an encoder that takes in the partial observation of the object, and a decoder that outputs the reconstructed 3D shape. The network is designed to capture the underlying physical constraints of the scene.
-
Self-Training: The network is trained in a self-supervised manner, using the simulated dataset. It learns to predict the complete 3D shape of an object from its partially occluded observation, leveraging the physical relationships in the data.
The key insight is that by grounding the training process in physical simulations, the neural network can learn to reason about the hidden parts of the object based on the visible portions. This allows it to accurately reconstruct the full 3D shape, even when parts of the object are occluded.
Critical Analysis
The paper makes a valuable contribution by demonstrating how physics-driven self-training can be a powerful approach for 3D reconstruction of occluded objects. However, a few caveats and limitations are worth noting:
-
Simulation Fidelity: The quality of the reconstructions will depend on the realism and comprehensiveness of the physical simulations used to generate the training data. If the simulations do not capture important real-world phenomena, the network may struggle to generalize to true, complex scenes.
-
Scalability: While the self-training approach can potentially scale to large datasets, the initial effort required to create high-quality simulations may limit the practicality of this method, especially for diverse and dynamic real-world scenarios.
-
Generalization: It's unclear how well the trained network would perform on objects or scenes that deviate significantly from the simulated data. Further research is needed to assess the generalization capabilities of this approach.
-
Computational Complexity: The physics-driven reasoning and 3D reconstruction performed by the network may be computationally intensive, which could limit its real-time applications, such as in autonomous vehicles.
Despite these limitations, the paper presents an innovative and promising approach that leverages the power of physics-driven self-training to tackle the challenging problem of 3D reconstruction under occlusion. Future research building upon this work could lead to significant advancements in this area.
Conclusion
The paper introduces a novel physics-driven self-training neural network for reconstructing the complete 3D shape of partially occluded objects. By grounding the training process in physical simulations, the network learns to leverage the underlying physics of the scene to accurately predict the hidden parts of an object based on its visible portions.
This approach has the potential to significantly advance the state of the art in 3D reconstruction, with applications in areas such as autonomous vehicles, robotics, and augmented reality. While the method has some limitations, the key insights and techniques presented in the paper could inspire further research and development in this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reconstruction of partially occluded objects with a physics-driven self-training neural network
Mingjun Xiang, Kai Zhou, Hui Yuan, Hartmut G. Roskos
This study proposes a novel approach utilizing a physics-informed deep learning (DL) algorithm to reconstruct occluded objects in a terahertz (THz) holographic system. Taking the angular spectrum theory as prior knowledge, we generate a dataset consisting of a series of diffraction patterns that contain information about the objects. This dataset, combined with unlabeled data measured from experiments, are used for the self-training of a physics-informed neural network (NN). During the training process, the neural network iteratively predicts the outcomes of the unlabeled data and reincorporates these results back into the training set. This recursive strategy not only reduces noise but also minimizes mutual interference during object reconstruction, demonstrating its effectiveness even in data-scarce situations. The method has been validated with both simulated and experimental data, showcasing its significant potential to advance the field of terahertz three-dimensional (3D) imaging. Additionally, it sets a new benchmark for rapid, reference-free, and cost-effective power detection.
Read more8/26/2024

0
HDN:Hybrid Deep-learning and Non-line-of-sight Reconstruction Framework for Photoacoustic Brain Imaging
Pengcheng Wan, Fan Zhang, Yuting Shen, Xin Shang, Hulin Zhao, Shuangli Liu, Xiaohua Feng, Fei Gao
Photoacoustic imaging (PAI) combines the high contrast of optical imaging with the deep penetration depth of ultrasonic imaging, showing great potential in cerebrovascular disease detection. However, the ultrasonic wave suffers strong attenuation and multi-scattering when it passes through the skull tissue, resulting in the distortion of the collected photoacoustic (PA) signal. In this paper, inspired by the principles of deep learning and non-line-of-sight (NLOS) imaging, we propose an image reconstruction framework named HDN (Hybrid Deep-learning and Non-line-of-sight), which consists of the signal extraction part and difference utilization part. The signal extraction part is used to correct the distorted signal and reconstruct an initial image. The difference utilization part is used to make further use of the signal difference between the distorted signal and corrected signal, reconstructing the residual image between the initial image and the target image. The test results on a PA digital brain simulation dataset show that compared with the traditional delay-and-sum (DAS) method and deep-learning-based method, HDN achieved superior performance in both signal correction and image reconstruction. Specifically for the SSIM index, the HDN reached 0.606 in imaging results, compared to 0.154 for the DAS method and 0.307 for the deep-learning-based method.
Read more8/23/2024
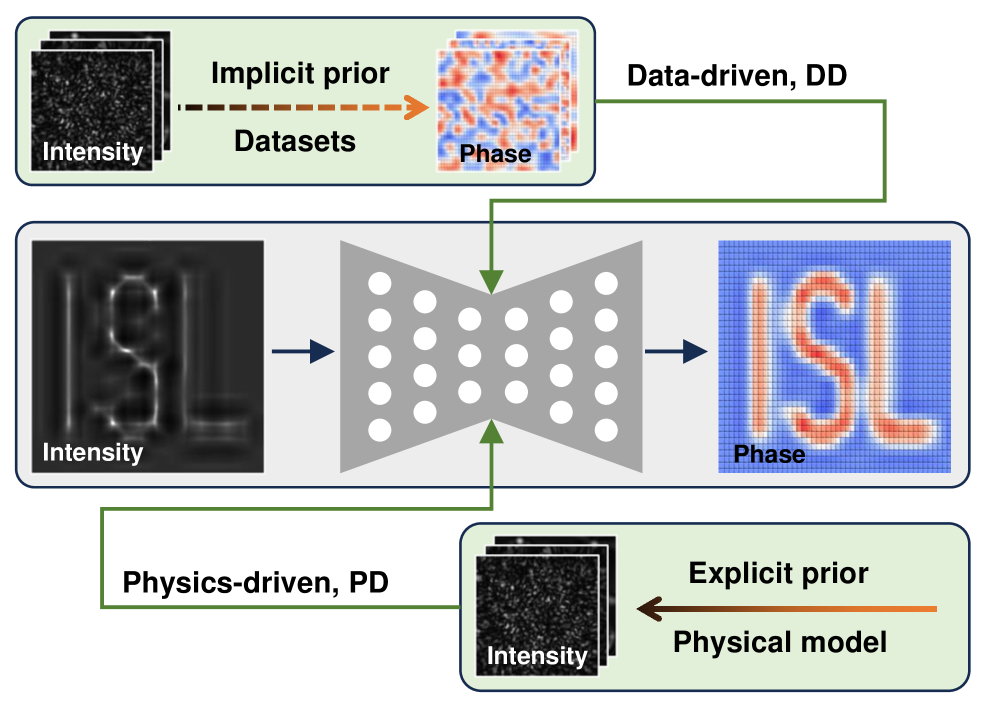
0
Harnessing Data and Physics for Deep Learning Phase Recovery
Kaiqiang Wang, Edmund Y. Lam
Phase recovery, calculating the phase of a light wave from its intensity measurements, is essential for various applications, such as coherent diffraction imaging, adaptive optics, and biomedical imaging. It enables the reconstruction of an object's refractive index distribution or topography as well as the correction of imaging system aberrations. In recent years, deep learning has been proven to be highly effective in addressing phase recovery problems. Two most direct deep learning phase recovery strategies are data-driven (DD) with supervised learning mode and physics-driven (PD) with self-supervised learning mode. DD and PD achieve the same goal in different ways and lack the necessary study to reveal similarities and differences. Therefore, in this paper, we comprehensively compare these two deep learning phase recovery strategies in terms of time consumption, accuracy, generalization ability, ill-posedness adaptability, and prior capacity. What's more, we propose a co-driven (CD) strategy of combining datasets and physics for the balance of high- and low-frequency information. The codes for DD, PD, and CD are publicly available at https://github.com/kqwang/DLPR.
Read more8/13/2024

0
Category-level Neural Field for Reconstruction of Partially Observed Objects in Indoor Environment
Taekbeom Lee, Youngseok Jang, H. Jin Kim
Neural implicit representation has attracted attention in 3D reconstruction through various success cases. For further applications such as scene understanding or editing, several works have shown progress towards object compositional reconstruction. Despite their superior performance in observed regions, their performance is still limited in reconstructing objects that are partially observed. To better treat this problem, we introduce category-level neural fields that learn meaningful common 3D information among objects belonging to the same category present in the scene. Our key idea is to subcategorize objects based on their observed shape for better training of the category-level model. Then we take advantage of the neural field to conduct the challenging task of registering partially observed objects by selecting and aligning against representative objects selected by ray-based uncertainty. Experiments on both simulation and real-world datasets demonstrate that our method improves the reconstruction of unobserved parts for several categories.
Read more6/13/2024