ReFT: Representation Finetuning for Language Models
2404.03592
3
0
💬
Abstract
Parameter-efficient finetuning (PEFT) methods seek to adapt large neural models via updates to a small number of weights. However, much prior interpretability work has shown that representations encode rich semantic information, suggesting that editing representations might be a more powerful alternative. We pursue this hypothesis by developing a family of Representation Finetuning (ReFT) methods. ReFT methods operate on a frozen base model and learn task-specific interventions on hidden representations. We define a strong instance of the ReFT family, Low-rank Linear Subspace ReFT (LoReFT), and we identify an ablation of this method that trades some performance for increased efficiency. Both are drop-in replacements for existing PEFTs and learn interventions that are 15x--65x more parameter-efficient than LoRA. We showcase LoReFT on eight commonsense reasoning tasks, four arithmetic reasoning tasks, instruction-tuning, and GLUE. In all these evaluations, our ReFTs deliver the best balance of efficiency and performance, and almost always outperform state-of-the-art PEFTs. We release a generic ReFT training library publicly at https://github.com/stanfordnlp/pyreft.
Create account to get full access
Overview
- The paper introduces a new class of methods called Representation Finetuning (ReFT) that aim to adapt large language models by learning task-specific interventions on their hidden representations, rather than updating a small number of weights as in traditional parameter-efficient finetuning (PEFT) approaches.
- The authors propose a specific instance of ReFT called Low-rank Linear Subspace ReFT (LoReFT), which they show is 10-50x more parameter-efficient than existing PEFT methods while still delivering strong performance.
- LoReFT is evaluated on a diverse set of tasks including commonsense reasoning, arithmetic reasoning, and the GLUE benchmark, consistently outperforming state-of-the-art PEFT methods.
Plain English Explanation
Large language models like GPT-3 are powerful, but they can be costly and difficult to adapt to specific tasks. Traditional finetuning approaches update all the model's parameters, which can lead to overfitting and high compute requirements. To address this, researchers have developed parameter-efficient finetuning (PEFT) methods that only update a small subset of the model's weights.
However, this paper suggests an alternative approach: instead of just updating a few weights, we can learn targeted interventions on the model's internal representations (the hidden layers). The intuition is that the model's representations already encode a rich set of semantic information, so carefully editing these representations may be a more powerful way to adapt the model to a new task.
The authors propose a family of Representation Finetuning (ReFT) methods that operate on a frozen base model and learn task-specific changes to the hidden representations. They introduce a specific instance called Low-rank Linear Subspace ReFT (LoReFT), which is remarkably parameter-efficient - it requires updating only 10-50x fewer parameters than prior PEFT methods, while still achieving strong performance.
LoReFT outperforms existing PEFT methods on a diverse range of tasks, including commonsense reasoning, arithmetic, and the general GLUE benchmark. This suggests that learning targeted interventions on representations may be a more effective way to adapt large language models compared to just updating a small subset of weights.
Technical Explanation
The key insight behind ReFT is that language models' internal representations already capture rich semantic information, so directly editing these representations may be a more powerful adaptation strategy compared to the traditional PEFT approach of updating only a small number of weights.
ReFT methods operate on a frozen base model and learn task-specific "interventions" that are applied to the hidden representations. The authors define a specific ReFT method called Low-rank Linear Subspace ReFT (LoReFT), which learns a low-rank linear transformation that is applied to the hidden activations.
LoReFT is evaluated on eight commonsense reasoning tasks, four arithmetic reasoning tasks, the Alpaca-Eval benchmark, and the GLUE benchmark. Across all these evaluations, LoReFT delivers the best balance of performance and parameter efficiency compared to state-of-the-art PEFT methods. Notably, LoReFT requires updating 10-50x fewer parameters than prior PEFTs while still outperforming them.
The authors release a generic ReFT training library, making it easier for others to experiment with this new class of representation-editing methods. This could spur further research and innovation in parameter-efficient model adaptation strategies.
Critical Analysis
A key strength of the ReFT approach is its intuitive appeal - since language models' representations already capture rich semantic information, directly editing these representations seems like a more natural way to adapt the model compared to just updating a small subset of weights.
However, the paper does not provide a deep analysis of why ReFT methods are more effective than PEFT. It would be valuable to understand the specific characteristics of the representations that make them amenable to these targeted interventions. Are there certain types of tasks or models where ReFT is likely to be particularly advantageous?
Another potential limitation is the reliance on a frozen base model. In some cases, it may be beneficial to allow the base model to also update during finetuning, rather than keeping it completely frozen. This could introduce additional flexibility and performance gains.
The paper also does not discuss the computational overhead of applying the learned interventions during inference. If this overhead is significant, it could limit the practical benefits of the ReFT approach in real-world deployment scenarios.
Overall, this work presents a promising new direction for parameter-efficient model adaptation, but further research is needed to fully understand its strengths, limitations, and the best ways to leverage representation-level interventions.
Conclusion
This paper introduces a new family of Representation Finetuning (ReFT) methods that adapt large language models by learning task-specific interventions on their internal representations, rather than just updating a small subset of weights as in traditional parameter-efficient finetuning (PEFT) approaches.
The authors' specific ReFT instance, Low-rank Linear Subspace ReFT (LoReFT), is shown to be remarkably parameter-efficient - requiring 10-50x fewer updates than prior PEFT methods - while still delivering strong performance across a diverse range of tasks.
This work suggests that carefully editing a model's internal representations may be a more effective adaptation strategy than just updating a small number of weights. By releasing a ReFT training library, the authors hope to spur further research and innovation in this promising new direction for parameter-efficient model fine-tuning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Advancing Parameter Efficiency in Fine-tuning via Representation Editing
Muling Wu, Wenhao Liu, Xiaohua Wang, Tianlong Li, Changze Lv, Zixuan Ling, Jianhao Zhu, Cenyuan Zhang, Xiaoqing Zheng, Xuanjing Huang
0
0
Parameter Efficient Fine-Tuning (PEFT) techniques have drawn significant attention due to their ability to yield competitive results while updating only a small portion of the adjustable parameters. However, existing PEFT methods pose challenges in hyperparameter selection, such as choosing the rank for LoRA or Adapter, or specifying the length of soft prompts. To address these challenges, we propose a novel fine-tuning approach for neural models, named Representation EDiting (RED), which modifies the representations generated at some layers through the application of scaling and biasing operations. While existing PEFT methods still demonstrate over-parameterization that could potentially undermine the generalization ability acquired from pre-training, RED can substantially reduce the number of trainable parameters by a factor of 25, 700 compared to full parameter fine-tuning and by a factor of 32 relative to LoRA. Remarkably, RED achieves results comparable or superior to both full parameter fine-tuning and other PEFT methods. Extensive experiments across various model architectures and scales, including RoBERTa, GPT-2, T5, and LLaMA-2, have demonstrated the effectiveness and efficiency of RED1, thereby positioning it as a promising PEFT strategy for large-scale neural models.
6/4/2024

Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
0
0
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
4/30/2024

Q-PEFT: Query-dependent Parameter Efficient Fine-tuning for Text Reranking with Large Language Models
Zhiyuan Peng, Xuyang Wu, Qifan Wang, Sravanthi Rajanala, Yi Fang
0
0
Parameter Efficient Fine-Tuning (PEFT) methods have been extensively utilized in Large Language Models (LLMs) to improve the down-streaming tasks without the cost of fine-tuing the whole LLMs. Recent studies have shown how to effectively use PEFT for fine-tuning LLMs in ranking tasks with convincing performance; there are some limitations, including the learned prompt being fixed for different documents, overfitting to specific tasks, and low adaptation ability. In this paper, we introduce a query-dependent parameter efficient fine-tuning (Q-PEFT) approach for text reranking to leak the information of the true queries to LLMs and then make the generation of true queries from input documents much easier. Specifically, we utilize the query to extract the top-$k$ tokens from concatenated documents, serving as contextual clues. We further augment Q-PEFT by substituting the retrieval mechanism with a multi-head attention layer to achieve end-to-end training and cover all the tokens in the documents, guiding the LLMs to generate more document-specific synthetic queries, thereby further improving the reranking performance. Extensive experiments are conducted on four public datasets, demonstrating the effectiveness of our proposed approach.
4/15/2024
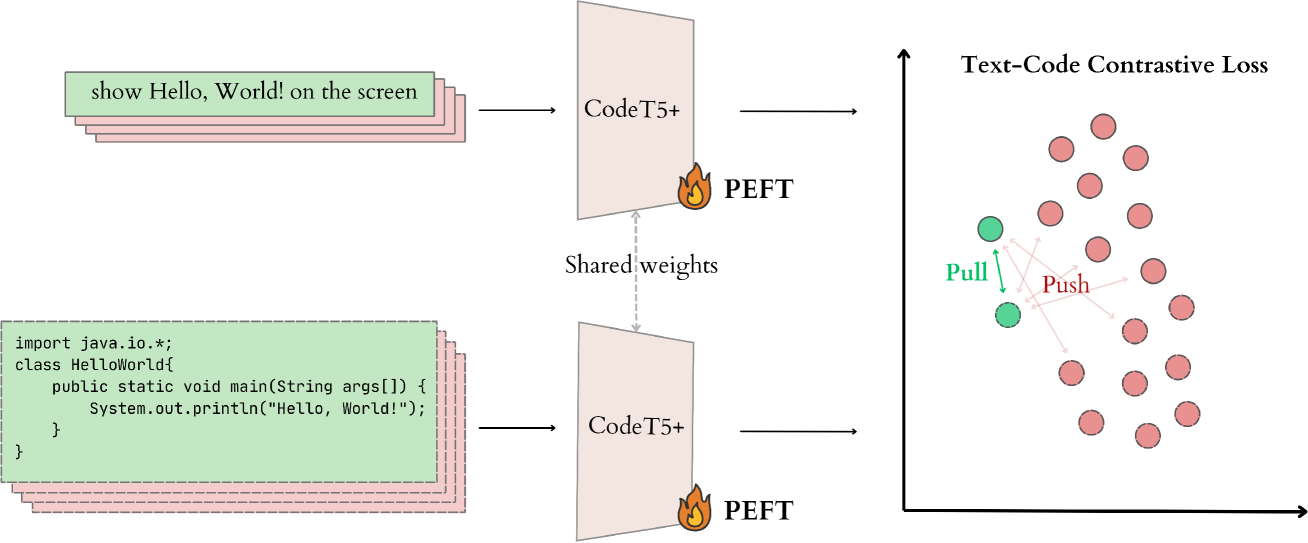
Refining Joint Text and Source Code Embeddings for Retrieval Task with Parameter-Efficient Fine-Tuning
Karim Galliamov, Leila Khaertdinova, Karina Denisova
0
0
The latest developments in Natural Language Processing (NLP) have demonstrated remarkable progress in a code-text retrieval problem. As the Transformer-based models used in this task continue to increase in size, the computational costs and time required for end-to-end fine-tuning become substantial. This poses a significant challenge for adapting and utilizing these models when computational resources are limited. Motivated by these concerns, we propose a fine-tuning framework that leverages Parameter-Efficient Fine-Tuning (PEFT) techniques. Moreover, we adopt contrastive learning objectives to improve the quality of bimodal representations learned by transformer models. Additionally, for PEFT methods we provide extensive benchmarking, the lack of which has been highlighted as a crucial problem in the literature. Based on the thorough experimentation with the CodeT5+ model conducted on two datasets, we demonstrate that the proposed fine-tuning framework has the potential to improve code-text retrieval performance by tuning only 0.4% parameters at most.
5/8/2024