RED QUEEN: Safeguarding Large Language Models against Concealed Multi-Turn Jailbreaking

0

Sign in to get full access
Overview
- Introduces the "Red Queen" approach to safeguard large language models (LLMs) against concealed multi-turn jailbreaking attacks
- Highlights the limitations of current defenses and the need for a more robust solution
- Proposes a framework that combines adversarial training, instruction-following, and reward modeling to make LLMs more resistant to such attacks
Plain English Explanation
The paper focuses on a critical issue in the field of large language models (LLMs): the risk of "jailbreaking" attacks. Jailbreaking refers to the process of bypassing the safety and security measures designed to keep LLMs aligned with their intended purpose and instructions.
The authors recognize that current defenses against jailbreaking are often limited and can be circumvented through concealed multi-turn attacks. These attacks involve a series of carefully crafted prompts that gradually guide the LLM to behave in unintended and potentially harmful ways, without the user or the system being aware of the underlying manipulation.
To address this challenge, the researchers introduce the "Red Queen" approach, which combines several techniques to make LLMs more resilient to such attacks. The key components of this framework include:
- Adversarial Training: Exposing the LLM to a wide range of adversarial prompts during training, allowing it to learn to identify and resist attempts to manipulate its behavior.
- Instruction-Following: Reinforcing the LLM's commitment to following the given instructions and not deviating from its intended purpose, even in the face of complex or ambiguous prompts.
- Reward Modeling: Introducing a system that evaluates the LLM's responses and rewards behaviors that align with the desired objectives, discouraging any attempts at jailbreaking.
By integrating these elements, the "Red Queen" approach aims to create LLMs that are more robust and resistant to concealed multi-turn jailbreaking attacks, helping to ensure the safe and reliable deployment of these powerful language models.
Technical Explanation
The paper introduces the "Red Queen" framework, which combines several techniques to strengthen the security and alignment of large language models (LLMs) against concealed multi-turn jailbreaking attacks.
The key components of the "Red Queen" approach are:
-
Adversarial Training: The researchers expose the LLM to a diverse set of adversarial prompts during the training process, which helps the model learn to identify and resist attempts to manipulate its behavior. This adversarial training approach is designed to make the LLM more resilient to complex, multi-turn attacks that gradually guide it towards unintended outputs.
-
Instruction-Following: The framework emphasizes the importance of reinforcing the LLM's commitment to following the given instructions and maintaining its intended purpose, even when faced with ambiguous or potentially misleading prompts. This component aims to instill a strong alignment between the LLM's actions and the desired objectives.
-
Reward Modeling: The researchers introduce a system that evaluates the LLM's responses and provides rewards for behaviors that align with the intended objectives. This reward modeling approach discourages the LLM from engaging in any jailbreaking attempts, as it learns that such behaviors are not rewarded and are, in fact, penalized.
By integrating these three key elements - adversarial training, instruction-following, and reward modeling - the "Red Queen" framework aims to create LLMs that are more robust and resistant to concealed multi-turn jailbreaking attacks. This approach helps ensure the safe and reliable deployment of these powerful language models, mitigating the risks associated with potential misuse or unintended behaviors.
Critical Analysis
The "Red Queen" framework presented in this paper addresses an important challenge in the field of large language models (LLMs) - the threat of concealed multi-turn jailbreaking attacks. The authors recognize the limitations of current defenses and the need for a more comprehensive approach to safeguarding LLMs.
One of the key strengths of the "Red Queen" approach is its multi-pronged strategy, combining adversarial training, instruction-following, and reward modeling. This combination of techniques aims to create LLMs that are not only more resistant to specific attack patterns but also have a stronger alignment with their intended purpose and objectives.
However, the paper does not provide a detailed evaluation of the approach, and it remains to be seen how effective the "Red Queen" framework is in practice. The authors acknowledge the need for further research and experimentation to validate the effectiveness of this approach, particularly in the face of evolving attack strategies.
Additionally, the paper does not address potential ethical considerations or the societal implications of deploying LLMs with enhanced security and alignment measures. As these models become more prevalent, it will be crucial to consider the broader implications of such safeguarding techniques and ensure they are developed and deployed responsibly.
Conclusion
The "Red Queen" framework introduced in this paper represents a promising approach to safeguarding large language models (LLMs) against concealed multi-turn jailbreaking attacks. By combining adversarial training, instruction-following, and reward modeling, the researchers aim to create LLMs that are more resistant to complex, gradual attempts to bypass their safety and security measures.
While the paper highlights the limitations of current defenses and the need for a more robust solution, further research and evaluation are required to validate the effectiveness of the "Red Queen" approach in real-world scenarios. As LLMs continue to play an increasingly important role in various domains, the development of reliable safeguarding mechanisms will be crucial to ensure their safe and responsible deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RED QUEEN: Safeguarding Large Language Models against Concealed Multi-Turn Jailbreaking
Yifan Jiang, Kriti Aggarwal, Tanmay Laud, Kashif Munir, Jay Pujara, Subhabrata Mukherjee
The rapid progress of Large Language Models (LLMs) has opened up new opportunities across various domains and applications; yet it also presents challenges related to potential misuse. To mitigate such risks, red teaming has been employed as a proactive security measure to probe language models for harmful outputs via jailbreak attacks. However, current jailbreak attack approaches are single-turn with explicit malicious queries that do not fully capture the complexity of real-world interactions. In reality, users can engage in multi-turn interactions with LLM-based chat assistants, allowing them to conceal their true intentions in a more covert manner. To bridge this gap, we, first, propose a new jailbreak approach, RED QUEEN ATTACK. This method constructs a multi-turn scenario, concealing the malicious intent under the guise of preventing harm. We craft 40 scenarios that vary in turns and select 14 harmful categories to generate 56k multi-turn attack data points. We conduct comprehensive experiments on the RED QUEEN ATTACK with four representative LLM families of different sizes. Our experiments reveal that all LLMs are vulnerable to RED QUEEN ATTACK, reaching 87.62% attack success rate on GPT-4o and 75.4% on Llama3-70B. Further analysis reveals that larger models are more susceptible to the RED QUEEN ATTACK, with multi-turn structures and concealment strategies contributing to its success. To prioritize safety, we introduce a straightforward mitigation strategy called RED QUEEN GUARD, which aligns LLMs to effectively counter adversarial attacks. This approach reduces the attack success rate to below 1% while maintaining the model's performance across standard benchmarks. Full implementation and dataset are publicly accessible at https://github.com/kriti-hippo/red_queen.
Read more9/27/2024

0
RedAgent: Red Teaming Large Language Models with Context-aware Autonomous Language Agent
Huiyu Xu, Wenhui Zhang, Zhibo Wang, Feng Xiao, Rui Zheng, Yunhe Feng, Zhongjie Ba, Kui Ren
Recently, advanced Large Language Models (LLMs) such as GPT-4 have been integrated into many real-world applications like Code Copilot. These applications have significantly expanded the attack surface of LLMs, exposing them to a variety of threats. Among them, jailbreak attacks that induce toxic responses through jailbreak prompts have raised critical safety concerns. To identify these threats, a growing number of red teaming approaches simulate potential adversarial scenarios by crafting jailbreak prompts to test the target LLM. However, existing red teaming methods do not consider the unique vulnerabilities of LLM in different scenarios, making it difficult to adjust the jailbreak prompts to find context-specific vulnerabilities. Meanwhile, these methods are limited to refining jailbreak templates using a few mutation operations, lacking the automation and scalability to adapt to different scenarios. To enable context-aware and efficient red teaming, we abstract and model existing attacks into a coherent concept called jailbreak strategy and propose a multi-agent LLM system named RedAgent that leverages these strategies to generate context-aware jailbreak prompts. By self-reflecting on contextual feedback in an additional memory buffer, RedAgent continuously learns how to leverage these strategies to achieve effective jailbreaks in specific contexts. Extensive experiments demonstrate that our system can jailbreak most black-box LLMs in just five queries, improving the efficiency of existing red teaming methods by two times. Additionally, RedAgent can jailbreak customized LLM applications more efficiently. By generating context-aware jailbreak prompts towards applications on GPTs, we discover 60 severe vulnerabilities of these real-world applications with only two queries per vulnerability. We have reported all found issues and communicated with OpenAI and Meta for bug fixes.
Read more7/24/2024

0
Making Them Ask and Answer: Jailbreaking Large Language Models in Few Queries via Disguise and Reconstruction
Tong Liu, Yingjie Zhang, Zhe Zhao, Yinpeng Dong, Guozhu Meng, Kai Chen
In recent years, large language models (LLMs) have demonstrated notable success across various tasks, but the trustworthiness of LLMs is still an open problem. One specific threat is the potential to generate toxic or harmful responses. Attackers can craft adversarial prompts that induce harmful responses from LLMs. In this work, we pioneer a theoretical foundation in LLMs security by identifying bias vulnerabilities within the safety fine-tuning and design a black-box jailbreak method named DRA (Disguise and Reconstruction Attack), which conceals harmful instructions through disguise and prompts the model to reconstruct the original harmful instruction within its completion. We evaluate DRA across various open-source and closed-source models, showcasing state-of-the-art jailbreak success rates and attack efficiency. Notably, DRA boasts a 91.1% attack success rate on OpenAI GPT-4 chatbot.
Read more6/11/2024
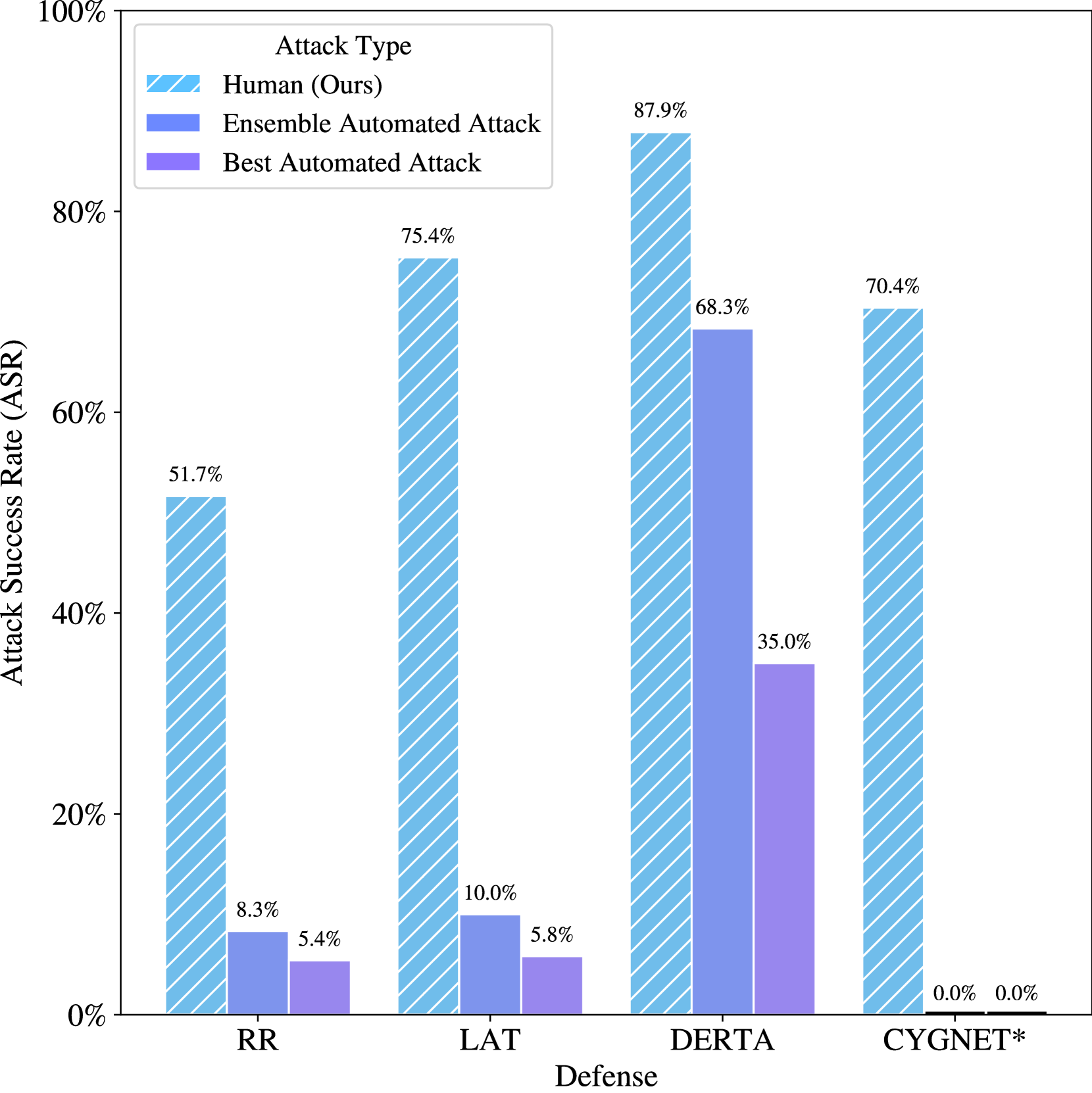
0
LLM Defenses Are Not Robust to Multi-Turn Human Jailbreaks Yet
Nathaniel Li, Ziwen Han, Ian Steneker, Willow Primack, Riley Goodside, Hugh Zhang, Zifan Wang, Cristina Menghini, Summer Yue
Recent large language model (LLM) defenses have greatly improved models' ability to refuse harmful queries, even when adversarially attacked. However, LLM defenses are primarily evaluated against automated adversarial attacks in a single turn of conversation, an insufficient threat model for real-world malicious use. We demonstrate that multi-turn human jailbreaks uncover significant vulnerabilities, exceeding 70% attack success rate (ASR) on HarmBench against defenses that report single-digit ASRs with automated single-turn attacks. Human jailbreaks also reveal vulnerabilities in machine unlearning defenses, successfully recovering dual-use biosecurity knowledge from unlearned models. We compile these results into Multi-Turn Human Jailbreaks (MHJ), a dataset of 2,912 prompts across 537 multi-turn jailbreaks. We publicly release MHJ alongside a compendium of jailbreak tactics developed across dozens of commercial red teaming engagements, supporting research towards stronger LLM defenses.
Read more9/5/2024