Recovering Global Data Distribution Locally in Federated Learning

0
Sign in to get full access
Overview
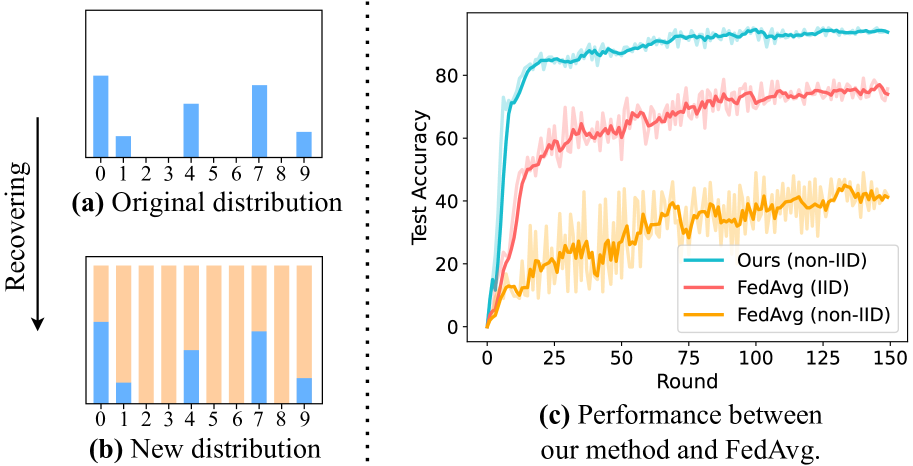
- The paper explores how to recover the global data distribution in federated learning settings where data is heterogeneously distributed across clients.
- It proposes a method to estimate the global data distribution from local model updates, enabling more effective federated learning.
- The approach involves learning a distribution matching function to map local client updates to the global distribution.
Plain English Explanation
Federated learning is a way for multiple devices or organizations to train a shared machine learning model without directly sharing their private data. Instead, each participant trains the model on their own data and sends the model updates back to a central server. However, this can be challenging when the data is very different across participants, as the global data distribution may not be well-represented.
The key idea in this paper is to recover the global data distribution from the local model updates sent by each participant. The researchers propose learning a "distribution matching function" that can map the local updates to the true global distribution. This allows the central server to reconstruct the overall data distribution, even when the local data is highly heterogeneous.
By recovering the global distribution, the central model can then be trained more effectively, taking into account the full diversity of data rather than just the skewed distributions seen by individual participants. This helps overcome the challenges of local data bias in federated learning.
Technical Explanation
The paper first provides background on federated learning and related work on addressing data heterogeneity in this setting. It then introduces the key technical approach, which involves learning a distribution matching function to map the local updates from each client to the underlying global data distribution.
Specifically, the authors propose a two-stage training process. First, they train a generative model to learn the global data distribution using a small amount of held-out global data. Then, they train a separate "distribution matching" model to predict this global distribution from the local model updates of each client.
Once this distribution matching function is learned, it can be used during federated training to recover the global data distribution from the locally-computed model updates, enabling the central server to perform more effective federated optimization.
The paper evaluates this approach on several benchmark federated learning tasks, demonstrating improvements in model performance compared to standard federated learning techniques.
Critical Analysis
The researchers acknowledge that their approach relies on having access to a small amount of held-out global data to train the initial generative model. This may not always be feasible in real-world federated learning deployments where data privacy is a key concern.
Additionally, the distribution matching function itself adds some computational overhead during federated training, which could limit scalability to very large numbers of clients. The paper does not explore the sensitivity of the approach to the size or quality of the held-out global data used for pretraining.
Further research could investigate ways to reduce the reliance on global data or make the distribution matching more efficient. Exploring the robustness of the approach to different types of data heterogeneity would also be valuable.
Conclusion
This paper presents an innovative technique for recovering the global data distribution in federated learning settings, which can help overcome challenges posed by skewed local data distributions. By learning a distribution matching function, the central server can reconstruct the full diversity of the global data, leading to more effective federated model training.
While the approach has some practical limitations, it represents an important step forward in addressing data heterogeneity, a key challenge in deploying federated learning at scale. Further research building on these ideas could yield valuable insights for improving the robustness and real-world applicability of federated learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Recovering Global Data Distribution Locally in Federated Learning
Ziyu Yao
Federated Learning (FL) is a distributed machine learning paradigm that enables collaboration among multiple clients to train a shared model without sharing raw data. However, a major challenge in FL is the label imbalance, where clients may exclusively possess certain classes while having numerous minority and missing classes. Previous works focus on optimizing local updates or global aggregation but ignore the underlying imbalanced label distribution across clients. In this paper, we propose a novel approach ReGL to address this challenge, whose key idea is to Recover the Global data distribution Locally. Specifically, each client uses generative models to synthesize images that complement the minority and missing classes, thereby alleviating label imbalance. Moreover, we adaptively fine-tune the image generation process using local real data, which makes the synthetic images align more closely with the global distribution. Importantly, both the generation and fine-tuning processes are conducted at the client-side without leaking data privacy. Through comprehensive experiments on various image classification datasets, we demonstrate the remarkable superiority of our approach over existing state-of-the-art works in fundamentally tackling label imbalance in FL.
Read more9/24/2024
🤖
0
New!GLOCALFAIR: Jointly Improving Global and Local Group Fairness in Federated Learning
Syed Irfan Ali Meerza, Luyang Liu, Jiaxin Zhang, Jian Liu
Federated learning (FL) has emerged as a prospective solution for collaboratively learning a shared model across clients without sacrificing their data privacy. However, the federated learned model tends to be biased against certain demographic groups (e.g., racial and gender groups) due to the inherent FL properties, such as data heterogeneity and party selection. Unlike centralized learning, mitigating bias in FL is particularly challenging as private training datasets and their sensitive attributes are typically not directly accessible. Most prior research in this field only focuses on global fairness while overlooking the local fairness of individual clients. Moreover, existing methods often require sensitive information about the client's local datasets to be shared, which is not desirable. To address these issues, we propose GLOCALFAIR, a client-server co-design fairness framework that can jointly improve global and local group fairness in FL without the need for sensitive statistics about the client's private datasets. Specifically, we utilize constrained optimization to enforce local fairness on the client side and adopt a fairness-aware clustering-based aggregation on the server to further ensure the global model fairness across different sensitive groups while maintaining high utility. Experiments on two image datasets and one tabular dataset with various state-of-the-art fairness baselines show that GLOCALFAIR can achieve enhanced fairness under both global and local data distributions while maintaining a good level of utility and client fairness.
Read more10/4/2024

0
Federated Impression for Learning with Distributed Heterogeneous Data
Sana Ayromlou, Atrin Arya, Armin Saadat, Purang Abolmaesumi, Xiaoxiao Li
Standard deep learning-based classification approaches may not always be practical in real-world clinical applications, as they require a centralized collection of all samples. Federated learning (FL) provides a paradigm that can learn from distributed datasets across clients without requiring them to share data, which can help mitigate privacy and data ownership issues. In FL, sub-optimal convergence caused by data heterogeneity is common among data from different health centers due to the variety in data collection protocols and patient demographics across centers. Through experimentation in this study, we show that data heterogeneity leads to the phenomenon of catastrophic forgetting during local training. We propose FedImpres which alleviates catastrophic forgetting by restoring synthetic data that represents the global information as federated impression. To achieve this, we distill the global model resulting from each communication round. Subsequently, we use the synthetic data alongside the local data to enhance the generalization of local training. Extensive experiments show that the proposed method achieves state-of-the-art performance on both the BloodMNIST and Retina datasets, which contain label imbalance and domain shift, with an improvement in classification accuracy of up to 20%.
Read more9/12/2024
🌿
0
Recovering Labels from Local Updates in Federated Learning
Huancheng Chen, Haris Vikalo
Gradient inversion (GI) attacks present a threat to the privacy of clients in federated learning (FL) by aiming to enable reconstruction of the clients' data from communicated model updates. A number of such techniques attempts to accelerate data recovery by first reconstructing labels of the samples used in local training. However, existing label extraction methods make strong assumptions that typically do not hold in realistic FL settings. In this paper we present a novel label recovery scheme, Recovering Labels from Local Updates (RLU), which provides near-perfect accuracy when attacking untrained (most vulnerable) models. More significantly, RLU achieves high performance even in realistic real-world settings where the clients in an FL system run multiple local epochs, train on heterogeneous data, and deploy various optimizers to minimize different objective functions. Specifically, RLU estimates labels by solving a least-square problem that emerges from the analysis of the correlation between labels of the data points used in a training round and the resulting update of the output layer. The experimental results on several datasets, architectures, and data heterogeneity scenarios demonstrate that the proposed method consistently outperforms existing baselines, and helps improve quality of the reconstructed images in GI attacks in terms of both PSNR and LPIPS.
Read more5/3/2024