Reduction of finite sampling noise in quantum neural networks

0
➖
Sign in to get full access
Overview
- Quantum neural networks (QNNs) use quantum circuits with adjustable parameters and inputs to generate outputs through expectation value calculations
- Calculating these expectation values requires repeated circuit evaluations, introducing noise even on error-free quantum computers
- This paper introduces a "variance regularization" technique to reduce the variance of the expectation value during QNN training, which speeds up training and reduces output noise
Plain English Explanation
Quantum neural networks (QNNs) are a type of machine learning model that use quantum computers to process information. They work by feeding data into a quantum circuit - a setup of quantum components like qubits and gates. The circuit has adjustable parameters, and as the data goes through, the circuit generates an output.
To calculate this output, the QNN needs to repeatedly run the quantum circuit and average the results. However, even on a perfectly functioning quantum computer, this repeated running introduces some inherent uncertainty or "noise" in the final output.
The key innovation in this paper is a technique called "variance regularization" that helps reduce this noise. Essentially, it adjusts the way the QNN trains itself to minimize the variability or "variance" in the expectation value calculations. This allows the QNN to train faster and produce outputs with lower noise levels, without requiring any additional quantum circuit evaluations.
The authors demonstrate this technique on regression tasks and quantum chemistry problems, showing it can reduce the variance by an order of magnitude on average. They also show how it enables QNN training on real quantum hardware, where the reduced variance makes the optimization process feasible.
Technical Explanation
Quantum neural networks (QNNs) leverage parameterized quantum circuits to process data and generate outputs. The core of a QNN is the evaluation of expectation values, which requires repeatedly running the quantum circuit.
However, this repeated circuit evaluation introduces fundamental finite-sampling noise, even on error-free quantum computers. To address this, the authors propose a "variance regularization" technique that reduces the variance of the expectation value calculations during QNN training.
This regularization method does not require any additional circuit evaluations if the QNN is properly constructed. The authors' empirical results demonstrate that the reduced variance speeds up training, lowers output noise, and decreases the number of gradient circuit evaluations needed.
The technique is benchmarked on regression tasks and the potential energy surface of water. The authors show it can lower the variance by an order of magnitude on average, leading to significantly reduced noise in the QNN outputs. They also demonstrate QNN training on a real quantum device, where the reduced variance makes the optimization process feasible.
Critical Analysis
The authors acknowledge that their variance regularization technique relies on the QNN being properly constructed, which may not always be the case in practice. Additionally, the paper does not explore the broader implications or limitations of using variational quantum circuits for machine learning tasks.
While the results are promising, more research is needed to understand the generalizability of this approach to a wider range of QNN architectures and applications. The authors also do not discuss potential issues around the scalability of QNNs or the challenges of deploying them on noisy intermediate-scale quantum (NISQ) devices.
Further work could investigate the interactions between variance regularization and other optimization techniques for variational quantum circuits, as well as explore ways to train efficient density quantum machine learning models using this approach.
Conclusion
This paper introduces a novel variance regularization technique that significantly improves the trainability and performance of quantum neural networks. By reducing the inherent noise in the expectation value calculations, the method enables faster training and lower-noise outputs, even on real quantum hardware.
While the results are promising, further research is needed to understand the broader implications and limitations of this approach. Nonetheless, the authors have made an important contribution to the field of variational quantum neural networks and quantum machine learning, paving the way for more robust and efficient quantum-powered machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
Reduction of finite sampling noise in quantum neural networks
David A. Kreplin, Marco Roth
Quantum neural networks (QNNs) use parameterized quantum circuits with data-dependent inputs and generate outputs through the evaluation of expectation values. Calculating these expectation values necessitates repeated circuit evaluations, thus introducing fundamental finite-sampling noise even on error-free quantum computers. We reduce this noise by introducing the variance regularization, a technique for reducing the variance of the expectation value during the quantum model training. This technique requires no additional circuit evaluations if the QNN is properly constructed. Our empirical findings demonstrate the reduced variance speeds up the training and lowers the output noise as well as decreases the number of necessary evaluations of gradient circuits. This regularization method is benchmarked on the regression of multiple functions and the potential energy surface of water. We show that in our examples, it lowers the variance by an order of magnitude on average and leads to a significantly reduced noise level of the QNN. We finally demonstrate QNN training on a real quantum device and evaluate the impact of error mitigation. Here, the optimization is feasible only due to the reduced number of necessary shots in the gradient evaluation resulting from the reduced variance.
Read more6/24/2024
🤖
0
Improving Trainability of Variational Quantum Circuits via Regularization Strategies
Jun Zhuang, Jack Cunningham, Chaowen Guan
In the era of noisy intermediate-scale quantum (NISQ), variational quantum circuits (VQCs) have been widely applied in various domains, advancing the superiority of quantum circuits against classic models. Similar to classic models, regular VQCs can be optimized by various gradient-based methods. However, the optimization may be initially trapped in barren plateaus or eventually entangled in saddle points during training. These gradient issues can significantly undermine the trainability of VQC. In this work, we propose a strategy that regularizes model parameters with prior knowledge of the train data and Gaussian noise diffusion. We conduct ablation studies to verify the effectiveness of our strategy across four public datasets and demonstrate that our method can improve the trainability of VQCs against the above-mentioned gradient issues.
Read more5/6/2024
🛠️
0
A Study on Optimization Techniques for Variational Quantum Circuits in Reinforcement Learning
Michael Kolle, Timo Witter, Tobias Rohe, Gerhard Stenzel, Philipp Altmann, Thomas Gabor
Quantum Computing aims to streamline machine learning, making it more effective with fewer trainable parameters. This reduction of parameters can speed up the learning process and reduce the use of computational resources. However, in the current phase of quantum computing development, known as the noisy intermediate-scale quantum era (NISQ), learning is difficult due to a limited number of qubits and widespread quantum noise. To overcome these challenges, researchers are focusing on variational quantum circuits (VQCs). VQCs are hybrid algorithms that merge a quantum circuit, which can be adjusted through parameters, with traditional classical optimization techniques. These circuits require only few qubits for effective learning. Recent studies have presented new ways of applying VQCs to reinforcement learning, showing promising results that warrant further exploration. This study investigates the effects of various techniques -- data re-uploading, input scaling, output scaling -- and introduces exponential learning rate decay in the quantum proximal policy optimization algorithm's actor-VQC. We assess these methods in the popular Frozen Lake and Cart Pole environments. Our focus is on their ability to reduce the number of parameters in the VQC without losing effectiveness. Our findings indicate that data re-uploading and an exponential learning rate decay significantly enhance hyperparameter stability and overall performance. While input scaling does not improve parameter efficiency, output scaling effectively manages greediness, leading to increased learning speed and robustness.
Read more5/22/2024
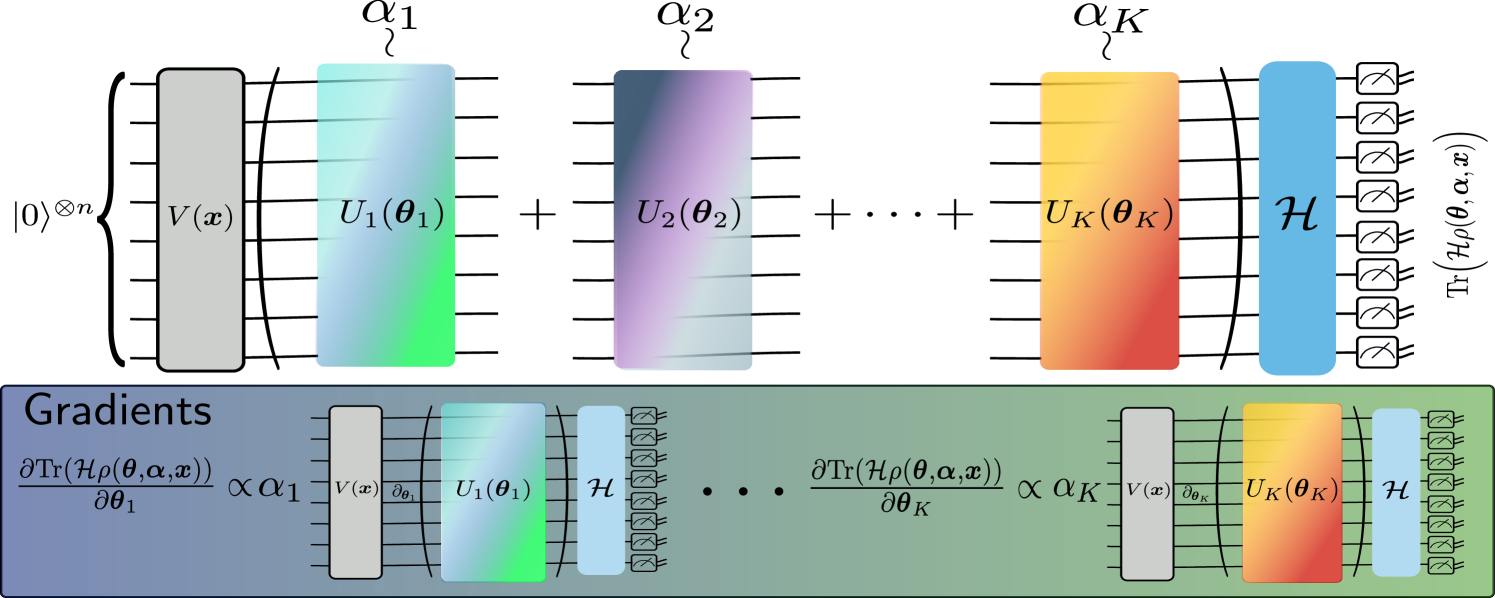
0
Training-efficient density quantum machine learning
Brian Coyle, El Amine Cherrat, Nishant Jain, Natansh Mathur, Snehal Raj, Skander Kazdaghli, Iordanis Kerenidis
Quantum machine learning requires powerful, flexible and efficiently trainable models to be successful in solving challenging problems. In this work, we present density quantum neural networks, a learning model incorporating randomisation over a set of trainable unitaries. These models generalise quantum neural networks using parameterised quantum circuits, and allow a trade-off between expressibility and efficient trainability, particularly on quantum hardware. We demonstrate the flexibility of the formalism by applying it to two recently proposed model families. The first are commuting-block quantum neural networks (QNNs) which are efficiently trainable but may be limited in expressibility. The second are orthogonal (Hamming-weight preserving) quantum neural networks which provide well-defined and interpretable transformations on data but are challenging to train at scale on quantum devices. Density commuting QNNs improve capacity with minimal gradient complexity overhead, and density orthogonal neural networks admit a quadratic-to-constant gradient query advantage with minimal to no performance loss. We conduct numerical experiments on synthetic translationally invariant data and MNIST image data with hyperparameter optimisation to support our findings. Finally, we discuss the connection to post-variational quantum neural networks, measurement-based quantum machine learning and the dropout mechanism.
Read more5/31/2024