Reformulating Conversational Recommender Systems as Tri-Phase Offline Policy Learning

0
Sign in to get full access
Overview
- The paper proposes a novel approach to conversational recommender systems by reformulating them as a tri-phase offline policy learning problem.
- The goal is to enable more efficient and scalable training of conversational recommender systems.
- The proposed approach involves three phases: user simulation, policy learning, and online deployment.
Plain English Explanation
The paper presents a new way of designing conversational recommender systems, which are AI systems that can have conversations with users to provide personalized product or content recommendations. Instead of training the system directly on conversations with real users, the researchers propose a three-step process:
-
User Simulation: First, they create a simulated user model that can have realistic conversations and provide feedback, allowing the recommender system to be trained without relying on actual user interactions.
-
Policy Learning: Next, the researchers use this simulated user model to train the recommender system's decision-making policies - i.e., how it should respond to users in different situations. This "offline" training approach is more efficient than trying to learn directly from limited real-world conversations.
-
Online Deployment: Finally, the trained recommender system can be deployed online to have conversations and make recommendations for real users.
By breaking the problem down into these three phases, the researchers aim to make the development of conversational recommender systems more scalable and practical. The simulated user model allows for faster, more thorough training, while the offline policy learning step ensures the system is well-prepared before being used with actual customers.
Technical Explanation
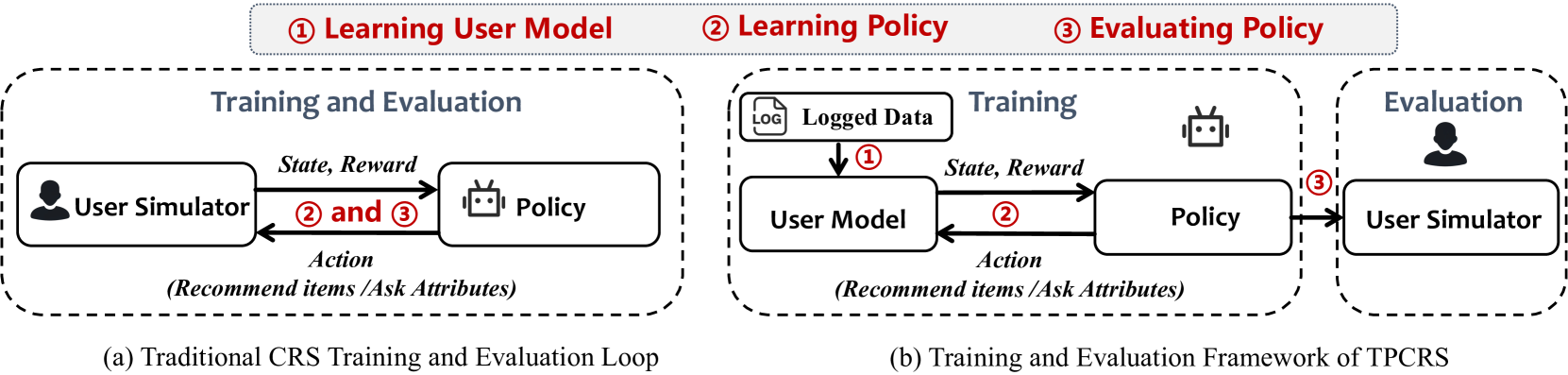
The paper proposes a novel tri-phase offline policy learning framework for building conversational recommender systems. The key idea is to reformulate the problem as an offline reinforcement learning task, rather than trying to learn directly from limited real-world user interactions.
The first phase involves [object Object], where the researchers create a simulated user model that can engage in realistic conversations and provide feedback. This allows the recommender system to be trained without relying on real users.
In the [object Object] phase, the researchers use the simulated user model to train the conversational policies of the recommender system in an offline setting. This is more efficient than trying to learn directly from live interactions.
Finally, in the online deployment phase, the trained recommender system can be put into production to have conversations and make recommendations for real users. The offline training approach is intended to make the overall system more scalable and practical.
Critical Analysis
The paper provides a thoughtful approach to addressing some of the key challenges in building effective conversational recommender systems. By separating the problem into distinct phases, the researchers aim to make the training process more efficient and the final system more robust.
However, the reliance on a simulated user model could be a potential limitation. While the model is designed to be realistic, it may not fully capture the complexities and nuances of real human conversations and preferences. There is a risk that the recommender system could overfit to the simulated environment and struggle to generalize to actual user interactions.
Additionally, the offline policy learning approach, while efficient, may miss out on important feedback and signals that could be gained from live user interactions. There may be advantages to incorporating some real-world data and feedback into the training process, even if it is more time-consuming.
Further research could explore ways to strike a better balance between the advantages of offline training and the richness of real-world user data. Hybrid approaches that combine simulated and live interactions may be a fruitful direction to investigate.
Conclusion
This paper presents an innovative framework for developing conversational recommender systems by reformulating the problem as a tri-phase offline policy learning task. The key idea is to leverage a simulated user model to enable more efficient and scalable training of the system's conversational policies.
While the proposed approach has some potential limitations, it represents an important step forward in addressing the challenges of building practical and effective conversational recommender systems. By breaking down the problem into distinct phases, the researchers aim to make the development process more manageable and the final system more robust and scalable.
As the field of conversational AI continues to evolve, this type of innovative thinking will be crucial in driving progress and unlocking new applications that can enhance user experiences and create value for businesses and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reformulating Conversational Recommender Systems as Tri-Phase Offline Policy Learning
Gangyi Zhang, Chongming Gao, Hang Pan, Runzhe Teng, Ruizhe Li
Existing Conversational Recommender Systems (CRS) predominantly utilize user simulators for training and evaluating recommendation policies. These simulators often oversimplify the complexity of user interactions by focusing solely on static item attributes, neglecting the rich, evolving preferences that characterize real-world user behavior. This limitation frequently leads to models that perform well in simulated environments but falter in actual deployment. Addressing these challenges, this paper introduces the Tri-Phase Offline Policy Learning-based Conversational Recommender System (TCRS), which significantly reduces dependency on real-time interactions and mitigates overfitting issues prevalent in traditional approaches. TCRS integrates a model-based offline learning strategy with a controllable user simulation that dynamically aligns with both personalized and evolving user preferences. Through comprehensive experiments, TCRS demonstrates enhanced robustness, adaptability, and accuracy in recommendations, outperforming traditional CRS models in diverse user scenarios. This approach not only provides a more realistic evaluation environment but also facilitates a deeper understanding of user behavior dynamics, thereby refining the recommendation process.
Read more9/10/2024
🔍
0
Chain-of-Choice Hierarchical Policy Learning for Conversational Recommendation
Wei Fan, Weijia Zhang, Weiqi Wang, Yangqiu Song, Hao Liu
Conversational Recommender Systems (CRS) illuminate user preferences via multi-round interactive dialogues, ultimately navigating towards precise and satisfactory recommendations. However, contemporary CRS are limited to inquiring binary or multi-choice questions based on a single attribute type (e.g., color) per round, which causes excessive rounds of interaction and diminishes the user's experience. To address this, we propose a more realistic and efficient conversational recommendation problem setting, called Multi-Type-Attribute Multi-round Conversational Recommendation (MTAMCR), which enables CRS to inquire about multi-choice questions covering multiple types of attributes in each round, thereby improving interactive efficiency. Moreover, by formulating MTAMCR as a hierarchical reinforcement learning task, we propose a Chain-of-Choice Hierarchical Policy Learning (CoCHPL) framework to enhance both the questioning efficiency and recommendation effectiveness in MTAMCR. Specifically, a long-term policy over options (i.e., ask or recommend) determines the action type, while two short-term intra-option policies sequentially generate the chain of attributes or items through multi-step reasoning and selection, optimizing the diversity and interdependence of questioning attributes. Finally, extensive experiments on four benchmarks demonstrate the superior performance of CoCHPL over prevailing state-of-the-art methods.
Read more4/4/2024

0
A LLM-based Controllable, Scalable, Human-Involved User Simulator Framework for Conversational Recommender Systems
Lixi Zhu, Xiaowen Huang, Jitao Sang
Conversational Recommender System (CRS) leverages real-time feedback from users to dynamically model their preferences, thereby enhancing the system's ability to provide personalized recommendations and improving the overall user experience. CRS has demonstrated significant promise, prompting researchers to concentrate their efforts on developing user simulators that are both more realistic and trustworthy. The emergence of Large Language Models (LLMs) has marked the onset of a new epoch in computational capabilities, exhibiting human-level intelligence in various tasks. Research efforts have been made to utilize LLMs for building user simulators to evaluate the performance of CRS. Although these efforts showcase innovation, they are accompanied by certain limitations. In this work, we introduce a Controllable, Scalable, and Human-Involved (CSHI) simulator framework that manages the behavior of user simulators across various stages via a plugin manager. CSHI customizes the simulation of user behavior and interactions to provide a more lifelike and convincing user interaction experience. Through experiments and case studies in two conversational recommendation scenarios, we show that our framework can adapt to a variety of conversational recommendation settings and effectively simulate users' personalized preferences. Consequently, our simulator is able to generate feedback that closely mirrors that of real users. This facilitates a reliable assessment of existing CRS studies and promotes the creation of high-quality conversational recommendation datasets.
Read more5/15/2024
📶
0
MemoCRS: Memory-enhanced Sequential Conversational Recommender Systems with Large Language Models
Yunjia Xi, Weiwen Liu, Jianghao Lin, Bo Chen, Ruiming Tang, Weinan Zhang, Yong Yu
Conversational recommender systems (CRSs) aim to capture user preferences and provide personalized recommendations through multi-round natural language dialogues. However, most existing CRS models mainly focus on dialogue comprehension and preferences mining from the current dialogue session, overlooking user preferences in historical dialogue sessions. The preferences embedded in the user's historical dialogue sessions and the current session exhibit continuity and sequentiality, and we refer to CRSs with this characteristic as sequential CRSs. In this work, we leverage memory-enhanced LLMs to model the preference continuity, primarily focusing on addressing two key issues: (1) redundancy and noise in historical dialogue sessions, and (2) the cold-start users problem. To this end, we propose a Memory-enhanced Conversational Recommender System Framework with Large Language Models (dubbed MemoCRS) consisting of user-specific memory and general memory. User-specific memory is tailored to each user for their personalized interests and implemented by an entity-based memory bank to refine preferences and retrieve relevant memory, thereby reducing the redundancy and noise of historical sessions. The general memory, encapsulating collaborative knowledge and reasoning guidelines, can provide shared knowledge for users, especially cold-start users. With the two kinds of memory, LLMs are empowered to deliver more precise and tailored recommendations for each user. Extensive experiments on both Chinese and English datasets demonstrate the effectiveness of MemoCRS.
Read more7/9/2024