Recovering document annotations for sentence-level bitext
2406.03869
0
0

Abstract
Data availability limits the scope of any given task. In machine translation, historical models were incapable of handling longer contexts, so the lack of document-level datasets was less noticeable. Now, despite the emergence of long-sequence methods, we remain within a sentence-level paradigm and without data to adequately approach context-aware machine translation. Most large-scale datasets have been processed through a pipeline that discards document-level metadata. In this work, we reconstruct document-level information for three (ParaCrawl, News Commentary, and Europarl) large datasets in German, French, Spanish, Italian, Polish, and Portuguese (paired with English). We then introduce a document-level filtering technique as an alternative to traditional bitext filtering. We present this filtering with analysis to show that this method prefers context-consistent translations rather than those that may have been sentence-level machine translated. Last we train models on these longer contexts and demonstrate improvement in document-level translation without degradation of sentence-level translation. We release our dataset, ParaDocs, and resulting models as a resource to the community.
Create account to get full access
Overview
This research paper explores a novel approach to recovering document-level annotations for sentence-level bitext, which is the process of aligning and comparing parallel text in different languages. The authors propose a method that can leverage document-level context to improve the accuracy of sentence-level bitext alignment, a crucial task in machine translation and other language processing applications.
Plain English Explanation
When translating text from one language to another, it's important to not only translate individual sentences correctly, but also maintain the overall meaning and context of the document. The authors of this paper recognized that existing sentence-level bitext alignment methods often fail to capture the nuances and relationships between sentences that are evident at the document level.
To address this, they developed a technique that can recover document-level annotations, such as topic, style, and discourse structure, and use that information to better align sentences across languages. This is like being able to understand the bigger picture of a conversation, not just the individual words, to improve the accuracy of translation.
The key insight is that document-level context provides valuable clues that can help resolve ambiguities and inconsistencies that arise when aligning sentences in isolation. By incorporating this higher-level information, the authors' method can produce more coherent and accurate sentence-level bitext alignments, which can ultimately lead to better machine translations and other language-based applications.
Technical Explanation
The authors propose a two-stage approach to recovering document annotations for sentence-level bitext alignment. First, they use a neural network-based model to extract document-level features, such as topic, style, and discourse structure, from the source and target language texts. These features are then used to guide the alignment of sentences between the parallel documents.
The document-level feature extraction is accomplished through a neural encoder-decoder architecture, where the encoder learns to represent the document in a compact, latent space, and the decoder reconstructs the original document from this representation. The authors demonstrate that this approach is effective at capturing the salient aspects of document-level context that are relevant for the bitext alignment task.
In the second stage, the authors incorporate the extracted document-level features into a sentence-level bitext alignment model. This allows the alignment process to consider not only the lexical and syntactic similarities between individual sentences, but also the broader semantic and discourse-level relationships within the document. The authors show that this hybrid approach outperforms traditional sentence-level alignment methods on a range of benchmark datasets.
Critical Analysis
The authors have presented a compelling approach to leveraging document-level context for improved sentence-level bitext alignment. By incorporating higher-level features, such as topic and discourse structure, their method addresses a key limitation of existing sentence-level alignment techniques, which can struggle to capture the nuances of language at the document level.
One potential limitation of the proposed method is its reliance on the accuracy of the document-level feature extraction. If the neural encoder-decoder model fails to accurately capture the relevant aspects of the document, the subsequent alignment process may be compromised. The authors acknowledge this challenge and suggest further research into more robust document representation learning techniques.
Additionally, the authors' experiments were conducted on a relatively small set of language pairs and document types. It would be valuable to see how the method performs on a wider range of language combinations and document genres, as well as its scalability to large-scale datasets.
Overall, the authors' work represents a significant advancement in the field of bitext alignment, with the potential to improve the quality of machine translation and other language processing applications that rely on parallel text. By integrating document-level context, this research challenges the traditional sentence-level paradigm and opens up new avenues for exploration in the field.
Conclusion
This research paper presents a novel approach to recovering document-level annotations for sentence-level bitext alignment. By leveraging document-level features, such as topic, style, and discourse structure, the authors' method can produce more accurate and coherent alignments between parallel texts, ultimately leading to improvements in machine translation and other language-based applications.
The key innovation of this work is its ability to bridge the gap between the traditional sentence-level paradigm and the need to incorporate higher-level contextual information for effective language processing. As the field of natural language processing continues to evolve, this research represents an important step towards developing more holistic and nuanced approaches to working with parallel text.
While the authors have demonstrated the effectiveness of their method on a limited set of datasets, further research is needed to explore its scalability and generalizability to a wider range of language pairs and document types. Nevertheless, this work serves as a valuable contribution to the ongoing efforts to enhance the state-of-the-art in bitext alignment and machine translation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Escaping the sentence-level paradigm in machine translation
Matt Post, Marcin Junczys-Dowmunt
0
0
It is well-known that document context is vital for resolving a range of translation ambiguities, and in fact the document setting is the most natural setting for nearly all translation. It is therefore unfortunate that machine translation -- both research and production -- largely remains stuck in a decades-old sentence-level translation paradigm. It is also an increasingly glaring problem in light of competitive pressure from large language models, which are natively document-based. Much work in document-context machine translation exists, but for various reasons has been unable to catch hold. This paper suggests a path out of this rut by addressing three impediments at once: what architectures should we use? where do we get document-level information for training them? and how do we know whether they are any good? In contrast to work on specialized architectures, we show that the standard Transformer architecture is sufficient, provided it has enough capacity. Next, we address the training data issue by taking document samples from back-translated data only, where the data is not only more readily available, but is also of higher quality compared to parallel document data, which may contain machine translation output. Finally, we propose generative variants of existing contrastive metrics that are better able to discriminate among document systems. Results in four large-data language pairs (DE$rightarrow$EN, EN$rightarrow$DE, EN$rightarrow$FR, and EN$rightarrow$RU) establish the success of these three pieces together in improving document-level performance.
5/17/2024
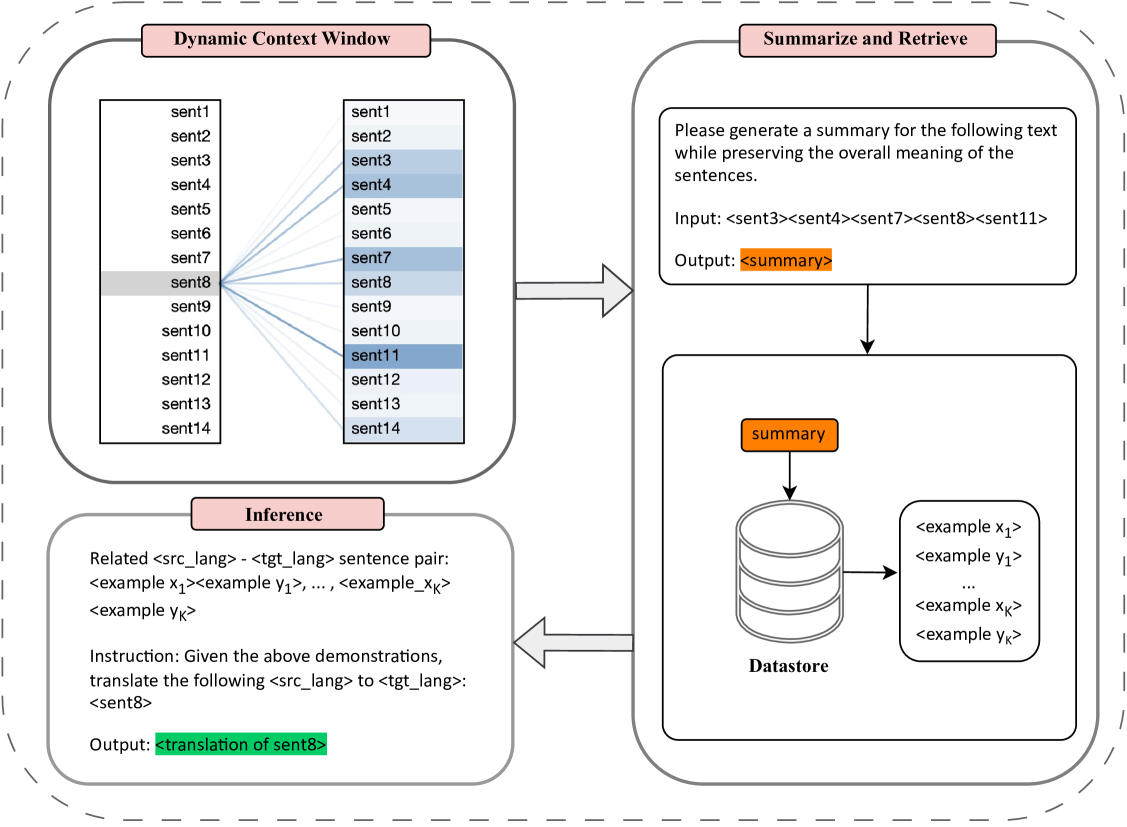
Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
Menglong Cui, Jiangcun Du, Shaolin Zhu, Deyi Xiong
0
0
Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.
6/12/2024
🛸
Using Contextual Information for Sentence-level Morpheme Segmentation
Prabin Bhandari, Abhishek Paudel
0
0
Recent advancements in morpheme segmentation primarily emphasize word-level segmentation, often neglecting the contextual relevance within the sentence. In this study, we redefine the morpheme segmentation task as a sequence-to-sequence problem, treating the entire sentence as input rather than isolating individual words. Our findings reveal that the multilingual model consistently exhibits superior performance compared to monolingual counterparts. While our model did not surpass the performance of the current state-of-the-art, it demonstrated comparable efficacy with high-resource languages while revealing limitations in low-resource language scenarios.
5/15/2024

Reconsidering Sentence-Level Sign Language Translation
Garrett Tanzer, Maximus Shengelia, Ken Harrenstien, David Uthus
0
0
Historically, sign language machine translation has been posed as a sentence-level task: datasets consisting of continuous narratives are chopped up and presented to the model as isolated clips. In this work, we explore the limitations of this task framing. First, we survey a number of linguistic phenomena in sign languages that depend on discourse-level context. Then as a case study, we perform the first human baseline for sign language translation that actually substitutes a human into the machine learning task framing, rather than provide the human with the entire document as context. This human baseline -- for ASL to English translation on the How2Sign dataset -- shows that for 33% of sentences in our sample, our fluent Deaf signer annotators were only able to understand key parts of the clip in light of additional discourse-level context. These results underscore the importance of understanding and sanity checking examples when adapting machine learning to new domains.
6/18/2024