On Reducing Activity with Distillation and Regularization for Energy Efficient Spiking Neural Networks

0

Sign in to get full access
Overview
- This paper explores techniques to reduce the energy consumption of Spiking Neural Networks (SNNs) by decreasing their spiking activity.
- The authors propose using knowledge distillation and regularization methods to train energy-efficient SNNs for edge computing applications.
- The research aims to make SNNs more viable for real-world deployment by improving their energy efficiency without sacrificing performance.
Plain English Explanation
The paper focuses on making spiking neural networks (SNNs) more energy-efficient. SNNs are a type of artificial intelligence that are inspired by the way the human brain works, using "spikes" of information instead of the continuous values used in traditional neural networks. While SNNs have the potential to be very energy-efficient, they can still use a lot of power, especially when running on devices with limited resources like smartphones or sensors.
To address this, the researchers experimented with two techniques: knowledge distillation and regularization. Knowledge distillation is a way of training a smaller, more efficient neural network by having it learn from a larger, more powerful one. Regularization is a method of adding extra constraints to the training process to encourage the network to learn in a certain way - in this case, to reduce its spiking activity.
By combining these techniques, the researchers were able to train SNN models that maintained good performance while using much less energy than traditional SNN models. This could make SNNs more practical for use in energy-constrained applications like mobile devices or internet-connected sensors, where power efficiency is crucial. The paper also discusses ways to further enhance the adversarial robustness of these energy-efficient SNNs.
Technical Explanation
The researchers proposed a two-stage training approach to reduce the spiking activity of SNNs. In the first stage, they used knowledge distillation to train a compact SNN model by having it learn from a larger, pre-trained SNN teacher model. This allowed the compact model to maintain accuracy while becoming more energy-efficient.
In the second stage, the authors applied regularization techniques to further reduce the spiking activity of the compact SNN model. Specifically, they introduced a spike rate regularization term in the loss function to encourage the model to minimize its spiking activity during inference.
The authors evaluated their approach on several benchmark datasets and SNN architectures, including CenterNet for object detection. They found that their two-stage training method was able to reduce the spiking activity of the SNN models by up to 50% while maintaining comparable accuracy to the original, higher-activity models.
Critical Analysis
The researchers provide a thorough evaluation of their techniques, demonstrating their effectiveness across multiple datasets and SNN architectures. However, the paper does not extensively discuss the potential limitations or caveats of their approach.
One area that could be explored further is the impact of the proposed methods on the inference latency of the SNN models. Reducing spiking activity may also reduce the amount of computation required, potentially improving latency, but this was not explicitly analyzed in the paper.
Additionally, the authors could have provided more insight into the trade-offs between spiking activity reduction, model complexity, and performance. It would be helpful to understand how the degree of spiking activity reduction affects the model size, computational requirements, and accuracy, as this information could guide practitioners in selecting the optimal configuration for their specific use cases.
Conclusion
This paper presents a promising approach to improving the energy efficiency of spiking neural networks using knowledge distillation and regularization techniques. By reducing the spiking activity of SNN models without sacrificing performance, the researchers have made these bio-inspired AI systems more viable for deployment in energy-constrained edge computing applications.
The techniques described in this work could have significant implications for the broader adoption of spiking neural networks, which have the potential to be highly efficient compared to traditional artificial neural networks. Further research into the practical trade-offs and real-world performance of these energy-efficient SNN models would be valuable for advancing the state of the art in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On Reducing Activity with Distillation and Regularization for Energy Efficient Spiking Neural Networks
Thomas Louis, Benoit Miramond, Alain Pegatoquet, Adrien Girard
Interest in spiking neural networks (SNNs) has been growing steadily, promising an energy-efficient alternative to formal neural networks (FNNs), commonly known as artificial neural networks (ANNs). Despite increasing interest, especially for Edge applications, these event-driven neural networks suffered from their difficulty to be trained compared to FNNs. To alleviate this problem, a number of innovative methods have been developed to provide performance more or less equivalent to that of FNNs. However, the spiking activity of a network during inference is usually not considered. While SNNs may usually have performance comparable to that of FNNs, it is often at the cost of an increase of the network's activity, thus limiting the benefit of using them as a more energy-efficient solution. In this paper, we propose to leverage Knowledge Distillation (KD) for SNNs training with surrogate gradient descent in order to optimize the trade-off between performance and spiking activity. Then, after understanding why KD led to an increase in sparsity, we also explored Activations regularization and proposed a novel method with Logits Regularization. These approaches, validated on several datasets, clearly show a reduction in network spiking activity (-26.73% on GSC and -14.32% on CIFAR-10) while preserving accuracy.
Read more6/27/2024
🧠
0
Self-Distillation Learning Based on Temporal-Spatial Consistency for Spiking Neural Networks
Lin Zuo, Yongqi Ding, Mengmeng Jing, Kunshan Yang, Yunqian Yu
Spiking neural networks (SNNs) have attracted considerable attention for their event-driven, low-power characteristics and high biological interpretability. Inspired by knowledge distillation (KD), recent research has improved the performance of the SNN model with a pre-trained teacher model. However, additional teacher models require significant computational resources, and it is tedious to manually define the appropriate teacher network architecture. In this paper, we explore cost-effective self-distillation learning of SNNs to circumvent these concerns. Without an explicit defined teacher, the SNN generates pseudo-labels and learns consistency during training. On the one hand, we extend the timestep of the SNN during training to create an implicit temporal ``teacher that guides the learning of the original ``student, i.e., the temporal self-distillation. On the other hand, we guide the output of the weak classifier at the intermediate stage by the final output of the SNN, i.e., the spatial self-distillation. Our temporal-spatial self-distillation (TSSD) learning method does not introduce any inference overhead and has excellent generalization ability. Extensive experiments on the static image datasets CIFAR10/100 and ImageNet as well as the neuromorphic datasets CIFAR10-DVS and DVS-Gesture validate the superior performance of the TSSD method. This paper presents a novel manner of fusing SNNs with KD, providing insights into high-performance SNN learning methods.
Read more6/13/2024

0
Reconsidering the energy efficiency of spiking neural networks
Zhanglu Yan, Zhenyu Bai, Weng-Fai Wong
Spiking neural networks (SNNs) are generally regarded as more energy-efficient because they do not use multiplications. However, most SNN works only consider the counting of additions to evaluate energy consumption, neglecting other overheads such as memory accesses and data movement operations. This oversight can lead to a misleading perception of efficiency, especially when state-of-the-art SNN accelerators operate with very small time window sizes. In this paper, we present a detailed comparison of the energy consumption of artificial neural networks (ANNs) and SNNs from a hardware perspective. We provide accurate formulas for energy consumption based on classical multi-level memory hierarchy architectures, commonly used neuromorphic dataflow architectures, and our proposed improved spatial-dataflow architecture. Our research demonstrates that to achieve comparable accuracy and greater energy efficiency than ANNs, SNNs require strict limitations on both time window size T and sparsity s. For instance, with the VGG16 model and a fixed T of 6, the neuron sparsity rate must exceed 93% to ensure energy efficiency across most architectures. Inspired by our findings, we explore strategies to enhance energy efficiency by increasing sparsity. We introduce two regularization terms during training that constrain weights and activations, effectively boosting the sparsity rate. Our experiments on the CIFAR-10 dataset, using T of 6, show that our SNNs consume 69% of the energy used by optimized ANNs on spatial-dataflow architectures, while maintaining an SNN accuracy of 94.18%. This framework, developed using PyTorch, is publicly available for use and further research.
Read more9/16/2024
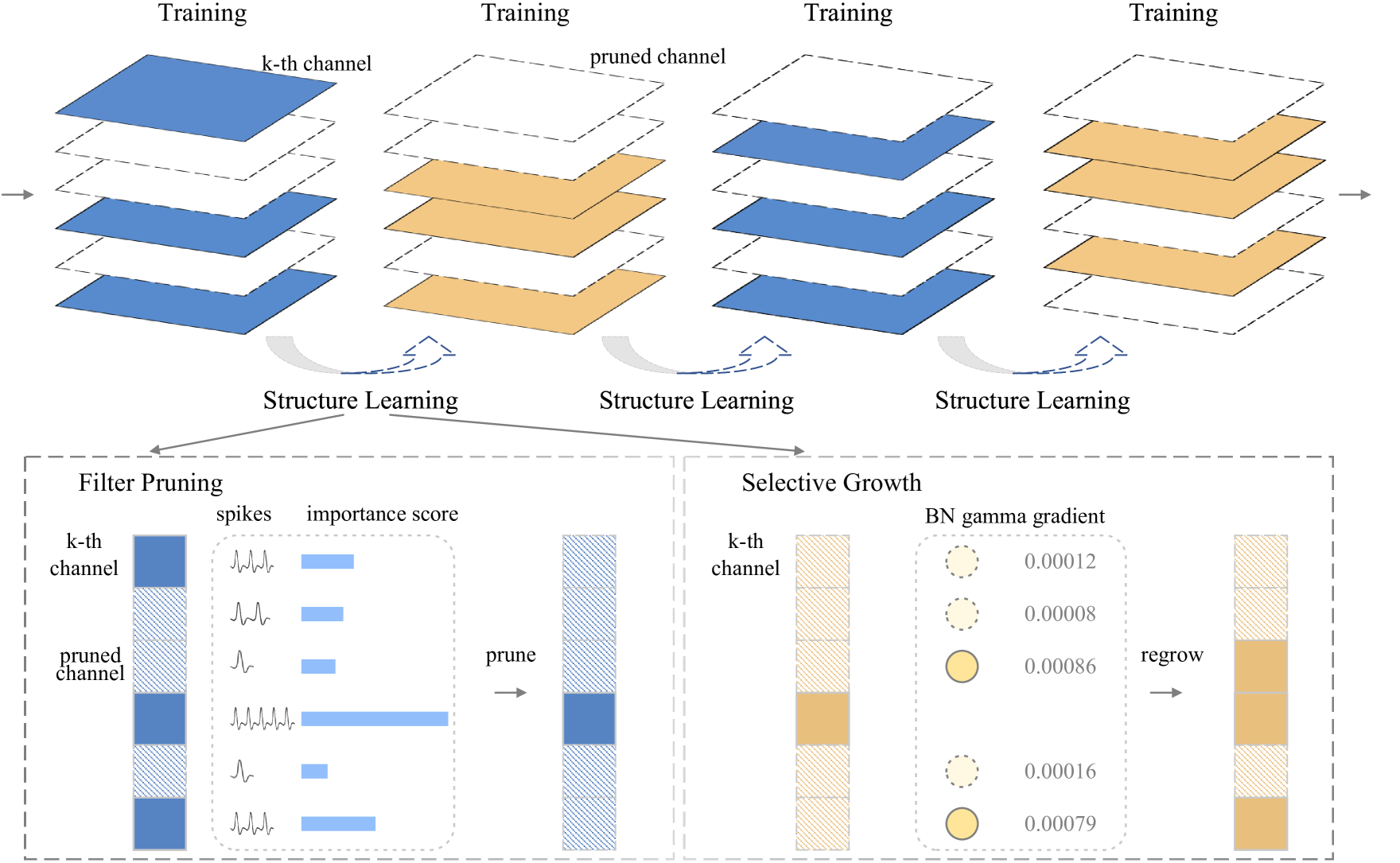
0
Towards Efficient Deep Spiking Neural Networks Construction with Spiking Activity based Pruning
Yaxin Li, Qi Xu, Jiangrong Shen, Hongming Xu, Long Chen, Gang Pan
The emergence of deep and large-scale spiking neural networks (SNNs) exhibiting high performance across diverse complex datasets has led to a need for compressing network models due to the presence of a significant number of redundant structural units, aiming to more effectively leverage their low-power consumption and biological interpretability advantages. Currently, most model compression techniques for SNNs are based on unstructured pruning of individual connections, which requires specific hardware support. Hence, we propose a structured pruning approach based on the activity levels of convolutional kernels named Spiking Channel Activity-based (SCA) network pruning framework. Inspired by synaptic plasticity mechanisms, our method dynamically adjusts the network's structure by pruning and regenerating convolutional kernels during training, enhancing the model's adaptation to the current target task. While maintaining model performance, this approach refines the network architecture, ultimately reducing computational load and accelerating the inference process. This indicates that structured dynamic sparse learning methods can better facilitate the application of deep SNNs in low-power and high-efficiency scenarios.
Read more6/4/2024