Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
2406.07081
0
0
Abstract
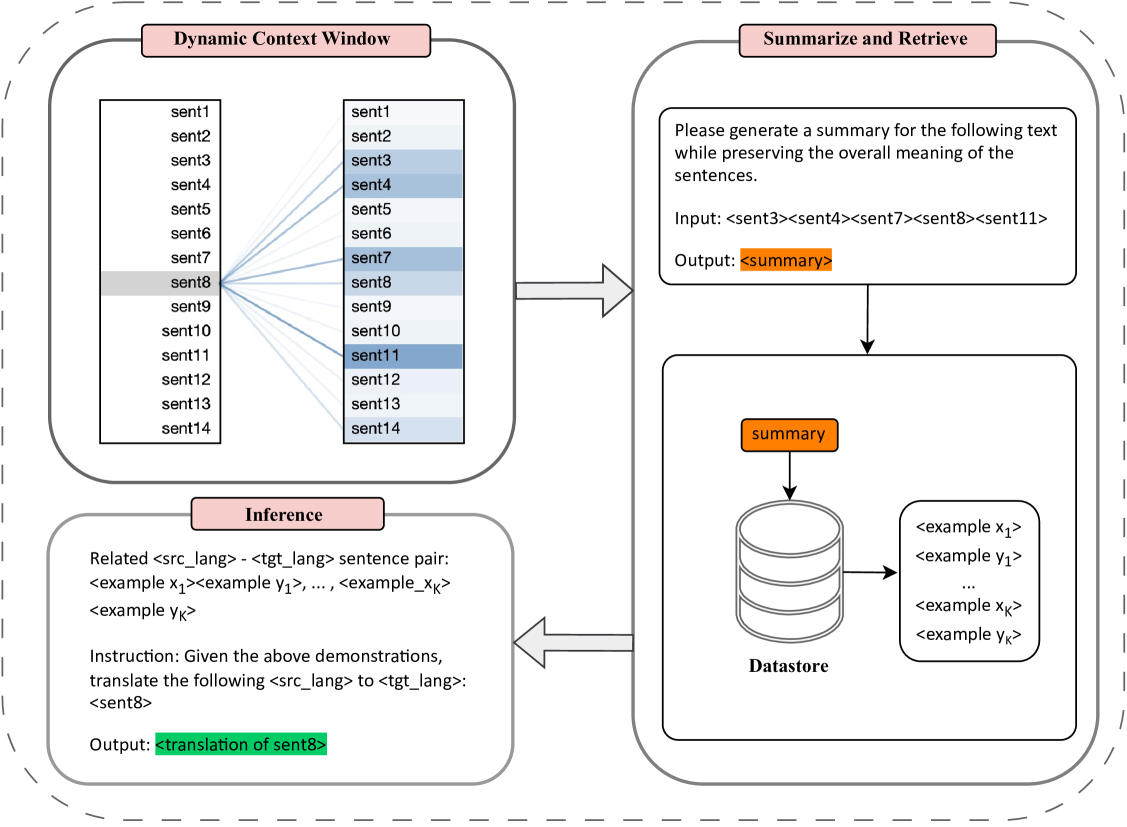
Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.
Create account to get full access
Overview
- This paper explores how large language models (LLMs) can be efficiently used for document-level machine translation by leveraging in-context learning.
- The researchers propose a novel paradigm that goes beyond the traditional sentence-level approach to machine translation, aiming to exploit the contextual information available in LLMs.
- The paper presents an empirical study on the capabilities of LLMs for document-level translation, offering insights into how these models can be effectively utilized.
Plain English Explanation
The paper looks at how we can use large language models (LLMs) - powerful AI systems trained on vast amounts of text data - to translate entire documents, rather than just individual sentences. Traditional machine translation systems typically work at the sentence level, but the researchers argue that by taking advantage of the contextual information available in LLMs, we can improve the quality and coherence of document-level translations.
The key idea is to use "in-context learning," where the LLM is provided with relevant context (such as the surrounding text) when translating a particular sentence or paragraph. This allows the model to better understand the meaning and nuance of the content, leading to more accurate and natural-sounding translations.
The researchers conduct experiments to explore the capabilities of LLMs in this document-level translation task, providing insights into how these powerful AI systems can be effectively leveraged for this purpose. This work represents a novel approach that goes beyond the traditional sentence-level paradigm, potentially leading to significant improvements in the quality and usability of machine translation systems.
Technical Explanation
The paper presents a novel paradigm for leveraging large language models (LLMs) for document-level machine translation, going beyond the traditional sentence-level approach. The researchers explore the use of in-context learning, where the LLM is provided with relevant contextual information (such as the surrounding text) when translating a particular sentence or paragraph.
The key elements of the research include:
-
Experiment Design: The authors conducted extensive experiments to assess the capabilities of LLMs in document-level translation tasks. This involved evaluating the models' performance on a range of document-level translation benchmarks, as well as analyzing the impact of various contextual factors on translation quality.
-
Architecture: The paper describes the architectural choices and techniques employed to effectively integrate in-context learning into the document-level translation process. This includes strategies for efficiently encoding and leveraging the contextual information available in LLMs.
-
Insights: The research provides valuable insights into the strengths and limitations of LLMs for document-level translation. The findings highlight the potential advantages of this approach, as well as the challenges that need to be addressed to fully realize the benefits of contextual information in machine translation.
Critical Analysis
The paper presents a well-designed and thorough investigation into the use of LLMs for document-level machine translation, offering a novel paradigm that goes beyond the traditional sentence-level approach. The researchers acknowledge the potential limitations of their work, such as the need for further research to fully understand the impact of various contextual factors on translation quality.
One potential concern raised in the paper is the computational and memory requirements of the in-context learning approach, which may limit its scalability and real-world applicability. The authors suggest that future work should explore strategies to address these efficiency challenges, such as the development of more compact and optimized model architectures.
Additionally, the paper does not delve deeply into the ethical implications of deploying such powerful translation systems, particularly in sensitive domains or with underrepresented languages. Further research could explore potential biases, fairness considerations, and the societal impact of these technologies.
Overall, the paper presents a compelling and well-executed study that makes a significant contribution to the field of machine translation. The insights and techniques described have the potential to drive substantial improvements in the quality and usability of document-level translation systems, but there is still work to be done to address the remaining challenges and ensure the responsible development of these technologies.
Conclusion
This paper introduces a novel paradigm for leveraging large language models (LLMs) to perform document-level machine translation, going beyond the traditional sentence-level approach. By incorporating in-context learning, the researchers demonstrate how LLMs can better exploit the contextual information available in source documents, leading to more accurate and coherent translations.
The extensive experiments and analysis presented in the paper provide valuable insights into the capabilities and limitations of LLMs in this domain. The findings suggest that this approach has the potential to significantly enhance the quality and usability of machine translation systems, particularly for tasks that require a deeper understanding of the broader context.
While the paper acknowledges certain challenges, such as the computational and memory requirements of the in-context learning approach, the overall contribution of this work is significant. As the field of machine translation continues to evolve, the insights and techniques described in this paper could pave the way for more advanced and effective document-level translation systems, with far-reaching implications for communication, collaboration, and global understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Adapting Large Language Models for Document-Level Machine Translation
Minghao Wu, Thuy-Trang Vu, Lizhen Qu, George Foster, Gholamreza Haffari
0
0
Large language models (LLMs) have significantly advanced various natural language processing (NLP) tasks. Recent research indicates that moderately-sized LLMs often outperform larger ones after task-specific fine-tuning. This study focuses on adapting LLMs for document-level machine translation (DocMT) for specific language pairs. We first investigate the impact of prompt strategies on translation performance and then conduct extensive experiments using two fine-tuning methods, three LLM backbones, and 18 translation tasks across nine language pairs. Our results show that specialized models can sometimes surpass GPT-4 in translation performance but still face issues like off-target translation due to error propagation in decoding. We provide an in-depth analysis of these LLMs tailored for DocMT, examining translation errors, discourse phenomena, training strategies, the scaling law of parallel documents, recent test set evaluations, and zero-shot crosslingual transfer. Our findings highlight the strengths and limitations of LLM-based DocMT models and provide a foundation for future research.
6/11/2024
📈
An Empirical Study of In-context Learning in LLMs for Machine Translation
Pranjal A. Chitale, Jay Gala, Raj Dabre
0
0
Recent interest has surged in employing Large Language Models (LLMs) for machine translation (MT) via in-context learning (ICL) (Vilar et al., 2023). Most prior studies primarily focus on optimizing translation quality, with limited attention to understanding the specific aspects of ICL that influence the said quality. To this end, we perform the first of its kind, an exhaustive study of in-context learning for machine translation. We first establish that ICL is primarily example-driven and not instruction-driven. Following this, we conduct an extensive exploration of various aspects of the examples to understand their influence on downstream performance. Our analysis includes factors such as quality and quantity of demonstrations, spatial proximity, and source versus target originality. Further, we also investigate challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL. While we establish the significance of the quality of the target distribution over the source distribution of demonstrations, we further observe that perturbations sometimes act as regularizers, resulting in performance improvements. Surprisingly, ICL does not necessitate examples from the same task, and a related task with the same target distribution proves sufficient. We hope that our study acts as a guiding resource for considerations in utilizing ICL for MT. Our code is available on https://github.com/PranjalChitale/in-context-mt-analysis.
6/6/2024

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024
Guiding In-Context Learning of LLMs through Quality Estimation for Machine Translation
Javad Pourmostafa Roshan Sharami, Dimitar Shterionov, Pieter Spronck
0
0
The quality of output from large language models (LLMs), particularly in machine translation (MT), is closely tied to the quality of in-context examples (ICEs) provided along with the query, i.e., the text to translate. The effectiveness of these ICEs is influenced by various factors, such as the domain of the source text, the order in which the ICEs are presented, the number of these examples, and the prompt templates used. Naturally, selecting the most impactful ICEs depends on understanding how these affect the resulting translation quality, which ultimately relies on translation references or human judgment. This paper presents a novel methodology for in-context learning (ICL) that relies on a search algorithm guided by domain-specific quality estimation (QE). Leveraging the XGLM model, our methodology estimates the resulting translation quality without the need for translation references, selecting effective ICEs for MT to maximize translation quality. Our results demonstrate significant improvements over existing ICL methods and higher translation performance compared to fine-tuning a pre-trained language model (PLM), specifically mBART-50.
6/13/2024