Recursive Estimation of Conditional Kernel Mean Embeddings

0
🗣️
Sign in to get full access
Overview
- Kernel mean embeddings are a widely used technique in machine learning that maps probability distributions to elements of a reproducing kernel Hilbert space (RKHS).
- For supervised learning problems, the conditional distribution of outputs given inputs is a key object, which can be encoded with an RKHS-valued function called the conditional kernel mean map.
- This paper presents a new recursive algorithm to estimate the conditional kernel mean map in a Hilbert space-valued $L_2$ space, or Bochner space.
- The authors prove the weak and strong $L_2$ consistency of their recursive estimator under mild conditions, and provide new insights and strong asymptotic bounds regarding the convergence of the proposed method.
- The results are demonstrated on three application domains: Euclidean spaces, Riemannian manifolds, and locally compact subsets of function spaces.
Plain English Explanation
Kernel mean embeddings are a way to represent probability distributions as points in a special mathematical space called a reproducing kernel Hilbert space (RKHS). This is useful in machine learning, where we often work with data that can be represented as probability distributions.
In supervised learning problems, where we have input-output pairs, the conditional distribution of the outputs given the inputs is an important quantity. The conditional kernel mean map is a way to encode this conditional distribution as an RKHS-valued function.
This paper introduces a new algorithm to estimate the conditional kernel mean map. The key idea is to generalize a theorem from statistics (called Stone's theorem) to the case where the outputs are Hilbert space-valued, rather than just real-valued. The authors prove that their algorithm converges to the true conditional kernel mean map as the amount of data increases, under mild conditions.
The main significance of this work is that it provides a principled way to learn the relationship between inputs and output distributions in a wide variety of settings, including Euclidean spaces, curved spaces called Riemannian manifolds, and even spaces of functions. This could be useful in many real-world applications where we want to model the uncertainty in the outputs of a machine learning system.
Technical Explanation
The authors propose a new recursive algorithm to estimate the conditional kernel mean map, which is an RKHS-valued function that encodes the conditional distribution of outputs given inputs in a supervised learning problem.
The key idea is to generalize Stone's theorem for Hilbert space-valued regression from the real-valued case to the case where the outputs lie in a Hilbert space. This allows the authors to derive weak and strong $L_2$ consistency results for their recursive estimator under mild conditions.
The authors provide new insights into the properties of conditional kernel mean embeddings, and derive strong asymptotic bounds on the convergence rate of their proposed method. They demonstrate the effectiveness of their approach on three application domains:
- Euclidean spaces: Where the inputs and outputs are vectors in Euclidean space.
- Riemannian manifolds: Where the inputs and outputs lie on curved geometric spaces called Riemannian manifolds.
- Locally compact subsets of function spaces: Where the inputs and outputs are functions, rather than vectors or points on a manifold.
The ability to handle these diverse input and output spaces is a key strength of the proposed approach, as it allows the conditional kernel mean map to be applied in a wide range of real-world settings.
Critical Analysis
The authors provide a thorough theoretical analysis of their proposed recursive algorithm for estimating the conditional kernel mean map. They prove strong convergence guarantees under mild conditions, which is an important contribution to the literature on kernel methods and conditional distribution learning.
However, the paper does not discuss any potential limitations or caveats of their approach. For example, the performance of the algorithm may depend on the choice of kernel function, which is not explored in depth. Additionally, the computational complexity of the recursive updates may be a concern for large-scale problems, which is not addressed.
Furthermore, the authors do not compare their method to alternative approaches for conditional distribution learning, such as Gaussian processes or neural networks. Such a comparative analysis would help situate the proposed algorithm within the broader landscape of techniques for this problem.
Overall, the paper presents a novel and theoretically-grounded algorithm for conditional kernel mean embedding estimation, but could be strengthened by a more comprehensive discussion of the method's limitations, comparisons to related work, and potential areas for future research.
Conclusion
This paper introduces a new recursive algorithm for estimating the conditional kernel mean map, which is a powerful tool for modeling the relationship between inputs and output distributions in supervised learning problems. The authors prove strong convergence guarantees for their method and demonstrate its applicability across a range of domains, including Euclidean spaces, Riemannian manifolds, and function spaces.
The significance of this work lies in its ability to flexibly capture the uncertainty in the outputs of machine learning systems, which is crucial for many real-world applications. By generalizing Stone's theorem to the Hilbert space-valued case, the authors have made an important theoretical contribution that could inspire further advancements in the field of kernel methods and conditional distribution learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Recursive Estimation of Conditional Kernel Mean Embeddings
Ambrus Tam'as, Bal'azs Csan'ad Cs'aji
Kernel mean embeddings, a widely used technique in machine learning, map probability distributions to elements of a reproducing kernel Hilbert space (RKHS). For supervised learning problems, where input-output pairs are observed, the conditional distribution of outputs given the inputs is a key object. The input dependent conditional distribution of an output can be encoded with an RKHS valued function, the conditional kernel mean map. In this paper we present a new recursive algorithm to estimate the conditional kernel mean map in a Hilbert space valued $L_2$ space, that is in a Bochner space. We prove the weak and strong $L_2$ consistency of our recursive estimator under mild conditions. The idea is to generalize Stone's theorem for Hilbert space valued regression in a locally compact Polish space. We present new insights about conditional kernel mean embeddings and give strong asymptotic bounds regarding the convergence of the proposed recursive method. Finally, the results are demonstrated on three application domains: for inputs coming from Euclidean spaces, Riemannian manifolds and locally compact subsets of function spaces.
Read more9/2/2024
🖼️
0
Compressed Online Learning of Conditional Mean Embedding
Boya Hou, Sina Sanjari, Alec Koppel, Subhonmesh Bose
The conditional mean embedding (CME) encodes Markovian stochastic kernels through their actions on probability distributions embedded within the reproducing kernel Hilbert spaces (RKHS). The CME plays a key role in several well-known machine learning tasks such as reinforcement learning, analysis of dynamical systems, etc. We present an algorithm to learn the CME incrementally from data via an operator-valued stochastic gradient descent. As is well-known, function learning in RKHS suffers from scalability challenges from large data. We utilize a compression mechanism to counter the scalability challenge. The core contribution of this paper is a finite-sample performance guarantee on the last iterate of the online compressed operator learning algorithm with fast-mixing Markovian samples, when the target CME may not be contained in the hypothesis space. We illustrate the efficacy of our algorithm by applying it to the analysis of an example dynamical system.
Read more5/14/2024
🔄
0
On the Consistency of Kernel Methods with Dependent Observations
Pierre-Franc{c}ois Massiani, Sebastian Trimpe, Friedrich Solowjow
The consistency of a learning method is usually established under the assumption that the observations are a realization of an independent and identically distributed (i.i.d.) or mixing process. Yet, kernel methods such as support vector machines (SVMs), Gaussian processes, or conditional kernel mean embeddings (CKMEs) all give excellent performance under sampling schemes that are obviously non-i.i.d., such as when data comes from a dynamical system. We propose the new notion of empirical weak convergence (EWC) as a general assumption explaining such phenomena for kernel methods. It assumes the existence of a random asymptotic data distribution and is a strict weakening of previous assumptions in the field. Our main results then establish consistency of SVMs, kernel mean embeddings, and general Hilbert-space valued empirical expectations with EWC data. Our analysis holds for both finite- and infinite-dimensional outputs, as we extend classical results of statistical learning to the latter case. In particular, it is also applicable to CKMEs. Overall, our results open new classes of processes to statistical learning and can serve as a foundation for a theory of learning beyond i.i.d. and mixing.
Read more6/11/2024
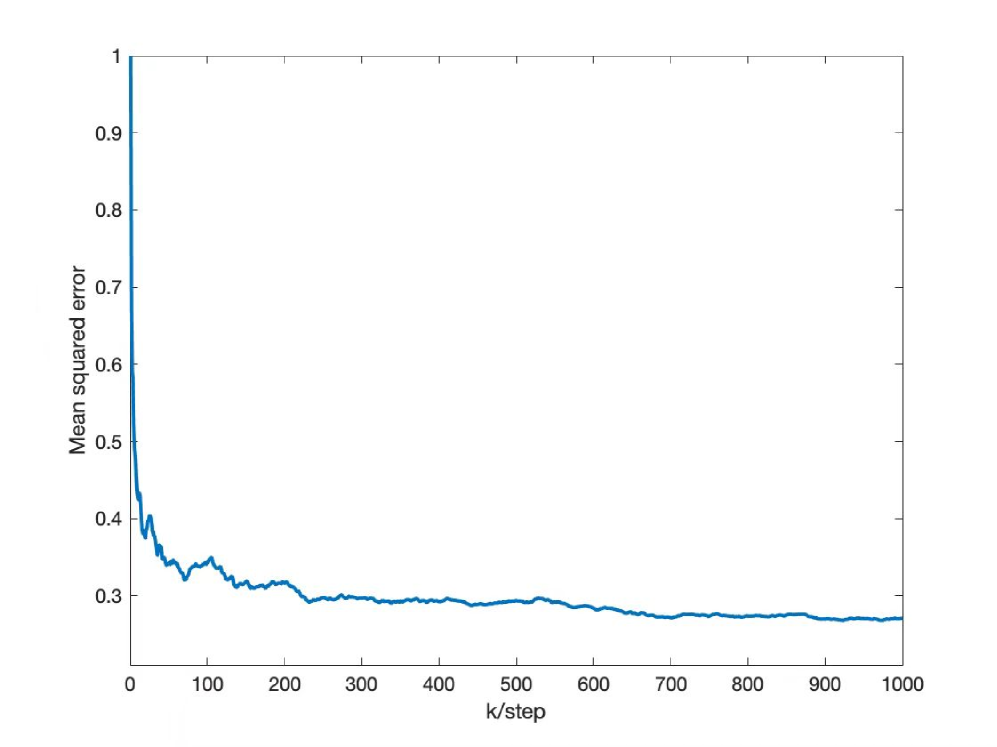
0
Convergence Conditions of Online Regularized Statistical Learning in Reproducing Kernel Hilbert Space With Non-Stationary Data
Xiwei Zhang, Tao Li
We study the convergence of recursive regularized learning algorithms in the reproducing kernel Hilbert space (RKHS) with dependent and non-stationary online data streams. Firstly, we study the mean square asymptotic stability of a class of random difference equations in RKHS, whose non-homogeneous terms are martingale difference sequences dependent on the homogeneous ones. Secondly, we introduce the concept of random Tikhonov regularization path, and show that if the regularization path is slowly time-varying in some sense, then the output of the algorithm is consistent with the regularization path in mean square. Furthermore, if the data streams also satisfy the RKHS persistence of excitation condition, i.e. there exists a fixed length of time period, such that the conditional expectation of the operators induced by the input data accumulated over every time period has a uniformly strictly positive compact lower bound in the sense of the operator order with respect to time, then the output of the algorithm is consistent with the unknown function in mean square. Finally, for the case with independent and non-identically distributed data streams, the algorithm achieves the mean square consistency provided the marginal probability measures induced by the input data are slowly time-varying and the average measure over each fixed-length time period has a uniformly strictly positive lower bound.
Read more6/11/2024